 MongoDB中文社区
MongoDB中文社区
不管你使用的是什么数据库,都需要周期性地执行大量维护任务以保证系统的健康。同时,不管你使用的是什么数据库,在生产系统中的维护工作都是有风险的。因此,维护工作一般都是在预先安排好的宕机时间段执行:数据库处于离线状态,正常的业务操作被推迟。而这些时间对用户而言更加方便,但是对操作团队而言则并不是那么方便(例如:周末清晨)。
预先安排好的维护是一件痛苦的事情,如今的用户对于持续很久的宕机时间是无法忍受的。他们期望能够一直访问应用。你需要在保持系统运行的过程中进行升级的方法。开始考虑复制集和滚动维护。
你也许对复制集非常熟悉,因为这是MongoDB提供高可用性的机制,从而保证数据库能够快速从节点故障或者网络分区中快速恢复。此外,复制集也为你提供了在不影响数据库性能或者丢失可用性的情况下执行重量级的维护任务。通过在每个从节点上逐个执行维护,主节点永远都不会面临可用性的丢失或者性能的降低。这是滚动维护的关键之处。
整个操作就像是逐个将一批跑车搬到维修区。当某辆车在维修区时,队友继续在跑道上行驶,以保证永远不会出现跑道上没有任何一辆团队的车的情况。
每个节点的维护操作都是从首先在独立模式下重启该节点,执行维护任务(例如:构建索引、版本升级或者压缩等),最后一旦任务完成就在复制集模式中重启该进程。
你可以在mongo shell中使用下列命令关闭从节点:
replset:SECONDARY> db.adminCommand( "shutdown" )
在独立模式下重启该节点非常简单,只需要在重启时不使用复制集名字(replset)的命令行参数的情况下重启进程。或者如果你使用的是配置文件,从配置文件中删除复制集(replset)参数即可。
对复制集中的每个从节点重复这种模式,直到主节点成为最后一个没有执行维护的节点。此时,使用<code> rs.stepDown() </code> 来将主节点“降级到”从节点状态。一个新的主节点将会通过选举产生,而最后的维护任务将会在之前的主节点上执行。
为滚动维护准备
执行滚动维护非常方便,但是你也需要了解一些问题。你将需要制定一个计划,能够通过最小化人为错误、误配置以及不必要的可用性丢失来确保一个顺利可控的流程。你的维护计划应该覆盖以下四个领域:
- 操作日志大小的预检测
- 可预见地降级主节点
- 确保维护期间足够的可用性
- 谨慎一致地声明索引
预检测你的操作日志(Oplog)大小
MongoDB复制集系统的核心是一个循环、固定大小、被称为操作日志(Oplog)的集合。当主节点接收到一个写操作时,该写操作将会被记录到操作日志中。而从节点可以通过获取主节点操作日志中的每个操作并且在本机上执行这些操作来对主节点进行复制。
将操作日志想象成一个磁带环也许会对你的理解有所帮助。正如磁带环允许我们不用使用完磁带就可以连续记录,操作日志也允许一个复制集节点在不消耗连续增长磁盘大小的情况下不停地记录操作。正如循环的大小决定了为我们在它们开始重写自身时可以记录的多少,一个更大的操作日志在重写自身之前可以维护更多的操作。
如果一个节点发生故障或者网络分区临时中断,从节点将不能复制。这是可以接受的,因为从节点将会记录它找操作日志中的位置,一旦其重新连上,它可以马上跟上。然而。如果从节点在很长一段时间都是隔离的状态,主节点将会在操作日志中覆盖从节点的位置。这就是所谓的“从操作日志脱落”。而当这种情况发生时,从节点已经落后主节点太远了以至于不可能赶上主节点了。此时,从节点将需要一个完整的重新同步以保证和主节点一致。
