 MongoDB中文社区
MongoDB中文社区

本文为2020年MongoDB应用案例与解决方案征集活动优秀应用案例:MongoDB在七牛云的应用,作者李鑫。
本文基于MongoDB 3.4/3.6版本描述,主要剖析在万亿级文档/百万级chunks场景下,路由管理模块对数据库操作的影响以及源码级优化思路。
现状
MongoDB的路由组织
MongoDB Sharding的数据组织形式为逻辑上是Chunk,将全局key分散到多个Chunk上,数据的迁移、平衡的单元就是一个Chunk。物理上是Shard(Mongod进程)。一个Shard就是一个Mongod进程,每个Shard存放多个Chunk数据。MongoDBSharding通过一个角色为Configsvr的副本集管理整个Sharding集群。通过Mongos代理,将client请求拆分,转发到指定Shard。
Chunks信息(查看config库的chunks collection):

Lastmod:第一部分是major version,一次movechunk命令操作(Chunk从一个Shard迁移到另一个Shard)会加1;第二个数字是Minor Version,一次split命令操作会加1。
Min:该Chunk管理的最小值,闭区间
Max:该Chunk管理的最大值,开区间
MongoDB的路由使用
对于每一个collection,mongos会有一个全局变量ChunkManager(chunk_manager.h中),用来存放该collection的路由信息用图形描述数据结构,格式如下图:

ChunkMap:key为每一个Chunk的max值,value为Chunk的详细信息,包括:min,max,version(lastmod),lastmodEpoch(collection创建时生成的,在collection删除前不会变化),Shard等信息
ShardVersionMap:key为Shard名称,value为version,记录每个Shard的当前version
ChunkRangeMap:可以忽略,是个优化,不影响逻辑。
路由模块的使用
Mongos对于每一个client链接,第一次对collection进行操作时,会获取全局的ChunkManager镜像,保存ChunkManager镜像为缓存,记做cm,后续这个链接再访问collection的时候,直接使用cm进行路由信息的查询。
根据client发来的请求,将请求条件通过cm的ChunkMap查询到到这个请求需要转发给哪些Shard,进而进行转发。
MongoDB的路由变更
MongoSharding的balance通过movechunk命令,将一个chunk的数据从一个Shard迁移到另一个Shard,数据迁移完成后,修改Chunk的Lastmod。但是mongos作为无状态的proxy,是不会知道chunk的迁移过程和状态的,所以,mongos中的路由信息相对shard/configsvr进程是有延迟的,mongos感知路由变化的流程如下图:
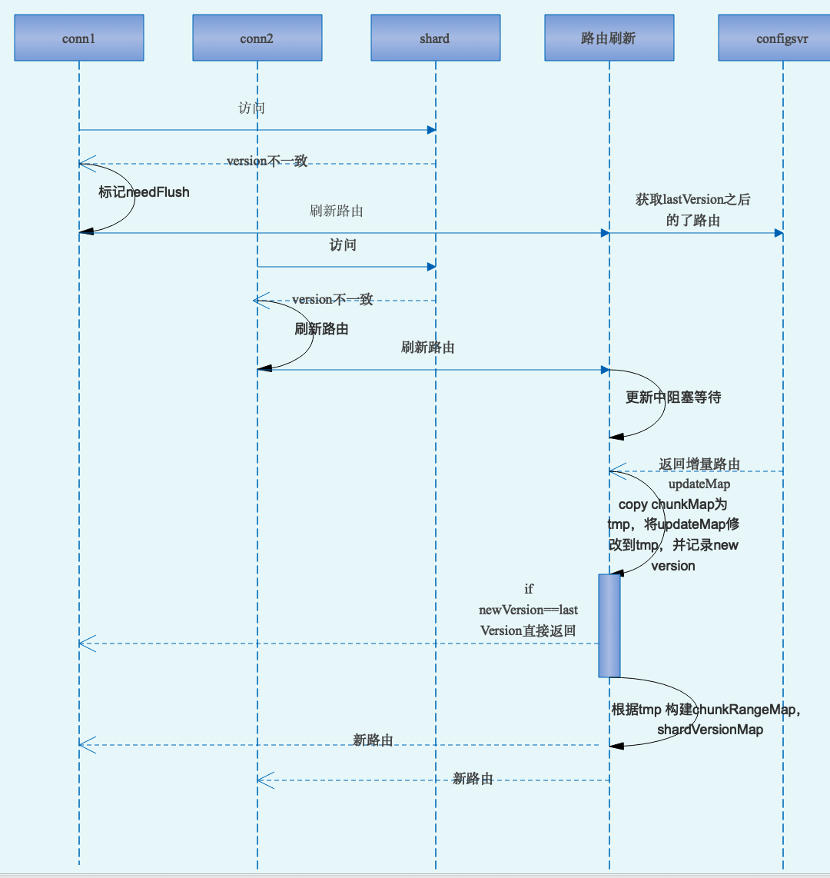
- mongos访问mongod,version不一致,mongod返回错误信息(shard version not ok)给mongos,路由需要刷新
- 加锁,根据本mongos的LastVersion,查询Configsvr,获取LastVersion之后(大于等于)的变更信息。这时候其他的请求也可能触发上面的加锁刷路由流程,只需要等待就ok,不会多次请求Configsvr
- Configsvr返回LastVersion之后增量变更记作UpdateMap。Mongos将当前的ChunkManager中ChunkMap进行拷贝,然后将UpdateMap中涉及的Chunk从ChunkMap中删除并替换为UpdateMap中的信息。最后,再根据ChunkMap,构建新的ShardVersionMap,生成新的ChunkManager,替代原来的ChunkMap。
从上面的流程中可以看到:
- 每一个访问到路由变更的Shard的请求,都会因为mongos带到Shard的ShardVersion和Shard中的不一致,而进行路由刷新
- 路由刷新过程加锁,避免多次并行更新
- 路由刷新过程涉及一次ChunkMap拷贝,一次ChunkMap遍历构建ShardVersionMap。
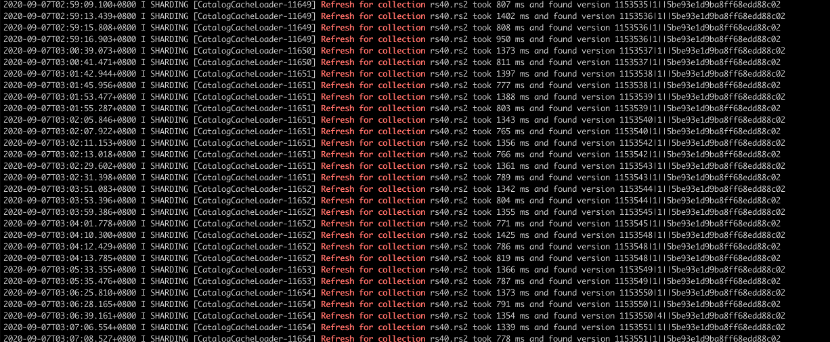
由于以上3条,当Chunks数量比较大的时候,拷贝和遍历都会耗时较久,同时以为必须等待路由刷新,才能访问到正确的shard,请求必然需要阻塞等待路由刷新。根据我们的使用情况,100w的Chunks,整个路由刷新过程大概在1s左右,也就是发生了movechunk,mongos层至少就会有秒级别的卡顿。同时,mongod发生movechunk,也要经过一次路由刷新,刷完后才能识别出mongos的version旧了,所以这里耗时也基本是是1s。于是,业务侧观察就会发现,在movechunk发生时,经常会有批量的请求超时。下图我们仅截取了mongos中路由刷新耗时情况:
优化思路
从上面的分析可以看出,卡顿阻塞主要是因为ChunkMap拷贝和遍历构建ShardVersiorMap造成的,加快这个速度,就是解决MongoDB Sharding路由刷新造成的卡顿的根本方向。
一. 官方的优化
Mongo3.4/3.6版本ChunkMap使用BSONObjIndexedMap,这个数据结构的性能不够好。既然BSONObjIndexedMap速度不够快,那么提供更快的数据结构,就可以优化这种情况。官方从3.7.1版本使用std::map替代BSONObjIndexedMap,提供更高的查询性能,来优化这个问题。根据实际测试,std::map的查询性能比BSONObjIndexedMap高出20%-30%,在一定程度上缓解这个问题。
