 MongoDB中文社区
MongoDB中文社区
许多人以分片集群的方式运行MongoDB服务器。 在这种配置下, mongos位于用户程序和分片数据之间, 用户连接mongos并给它发送查询, mongos将那些查询路由到一个或者多个分片上来完成查询动作。
在大多数情况下, mongos可以将某个查询精确定位到单一的分片上, 然而, 一些查询需要“分散-集合”的路由, 换句话说, mongos不得不将查询发送到所有的分片上,等待它们的响应,并且将它们整合成一个单独的master响应。我们可以将这些请求串行的放大到所有的分片, 但是这样一个慢的连接就会造成整个mongos系统的阻塞。 要有效的实现, 我们需要一个并发请求的方式。
考虑MongoDB 3.0 网络相关代码的实现结构, 唯一的实现并发执行请求的方式是在不同的线程里面执行请求。有些集群有数百个分片–这会有大量的请求放大, 你可以想象一下在mongos处理非常多的请求时会发生什么:线程爆炸!!有太多的线程会拖慢整个系统, 造成对硬件资源的争夺。
在MongoDb3.2, 我们写了另一种实现方式:对mongos的异步网络出站。这种新的网络层去除了我们的线程爆炸问题, 但是这个新的实现带来了内存管理的困难。 我们进行了大量的实验,失败,修复, 迭代, 最为重要的是强迫性测试来实现一套新的callback驱动的异步系统。
网络请求的生命周期
让我们将这个问题分解一下。假设我们要在另一个分片上面执行一个find命令, 这个请求在整个生命周期经历了好几个阶段。 首先, 我们打开一个远端主机的连接, 然后, 我们认证我们的连接,下一步, 我们发送find命令。一旦我们收到了相应, 该连接就完成了, 我们可以给调用方返回结果, 我们可能关闭连接, 也可能将连接加入连接池循环利用。
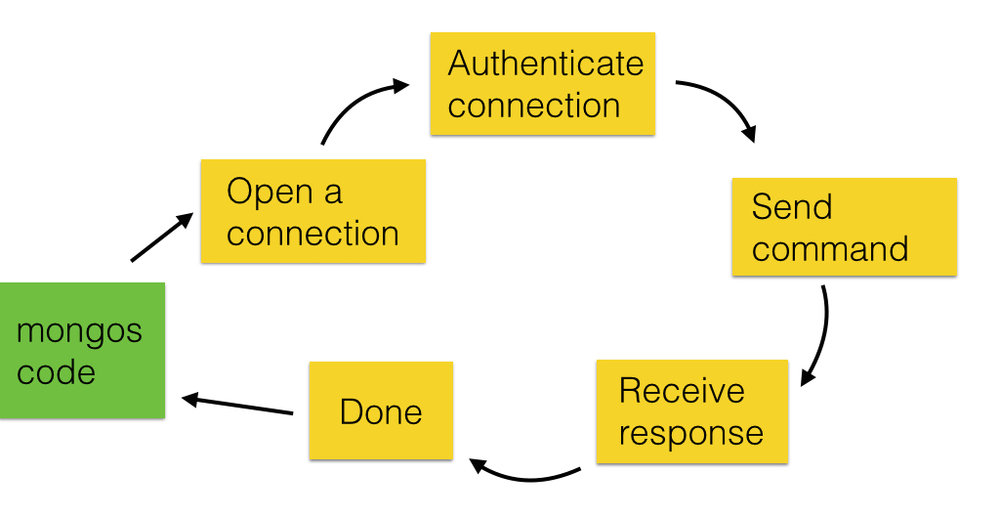
每一步都需要至少一个网络操作,有些, 就像认证, 需要好几个网络操作。 认证操作的握手最少需要两个完整的“主机-远端-返回”通信, 首先是接收端的nonce, 然后是真正的认证请求。
如果你的服务器相隔半个地球那么远, 这要花费一段时间!在一个mongos串行请求放大的情况下, 如果其中有一个交互是比较慢的, 它会阻塞住后面所有的排队的请求。
创建一个异步网络层
要实现这个目的第一件事是需要一些独立的线程。我们不需要几个mongos线程, 每一个连接一个线程, 来做调度和等待网络请求的工作, 相反, 我们可以把这个工作交给一个带有线程池的执行引擎来完成。该执行引擎维护了一个work item队列, 它使用线程池从任务队列中弹出任务并且运行。 标准的ASIO库提供了执行引擎和很多其它的原语来实现我们新的网络层。
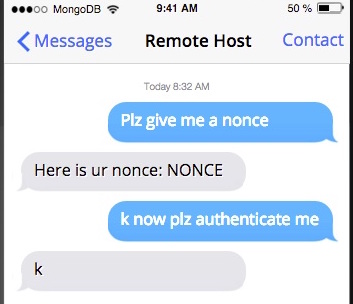
我们需要将我们的任务包装成小而简单的work item, 由执行引擎来运行。这意味着没有任务可以执行阻塞性的工作, 否则就会阻塞住整个引擎。因此, 我们想要开始一个异步的“已打开的连接”的任务并且立刻返回, 而不是打开一个socket并且等待连接。
我们可以把异步的”打开的连接“的逻辑打包成一个任务, 排队加入到执行引擎里面, 那么, 当“打开的连接”执行完成, 它可以加入下一个“请求nonce”的异步任务到引擎里面。类似的, 一旦我们请求一个nonce, 我们会把任务“get nonce”加入队列来接受远端主机的响应。
对每一个加入的任务都排队到执行引擎里, 我们按照这种方式处理。 因为每个任务是一个独立的执行单元, 执行引擎没有绑定到任何的请求或者连接,它可以并行的处理到不同主机的很多的请求。
当执行引擎最终在一个请求周期执行任务的时候, 它会在mongos触发callback, 这允许一个mongos线程获得响应并且开始给用户application生成响应。