执行滚动维护意味着我们将会从复制集中将从节点分离出来足够的时间,以运行压缩或者构建索引。由于这些操作是非常耗时的,我们需要确保主节点的操作日志足够大能够维护在从节点关闭期间发生的所有写操作。这就意味着:在描述操作日志的容量时,使用时间单位而不是它维护的真正数据量更加合适。在开始一个维护工作四千,我们需要检查操作日志中是否有足够的时间来完成从节点中的操作。我们可以通过在mongo shell中执行下列命令来检查操作日志中的时间长短:
foo:PRIMARY> rs.printReplicationInfo() configured oplog size: 192MB log length start to end: 897secs (0.25hrs) oplog first event time: Wed Jul 15 2015 13:21:10 GMT-0700 (PDT) oplog last event time: Wed Jul 15 2015 13:36:07 GMT-0700 (PDT) now: Wed Jul 15 2015 13:36:46 GMT-0700 (PDT)
操作日志的大小越大,你的从节点将会有更多时间来执行压缩和索引创建操作,而不会从操作日志中脱落。建议你的操作日志最少能够包括24小时的写操作。尽管一个压缩或者索引创建工作不大可能花费那么多时间,操作日志为各种类型的节点国产提供了一个安全保证。例如,数据中心可能会遭受网络错误、电力故障甚至是火灾,这些可能会造成节点与其它数据集成员隔离几个小时的情况。而24小时的最低限制能够为受影响的节点提供一个问题解决后追上主节点的机会。3到5天的操作日志是我们的用户经常使用的大小。
你可以通过使用一个特殊的滚动维护过程或者使用MongoDB的Cloud Manager来增大操作日志的大小。在管理集群时,Cloud Manager是一个特别有用的工具,因为它通过自动化简化了任务。稍后会有更多相关的介绍。
可预见地降级主节点
再继续我们的滚动维护,从一个从节点到下一个时,最终将会到主节点。我们希望能够优雅地将主节点降级,在停止mongod进程之前建主节点的状态转化到从节点。
在mongo shell中简单地使用rs.stepDown()命令就可以让主节点让出它的位置。下面是一个例子:
replset:PRIMARY> rs.stepDown() 2015-06-16T16:01:25.298-0400 I NETWORK DBClientCursor::init call() failed 2015-06-16T16:01:25.303-0400 E QUERY Error: error doing query: failed at DBQuery._exec (src/mongo/shell/query.js:83:36) at DBQuery.hasNext (src/mongo/shell/query.js:240:10) at DBCollection.findOne (src/mongo/shell/collection.js:187:19) at DB.runCommand (src/mongo/shell/db.js:58:41) at