但是对于百万级的chunks来说,耗时在1s+,优化的20%的耗时不解决根本问题。同时随着集群持续扩大,chunks数量继续增加,这里的优化杯水车薪。
二.加锁修改
BSONObjIndexedMap的拷贝和遍历,本质上是因为mongo中路由信息使用了copy and update的思路,这种方式的好处是普通的访问都是只读,不需要加锁;但是如果通过加锁的方式,将长尾的大耗时平均到每次请求,降低波动,也是可以接受的。这个方式我们尝试实现了,但是发现了非常大的缺陷:
- 加锁,吞吐下降50%,延迟升高100%;
- 一些命令会发生shard和version不一致的情况,主要原因为:原来chunk_manager是只读镜像,所以,获取shard和获取version可以分开操作,一定是一致的;但是改成加锁的方案,每次的修改就是在全局ChunkManager原地修改,就会导致,获取shard和获取version(两个接口)不是原子性的,不一致的问题。这样要修改的话,就必须在所有调用获取请求应该转发的shard的地方增加原子获取version的接口,如果在不同的函数,还需要考虑version传递。这就导致修改没有办法在chunk_manager模块内部收敛,风险难以控制。
还有一些其他问题,这里不在细说,总之,这个方案增加了风险且对性能有巨大影响。
三.多级索引
拷贝ChunkMap和构建ShardVersionMap的速度提高至少要有2个量级的优化才比较有意义,但是没有数据结构能够达到这种需求,那么就考虑减少每次拷贝的数量。
将ChunkMap拆分成多个小的ChunkMap。路由刷新时,找到特定的小的ChunkMap,将小ChunkMap做拷贝+修改,就可以控制每次拷贝的耗时。修改后的结构图如下:
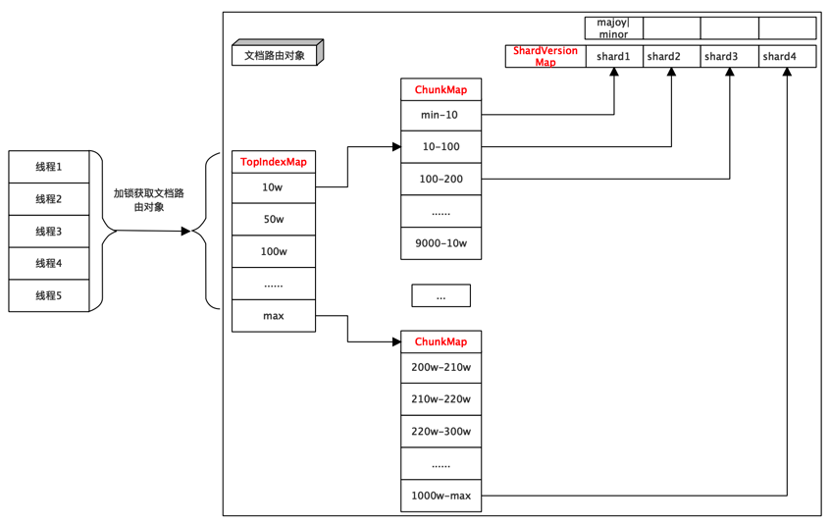
新增TopIndexMap,做一级索引,结构为:map<string,shard_ptr<ChunkMap>>.其中TopIndexMap的key是value中存放的的ChunkMap的最大值(开区间)。查找时先在TopIndexMap中找到指定的ChunkMap,然后再在ChunkMap中找到chunk信息。
路由刷新时,创建一个新的“文档路由对象”记做new。将old的TopIndexMap拷贝到new(TopIndexMap规模可控在千级别),因为TopIndexMap的value都是存放的shard_ptr,所以整个拷贝过程就是TopIndexMap中的key+value的拷贝,不会对shard_
ptr内容拷贝。然后在根据变更的chunk,找到指定的需要修改的chunkMap,将old中的chunkMap拷贝一份,修改,再替换回去。这样没有变更的chunkMap没有拷贝操作。