事实上, 我们在两个线程池之间来回的发送请求,一个是为mongos的逻辑, 一个是为网络逻辑。在这个系统里, 我们可以有一个固定数目或者可以配置数目的线程, 而不是每一个连接一个线程。
让我们看一下在我们实现它的过程中我们碰到的几个技术挑战。
技术挑战 #1: 消失的状态
在我们开始深入研究状态是如何在我们鼻子下消失之前, 让我们看一下一些C++提供的特性来帮助我们实现callback驱动的系统。特别的, C++ lambdas是这个项目的重要部分。
Lambdas 任务包
lambda 是一个可调用的单元, 在C++, 它由三部分组成:捕获外部变量列表, 参数, 函数体。捕获外部变量列表在lambda初始化的时候给现存的变量做快照, 参数是在lambda被调用的时候传递的,在lambda被调用的时候, lambda 函数体被执行。
auto lambda = [capture list](parameters){
// body
};
lambda(); // runs body
让我们更加仔细的看一下捕获变量列表,下面的代码展示了lambda从外部环境捕获一个变量N, 并且在后面的代码打印N。
int N = 1;
auto print_number = [N](){
std::cout << N << std::endl;
};
print_number(); // prints “1”
lambdas通过传值或者通过引用能够捕获变量, 默认情况下, 它们通过传值捕获变量并且进行复制:
int N = 1;
auto print_number = [N](){
// We have our own copy of N
std::cout << N << std::endl;
};
N = 123456;
print_number(); // still prints “1”
当lambdas通过引用捕获变量的时候, 它们会使用原本的变量, 而不是复制:
int N = 1;
auto print_number = [&N](){
// Now, we use the original N
std::cout << N << std::endl;
};
N = 123456;
print_number(); // prints “123456”
如果我们采用引用外部变量, 我们可以避免代价昂贵的变量复制。另外, 复制一些对象是没有意义的, 我们需要原本的变量。考虑一个Timer类, 它记录了自从构造函数之后的时间。 要获得一个可靠的时间, 我们需要一个指向到原本Timer对象的引用, 而不是一份复制。Timers可能甚至不允许复制它们自己, 因为复制出来的Timer对象能够干什么哪?复制的Timer应该从0:00开始吗? 还是它应该从原本的Timer经过一段时间后开始计时哪?这两者可能存在争议。
回到网络连接上, 打开一个连接是很慢的, 正如我们讨论过的, 因此我们尝试用lambda写一个异步的open_connection()方法:
void open_connection(Command cmd) {
tcp::socket sock(_engine);
// pass a lambda to async_connect
async_connect(sock,[cmd](error_code err) {
if (!err) {
authenticate(sock, cmd);
}
});
return;
}
这里, 我们调用async_connect()函数, 它的第一个参数是socket, 第二个参数是lambda。 当它被调用的时候, 这个lambda函数首先检查网络错误, 然后开始下一个任务, authentication().