DB.adminCommand (src/mongo/shell/db.js:66:41) at Function.rs.stepDown (src/mongo/shell/utils.js:1001:43) at (shell):1:4 at src/mongo/shell/query.js:83 2015-06-16T16:01:25.305-0400 I NETWORK trying reconnect to 127.0.0.1:27017 (127.0.0.1) failed 2015-06-16T16:01:25.305-0400 I NETWORK reconnect 127.0.0.1:27017 (127.0.0.1) ok replset:SECONDARY>
注意mongod进程在是去它的主节点地位后掉线。这是我们期望看到的、非常正常的现象。掉线强制所有目前连接的客户端重新连接,然后刷新它们关于复制集状态的理解。这就避免了客户端错误地将写操作发送到先前的主节点上。
我们可以通过使用复制集配置中的优先级设置来控制那个从节点将会变成主节点。最高优先级的节点将会变成主节点,只要该配置文件是最新的。
例如,假设我们在多个数据中心上部署我们的复制集,在数据中心A上部署了2个节点,而在数据中心B上部署了1个节点。我们的应用服务器位于中心A,我们比较倾向于将主节点维持在数据中心A以最小化主节点和应用服务器之间的延迟。如果所有的节点都被配置为拥有相同的优先级,数据中心B中的节点就有可能被选举为主节点。当我们使用一个比数据中心B中节点更高的优先级配置数据中心A的节点时,我们可以保证在一个降级之后主节点能够在数据中心A中。
另外一个注意的地方,当你只一个复制集中对最高优先级的节点使用rs.stepDown()时,它将会让出主节点的位置然后维持没有重新获得主节点位置的资格6秒。在60秒之后,最高有效记得节点将会重新可被选为主节点,然后触发一个选举。如果由于一些原因,你不能在这60秒之内关闭服务器,最高优先级的节点也许再次会成为主节点。rs.stepDown()命令接收一个 ‘timeout’ 参数,你可以使用它来保证该高优先级的节点维持不能竞选主节点的状态一段特定的时间。例如使用下列命令:
replset:PRIMARY> rs.stepDown( 120 )
告诉主节点交出主节点位置,然后维持从节点状态不少于2分钟。
在维护过程中保证容错
从节点在独立模式下运行的时候它们不能作为一个集群的故障转移节点(Failover node)来使用。进行维护的从节点不属于当前的复制集成员,不能够提供原集群的任何故障处理支持。Ops团队需要为这种降低了可用性的集群做好心理准备。考虑下列复制集,由两个数据存储节点和一个仲裁节点配置。该复制集是一个容错非常完美的系统,但是也可以被看做一个最小化可用的部署。
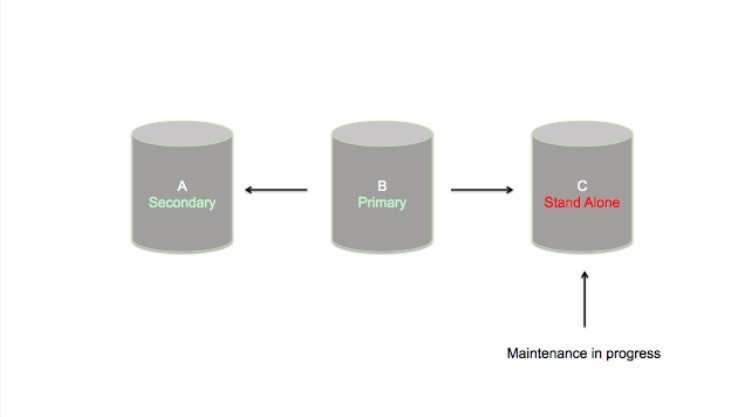
假设墨菲定理发生:当一个从节点已经处于独立模式,而另一个节点碰巧发生故障,复制集将会遭受复制集中大部分节点的丢失。在这种情况下,剩下的节点不能维护主节点状态,必须降级到从节点状态。

