 MongoDB中文社区
MongoDB中文社区
Abstraction
In order to gain better support for logic-clock and hybrid-logic-clock based distributed transaction, WiredTiger Introduced the timestamp transaction since version 3.0. We alias timestamp transaction with tsTxn for short in this article. In chapter 1, we will describe WiredTiger’s transaction strategy. In Chapter 2, we will introduce and prove an important property of wiredTiger’s transaction. In Chapter 3, we will introduce the design of tsTxn. In Chapter 4, we will show that beyond some restrictions, tsTxn shows a similar property as in chapter 2.
1. WiredTiger’s transaction strategy
Wiredtiger does conflict check in an optimistic way. In order to gain better throughput, wiredTiger does not use the first-commit-wins strategy for conflict-check. Instead, it uses the first-update-wins strategy. An open-source firstcommit-wins conflict-stragegy implementation can be found in RocksDB. RocksDB’s optimistic transaction suffers from mutex contention, and can not scale with more cores, because it uses the first-commit-wins strategy, conflictcheck and commit must be done in serialize[1].
Data is written into btree before the associated transaction commits. Per each key on a btree-page, there is an multi-view list linked against it. As shown in Figure 1, each list-node is a tuple of (TxnId, Value). The order of the list nodes will be discussed in chapter 2.
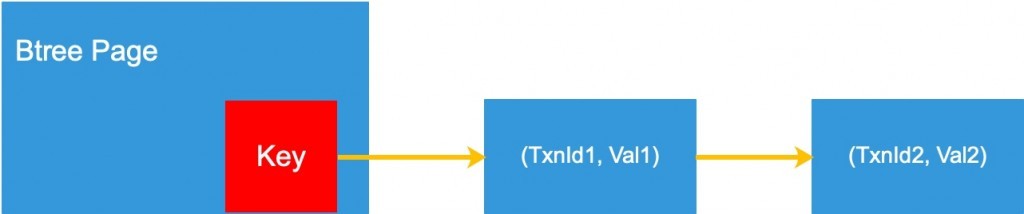
Figure 1
A global active(uncommitted) transaction list is maintained for conflict-check. In most senarios, conflict is a bi-direction relation, so wiredTiger uses a one-way conflict-check strategy and laterly we will describe it. In chapter 2, we will prove this strategy works correctly. Figure 2 shows the data structures essensially for discussion. Figure 3 shows the core procedure of wiredTiger’s basic transaction.
Transaction's localView
Transaction -> {
// Global monotonicly increasing id, allocated when transaction starts.
txnId: int
// The local view of the global transaction list.
snapshots: []int
// Key-Value pair, operations of this transaction.
mods: []{string, string}
}
One key's mvcc list in a inmem btree page
UpdateListNode -> {
txnId: int
newValue: []byte
next: *UpdateListNode
}
Global Transaction List
GTL -> {
// used for allocating one txn's txnId
txnIdAllocator: atomic
// uncommitted transactions
activeTxns: List<Transaction*>
// protect GTL from concurrent visit
rwlock: RwLock
}
Figure 2
Transaction's mvcc prodecure
1. Begin -> {
2. With(GTL.rwlock.wlock()) {
3. txn = Transaction {
4. txnId: GTL.txnIdAllocator++
5. snapshots: GTL.activeTxns.copy()
6. }
7. GTL.activeTxns.add(txn)
8. }
9. // txns are naturalled sorted in this way.