async_connect()函数在网络操作完成的时候会调用lambda: 如果我们的服务器相距很近这会很快完成, 或者它们相距很远就没有那么快。我们无法知道什么时候lambda会被调用, 同时, open_connection()会立刻返回, 这是好的。但是说如果我们想确切的直达async_connection()花费了多长时间?假设我们使用上面描述的Timer类, 我们不能复制它, 因此我们会通过引用获得timer:
void open_connection(Command cmd) {
tcp::socket sock(_engine)
Timer timer; // starts timing now
async_connect(sock,[&timer, cmd](error_code err) {
std::cout << timer.secs() << “ seconds” << std::endl;
if (!err) {
authenticate(sock, cmd);
}
});
return;
}
这是有问题的, 事实上, 我们手头上有个大麻烦。lambda函数给async_connect()传递一个Timer的引用,我们不知道什么时候lambda函数会被执行, 但是我们明确的知道它不会马上执行。但是open_connection()会立刻返回, 并且当它返回的时候它的stack会消失, 我们的Timer对象创建在stack上面!
如有一个引用变量指向一个清理掉的变量, lambda会如何哪? 当然是发生段错误。
我们需要保证每一个异步任务都打包了必要的状态。对于不能干净的复制和打包的东西, 我们要确保引用状态比任务有更长的生命周期。
我们有两个方式来保持这样的存活状态。
方法A: 在一个持久化结构里面保存状态
我们的第一个选择是保存我们的状态到stack之外的地方, 我们可以维护一个Timer对象的vector, 每一个command保留一个这样的Timer。 这样, 每个运行的命令在完成过程中可以引用存储的Timer对象。
这种方法很好因为我们能够控制Timer对象以及它们的生命周期, 它们从来不会被悄悄清理掉因为是我们负责清理它们。
缺点也是清楚的:我们需要负责清理Timer对象。 这需要我们付出我们不想要的额外的负担, 并且我们还必须去做正确。
方法 B: 使用C++的shared_ptr来保证状态存活
我们另外一个可选方案是使用C++ shared_ptr. shared_ptr看起来并且使用起来很像普通的指针, 除了它保存了一个引用计数来记录正在使用该指针的用户个数。 shared_ptr指针指向的对象存活会一直保存, 直到所有的用户都释放该指针。
我们可以使用shared_ptr引入到lambda, 而不是使用Timer的引用, 我们会保证Timer对象不会被清理直到lambda使用完该对象。Timer对象会从一个任务转移到另一个任务, 直到整个命令结束, 它被释放掉。

使用shared_ptr也有它的优缺点, 一个最重要的有点事它的实现非常的简单:不需要维护我们的Timer对象集合。
但是, 因为我们将Timer对象的控制权让给了C++, 我们不能够假定它们的生命周期。它们不是被我们清理的, 我们无法确认某个时间点它们是否还在。过渡使用shared_ptr会导致令人讨厌的并且难以检测的bug。可以从这篇博文获得有趣的, 推荐的阅读材料。在这条道路上, 我们必须小心行事。
两种方法的故事
对于MongoDB的网络层, 没有一个适用于所有情况的方法,在一些状况下, 使用持久化结构更合理, 对于其它的状况, shared_ptr是更加简洁, 安全的方法。我们采用混合的方式使用两种方法。
技术挑战 #2: 消失的状态 (又一次!)