选举主节点的规则要求候选节点必须与复制集中大部分节点保持一个健康的交流。如果主节点不能维持与从节点的联系,就不得不假设该节点已被孤立,将不得不被降级。该规则避免了裂脑(split-brain)场景的发生:一个集合中错误地存在两个主节点。当3节点的复制集进行维护时,任何其它节点的丢失都会带来可用性的丢失。一个更大的复制集,例如5节点,将不会出现这个问题,因为该集合最多能够丢失2个节点,然后维护大多数。
对于只有3节点更小的复制集,考虑将目标从节点与一个临时的仲裁节点进行交换。该仲裁节点替换正在进行维护的从节点,将会维护选举主节点所要求的复制集大多数。这个交换操作包括在增加一个新仲裁者的同时从复制集中删除目标从节点,可以通过使用 一个简单的rs.reconfig() 命令完成。阅读文档了解更多信息。
构建索引时注意
记住:以滚动的方式构建索引时,你将会在每个节点上声明一个索引作为一系列相同的、但是也是完全独立的命令。在每个节点上谨慎一致地声明索引是非常重要的。在一个节点上声明节点非常容易,但是我们确实也遇到过用户无意中在键盘上失误输入命令而遇到问题的情况。以下列情况为例:
作为一个数据库管理员,我们想在 “test”集合中的 ‘a’ 字段上声明一个唯一索引。我将会以滚动的方式下列3节点的复制集中构建索引,以避免任何性能的丢失:

我通过在独立模式下重启节点C开始索引构建的进程,然后执行ensureIndex命令。
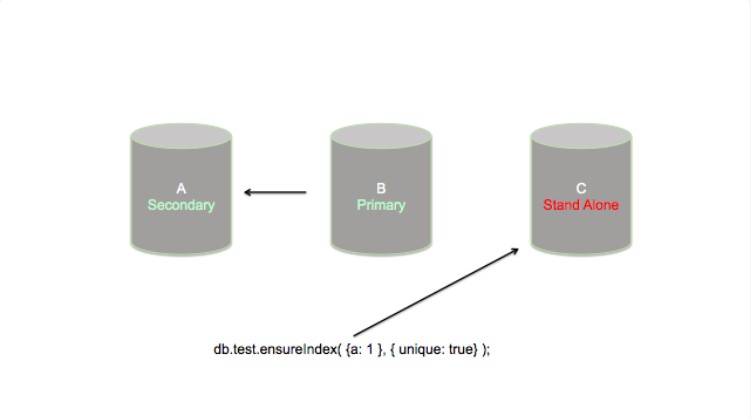
在节点C上的索引构建结束之后,我以复制集模式重启C,然后允许该节点与复制集保持同步。一旦节点C保持同步之后,我在节点A上重复该过程。然而,注意到我忘记使用唯一性约束来声明索引,这就意味着在节点A上将会允许重复的值,而节点C上则不会。这个问题也许在短期内不会很明显,但是麻烦来了。
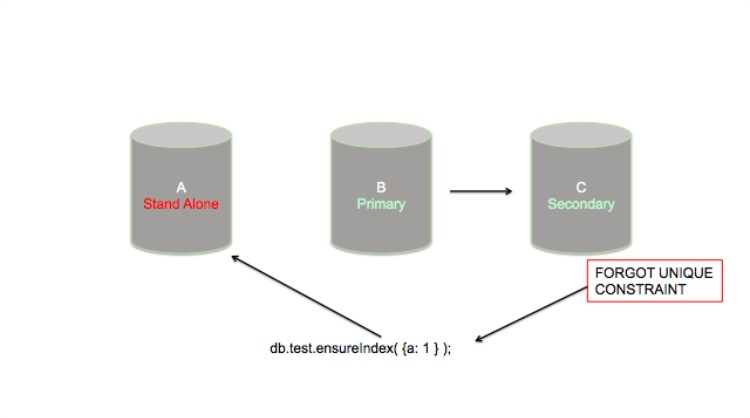
此时,我已经在复制集的2/3个节点上构建了我的索引。主节点是需要维护的最后一个节点。我对节点B使用一个rs.stepDown() 命令,使其让出主节点的位置。接着会进行一个选举,节点A变成了主节点。而节点B在独立模式下重启,然后最后的索引创建开始了。这一次,我并没有忘记唯一性约束。
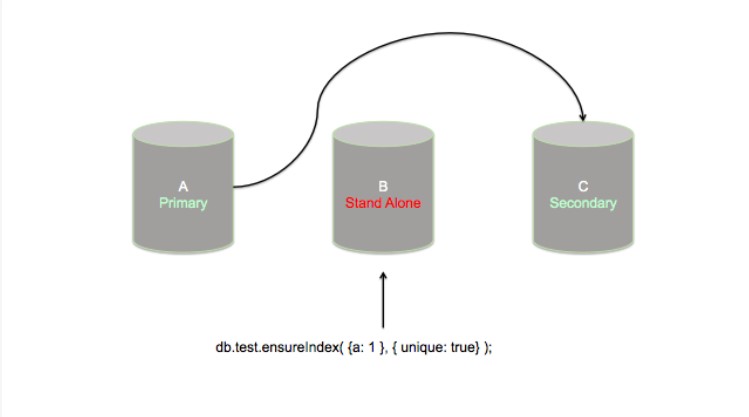
在这个时候,每个节点上都创建了索引。但是节点A上的索引缺少了唯一性约束。节点A也是复制集的主节点,因此它将会接受字段‘a’有重复的新文档的插入。而节点B和C上的索引着有唯一性约束,这将阻止它们接受重复插入。

从节点不能从主节点复制,将会在日志中记录下列错误并且自动关机:
E11000 duplicate key error index
一旦从节点关机,节点A将会成为复制集中最后一个正在运行的节点,并且补习让出它的主节点地位。节点A将会落回到从节点的状态。
这很明显是你不想让集群遇到的状态。为了从这种情形中恢复,节点A将不得不在节点B和C重启前关机。一旦B和C启动,主节点将会从2个中的1个中选举出来,而复制集的可用性将会恢复。然而,要对集群备份以及进行操作并不是你将遇到的最大问题。在节点A是主节点的时候,它将会进行不能够在节点B和C上复制的写操作。对这些写操作的处理应该完全依赖于你特定的用户案例以及数据的特性。但是,在任何情况下,都请一定要记住:这种情况可以也应该通过认真地声明索引来避免。
使用脚本可以帮助避免错误输入的索引生命。例如,下面的终端命令行可以在每个迭代的索引构建中使用:
$ mongo myDatabase –port 27018 –eval “db.myCollection.ensureIndex( { a: 1 }, { unique: true })”
它在命名空间myDatabase.myCollection中的‘a’字段上声明了一个新的唯一索引。我们已经使用过mongo shell的 –eval parameter 来将索引声明命令发送给节点。然而,我强烈推荐将该命令行放置到一个参数化的shell甲苯中,其中索引声明是静态代码。一个类似于下面案例的简单脚本避免了声明发生错误:
#! /bin/bash
if [ ! $# -eq 2 ]; then
echo “USAGE 2 parameters required: ‘hostname’ ‘port'”;
exit -1;
fi
$ mongo myDatabase –host $1 –port $2 –eval “db.myCollection.ensureIndex( { a: 1 }, { unique: true })”
请注意该脚本只是避免了索引声明发生错误,它并不会提供更多功能。我仍然需要确保在节点已经以独立模式重启之前不会使用完操作日志,以及不会不经意在主节点上执行索引声明。
简化你的工作
MongoDB Cloud Manager通过自动执行许多这些任务极大地降低了维护任务的复杂性。Cloud Manager已经支持了集群MongoDB版本的升级,以及集群中节点的自动添加或删除。索引构建已经在Cloud Manager未来发布版本的计划中了。Cloud Manager也集成了监控、警报、数据库备份以及恢复服务到一个简单易用的用户接口。Cloud Manager使得维护任务的执行变得容易,提高了执行以及降低人为错误的可能性。更多Cloud Manager的信息请查阅:https://www.mongodb.com/cloud?jmp=blog,你可以在这里注册申请一个为期30天的免费试用。
让它保持滚动即可
现在你知道了:滚动的维护将会解放你的周末,保持你的应用在线,使你的生活开心。只要记住有一个合适的计划,你就可以以最小的可用性损失以及高的执行来维护你的集群。下面有许多额外的信息以及学习资料可以帮助你实现你的维护计划。
请查阅在复制集上构建索引以了解更多细节。
请查阅在复制集上执行维护以了解额外细节。
如果你先了解更多如何在生产中运行MongoDB系统,请学习我们的高级操作课程:
关于作者– Bryan
Bryan Reinero是MongoDB的美国开发大使,主要负责推动社区的理解和参与。前期,Bryan是MongoDB的高级咨询工程师,帮助用户优化MongoDB的扩展和性能,也是一名MongoDB Java驱动的开发者。而在这之前,Bryan 是Valueclick的软件工程经理,负责搭建和管理用于广告、重定向、实时投标以及活动优化的大型市场应用。再之前,Bryan主要负责Ricoh 公司的嵌入式系统软件,并且在Ames研究中心的实验物理分支机构开发数据分析和信号处理软件。
翻译:周颖敏
审稿:TJ
本文译自:https://www.mongodb.com/blog/post/your-ultimate-guide-to-rolling-upgrades



?
图片均无法显示…………
图片都恢复好了