10. }
11. Update(key, value)-> {
12. // get the updatelist of a key from the btree
13. // pick its header
14. upd = GetUpdateList(key).header
15. if (upd.txnId > self.snapshots.back()) {
16. throw Conflict
17. }
18. if (txn.snapshots.find(upd.txnId) {
19. throw Conflict
20. }
21. GetUpdateList(key).insertAtFront({self.txnId, value})
22. }
23. Commit -> {
24. With(GTL.rwlock.wlock()) {
25. GTL.activeTxns.remove(self)
26. }
27. }
Figure 3
2. Correctness arguments
2.1 Transaction Procedure guarantees SI
As shown in Figure 3, wiredTiger uses first-update-wins strategy for conflict-check. So we discuss about a
transaction’s start-time and modification-time, which means the time it does a modification to a specific key. Figure 4 shows that txn1 starts at t0 and tries to do modification to the key at t1. Conflict should be thrown out iff some transaction has already modified the same key before t1 but not yet committed at t0. Figure 4 shows the only two possible situations. In (a), txn2 starts at t2 and modifies at t3, so at t0, txn2 must have not been committed, andtxn2 is in txn1’s snapshots. Figure 2, line 18 avoids this situation. Another situation is described in (b), txn2 starts at t4, and t4 is after t0, this situation can be well handled by Figure 2, line 15.
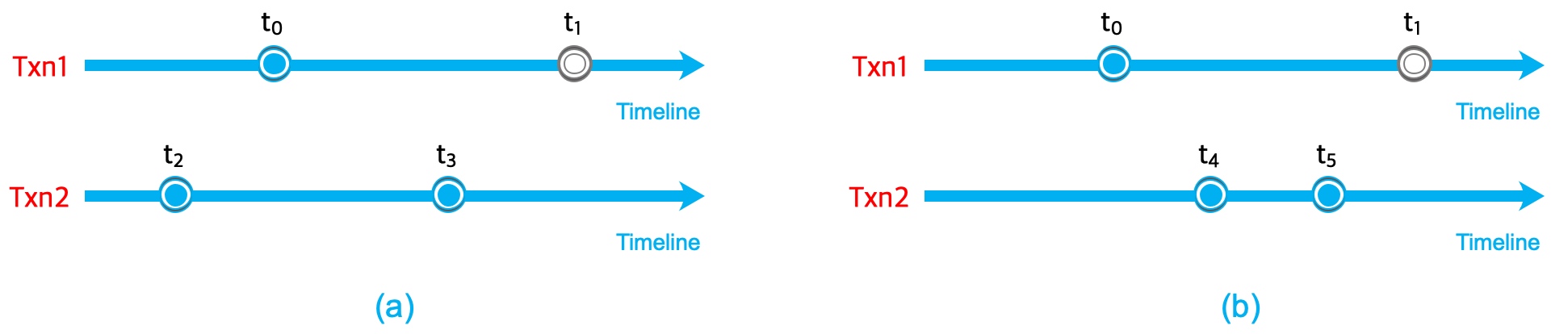
Figure 4
2.2 UpdateList is naturally arranged in txnId’s reverse order
As shown in Figure 3, line 21, A transaction adds its modification at the header of key’s update-list. As transactions makes modifications, the update-list will grow. How to evict the update-list is another topic and please refer to [2] for more details. It can be proved that the update-list is naturally arranged in txnId’s reverse order. Assume it’s wrong, as shown in Figure 5, txn 1 starts earler than txn 2 because it has a smaller txnId, txn 2 modifies earlier than txn 1 because it’s positioned behind txn 1 in the update-list. So the two transactions must have an overlap during their life time. So at most one of them can success, this is guaranteed by the difinition of SI and we have proved in 2.1 that the transaction prodecure guarantees SI. So in conclusion, updateList is naturally arranged in txnId’s reverse order.
Because txnId order is the same with a transaction’s start order, we can also say that the update-list is arranged in transactions’ begin order.

Figure 5
2.3To the same key, txnId order is the same as wallclock commit order
As proved in 2.2, to the same key, the update-list is arranged in txnId order, which is the same as transaction’s start order. In fact, to the same key, transaction’s start order is the same as its commit order. It’s because when a node is about to add at the list’s header, the existing nodes on the list must have been committed, Figure 3, line 18 guarantees this.
3. Introduction to WiredTiger’s tsTxn
WiredTiger introduced the tsTxn mechanism[3] since version 3.0. Distributed systems with hybrid-logic-clock can make good use of this functionality. An additional field named commitTimestamp is augmented into Transaction’s structure, as is show in Figure 6. The so called commitTimestamp is given by the upper-level application. To the same key, it provides a possibility to keep the wallclock commit-order the same as its given commitTimestamp.