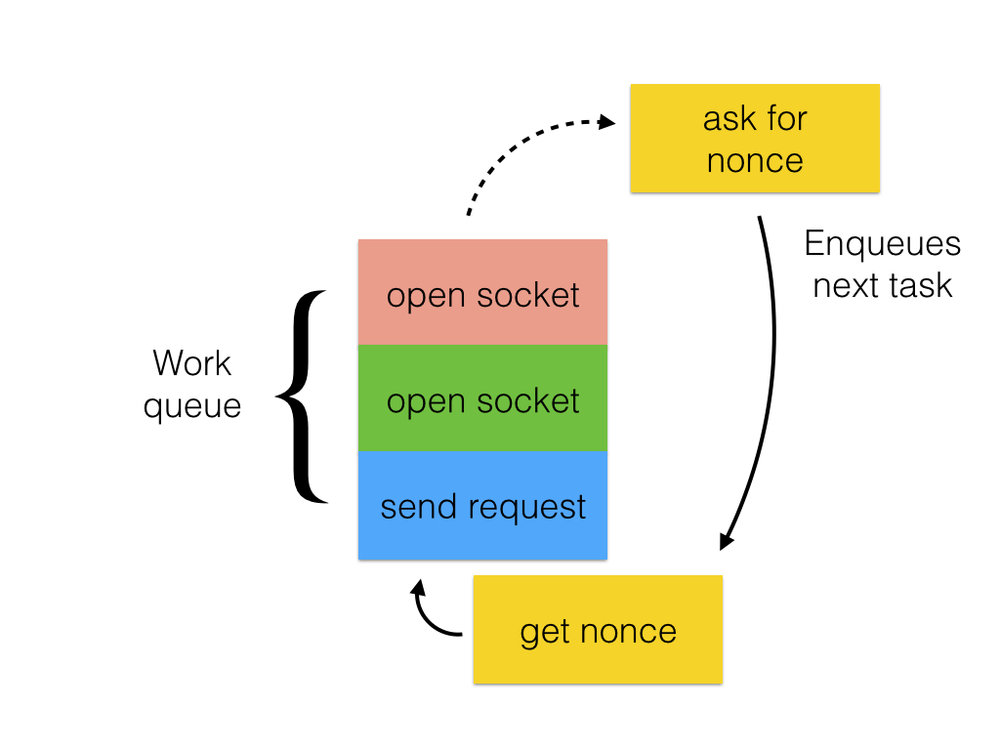
我之前给的图片忽略了abort退出, 但是有几种方式可以在完成之前缩短请求的生命周期, 这会增加失去状态的机会, 比如说发送命令的时候遇到网络错误, 在这种情况下, 继续努力和远端服务器通信是没有意义的, 远端服务器是无法到达的, 我们提前退出状态机, 清理掉传递过来的在heap上面分配的状态(如下描述):

这很好, 因为网络错误发生在我调用的primary执行路径上, 这条路径在上面用蓝色的点线显示。primary执行路径是在任务的每个阶段的lambda函数体里。 在这里我们能接受网络错误并且决定是否将下一个任务添加到调用链里面。
一个网络请求也可以被mongos线程取消, 比如说, mongos正在运行一个限制返回5个记录的find命令,如果我们已经从一个分片上面收到了5条记录, 我们可能会发出取消其他分片的请求。

我们第一种删除方法是从mongos线程强制性的删除操作, mongos线程会清理一些状态, 把操作标记为已删除, 就是这样!