Transaction -> {
// Global monotonicly increasing id, allocated when transaction starts.
txnId: int
// The given as-if comit time.
commitTimestamp: int
// The local view of the global transaction list.
snapshots: []int
// Key-Value pair, operations of this transaction.
mods: []{string, string}
}
Figure 6
In fact, wiredTiger does not guarantee data consistency unless the wall-clock commit order is the same as its commitTimestamp[4]. The restriction can be found in its manual. The main reason for this is because: when it’s violated, it will be quite complex to define and/or check data visibility within a time-travel read. However, as transactions run in parallel, how can upper-level applications guarantee transactions’ wall-clock commit order?
3.1 The Post-Begin-Monotonic-Allocation Strategy
We will introduce the PBMA strategy, which makes it possible for all tsTxns to run in parallel, but commit in commitTimestamp order.
1. // the global timestamp allocator
2. GTA -> {
3. lock Lock
4. globalTs int
5. }
6. // the timestamp allocation prodecure
7. Transaction txn
8. txn.Begin()
9. with(GTA.lock) {
10. txn.commitTimestamp = globalTs++
11. }
12. ......
13. txn.Commit()
Figure 7
4. To the same key, PBMA guarantees commitTimestamp order the same as txnId order
We’ve already proved in chapter 2 that if two transactions overlap in their lifetime and try to modify the same key, at most one can success. So will there be some situations that a transaction with a greater commitTimestamp starts and commits first, while a transaction with a smaller commitTimestamp starts and commits later, so that they have no overlap? The answer is still no. As shown in Figure 8, txn1 and txn2 have no overlap, txn2 is ealier than txn1 and txn2 has a greater commitTimestamp(=2) than txn1(commitTimetamp=1). This can’t happen, because Figure 7, line 9,10 guarantees that commitTimestamps are allocated within a lock, they should be monotonic relatively to the wallclock.
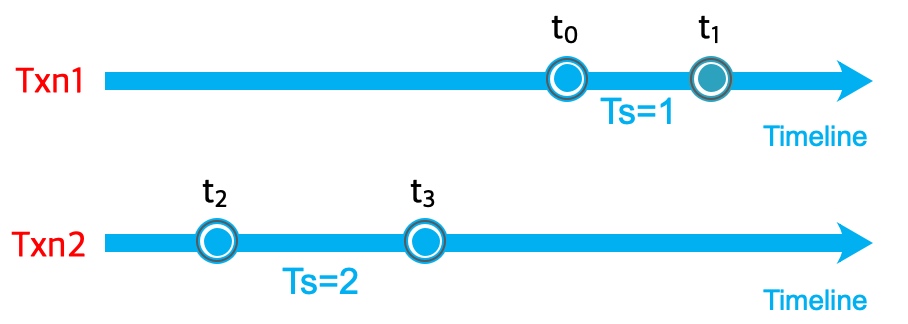
Figure 8
Until now, we’ve proved that with the PBMA strategy, to the same key, txnId order and commitTimestamp order should be the same. They both should be monotonic.
5. Conclusion
Q.E.D.
The property figured out in chapter 4 is quite important in modern T/O transactions. It provides an approach to mediate the application-level commit order and physical commit order, which is the basis for hlc-based distributed transactions.
References
1.rocksdb’s optimistic transaction suffers from mutex contention
2.https://source.wiredtiger.com/3.0.0/architecture.html
3.https://source.wiredtiger.com/3.0.0/transactions.html#transaction_timestamps



the global timestamp allocator
是真实存在的吗,还是在MongoDB中是用混合逻辑时钟来替代
孔德雨老师回复:这里描述的是wt单机事务,因此说的global timestamp allocator 是单机上面的global。 allocator的分布式混合是allocator的内部逻辑,与本文描述的概念没关系