除了它, 不是这样的。 mongos线程在secondary执行路径上运行, 如上图的红色实线所示。如果“发送命令”任务, 一个在primary路径上的lambda, 已经在运行或者加入引擎队列, 它无法知道该操作已经被停止, 当该任务完成, 它会尝试后续的状态机:

这是不好的, 正如你猜测的一样。比如, 内存里的状态有可能已经被另一个操作重用了。
一条路径适用所有情况
为了避免这些意外, 我们强制执行一条规则:只有primary执行路径才能够结束一个任务, 因为只有primary路径才有操作的上下文。
我们首先通过在操作里保存一个简单的cancelled 标记来实现它。
// Basic “network operation” class
class NetworkOp {
bool cancelled;
}
// Secondary path
cancel(NetworkOp *op) {
op->cancelled = true;
}
// Primary path
if (op->cancelled) {
done(op);
}
当在secondary路径的mongos线程要取消操作, 它可以简单的通过将cancelled设定为true来发送一个取消请求。 在执行的时候, Primary路径会检查cancelled标志, 如果有取消的请求,primary将它自己取消。这就是说, 实际的取消操作发生在primary路径, 而不是secondary路径。

这个实现更好一些, 但是它仍然有问题。想象一下, mongos 线程等待直到可能最后一刻primary路径才清理自己取消一个操作, 这些路径是相互独立的线程在运行, 因此它们可能并行的发生。如果在取消操作执行到之前操作已经完成, 取消读作需要的状态可能已经被清理了, 这很危险!

看下面的代码很明显的我们在引发一个段错误:
// Secondary path
cancel(NetworkOp *op) {
// op could be a null pointer!
op->cancelled = true;
}
保持锁定,保持安全
我们需要保护我们的共享状态, 它可以通过mutex来实现。但是mutex应该放在哪里?我们不能将它放在NetworkOp类里面。很像上面的Timer对象, mutex必须保存在独立于操作的持久化结构里面, 但是我们手上有有很多的问题:谁负责清理持久化对象?
考虑到这个问题的特性, shared_ptr是更好的解决方法, 我们设计了一个结构体, 叫做SafeOp, 它保存了一个mutex和NetworkOp*:
// “network operation” class
class NetworkOp {
bool cancelled;
}
// "access control" object
class SafeOp {
mutex lock;
NetworkOp* op;
}
不是处理NetworkOp的裸指针, 两种路径都拥有指向SafeOp对象的指针, 双方都达成一致:除非第一个锁定SafeOp的mutex, 它们不会访问或者修改NetworkOp。
// Primary path
done(shared_ptr safe) {
// lock before
// cleanup
safe->lock.lock();
safe->op->done();
safe->op = NULL;
safe.unlock();
}
// Secondary path
cancel(shared_ptr safe) {
// once we lock, can't
// change under us
safe->lock.lock();
if (safe->op) {
safe->op->cancelled =
true;
}
safe->lock.unlock();
}
用这种方法, 我们有要防止有问题的场景并且得到我们想要的准确的语义:
实现, 测试, 重复
它花费了好几个小时的汗水、眼泪和头疼, 并且这通常在软件开发中常见的情况, 我们第一个尝试通常不是最佳的实现, 我们不得不迭代, 迭代, 段错误, 重复迭代,并且, 测试,测试, 测试!当开发一些新的且复杂的项目, 就像这个项目, 我们需要失败尽快返回,其通常可能产生最好的产品。 我们写了很多层级的测试用例(单元俄式, 继承测试, 压力测试等等)来向上、向下和侧向测试网络层。
因此我们如何详细地测试我们新的callback驱动的, 异步网络系统?那是其他时间点的一个话题。
原文链接:
https://engineering.mongodb.com/post/building-an-async-networking-layer-for-mongos



评论前必须登录!
注册