优化后的效果:
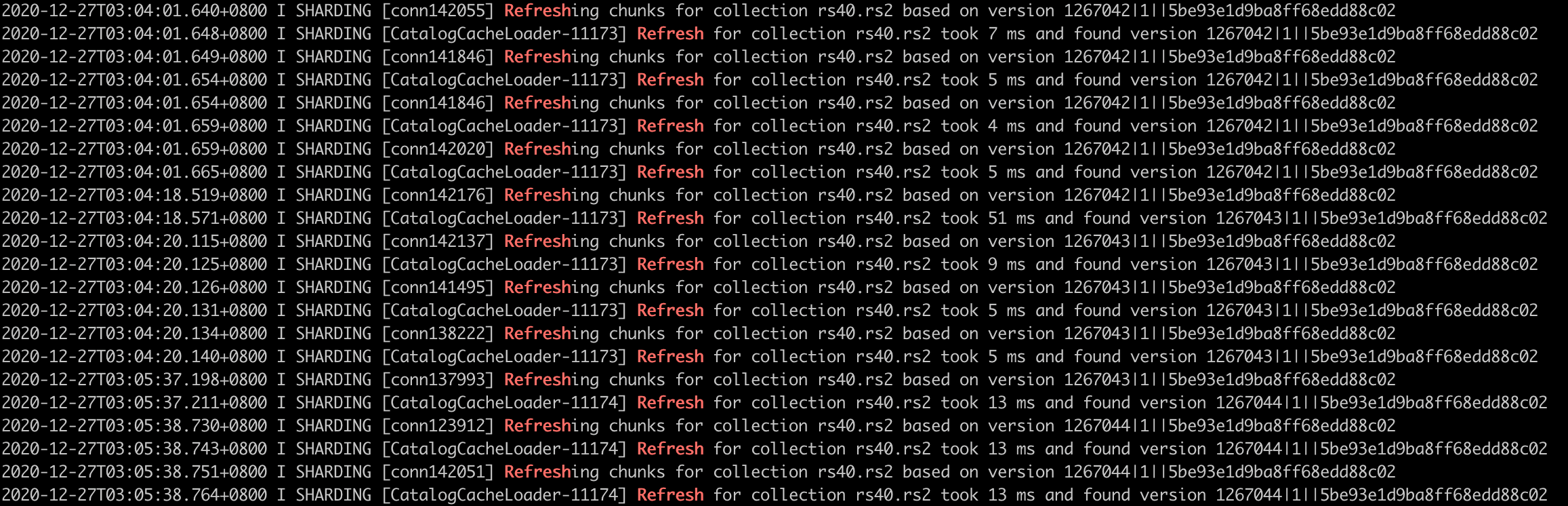
Refresh的耗时控制在10ms级别。
后续
多级路由方案缺陷
原来的方案是每次路由Refresh都会重建,多级路由方案是根据变更修改。所以,要解决这个问题,应该在一个shard的所有chunk都迁移走后,在config.chunks中增加一个虚拟的操作,让路由Refresh时能够触发将这个shard从ShardVersionMap中删除。因为我们的场景不需要缩容,所以这个工作还没有做。
作者介绍:
李鑫,七牛云技术专家。现负责七牛云元数据系统、万亿级文档数据库MongoDB开发维护。曾就职滴滴出行,蘑菇街,海康威视。多年分布式数据库领域设计及开发经验。曾参多个 NoSQL/NewSQL/时序数据库设计及开发工作。
2020最佳创新案例获得者:徐靖
2020优秀应用案例获得者:李鑫 张爱强 王勇 马天艺
应用案例来自:圆通速递,七牛云,平安科技,京东,以及不便分享的神秘伙伴
更多案例请期待后期分享!
2020MongoDB中文社区线上年终大会
感谢社区合作伙伴上海锦木信息技术有限公司和深圳钛铂数据有限公司对本次案例征集活动的大力支持!
上海锦木信息技术有限公司是国内领先的 MongoDB数据库服务提供商,是 MongoDB厂商官方合作伙伴。锦木信息始终坚守在数据技术领域扎实地实昽和前行,成为国内 MongoDB领域的新兴技术力量。服务的客户广泛分布于金融、电信、零售、航空等行业,助力用户完成从传统IT架构向互联网架构的顺利转型。
上海锦木信息技术有限公司http://www.jinmuinfo.com/
Tapdata,是基于MongoDB 的实时ETL及数据服务平台工具。我们的产品能够帮助那些缺乏专业数据工程师的企业提供产品化的数据解决方案。实时双向的数据同步+简单的数据治理及建模+无代码API服务式交付+百TB级亚秒级的性能,无论您是为您客户构建数据统一平台,还是构建一个横跨BU的企业级数据中台,Tapdata都可以为你提供低成本快速落地的一个有效技术方案。



感谢分享。 『从上面的分析可以看出,卡顿阻塞主要是因为ChunkMap拷贝和遍历构建ShardVersiorMap造成的』,这个说法挺突然的。并没有体现出是它们造成的,如果要体现,应该用某种形式的 profiling 显示证明才好。
排查问题时给这部分操作做了计时,明确后就去掉了
由于不同版本可能因为bug 导致性能相差大,所以可能强调一下方案所作用于的版本为好。官方路由bug 可通过这种方式来查找到。https://jira.mongodb.org/browse/SERVER-51885?jql=project%20%3D%20SERVER%20AND%20issueFunction%20in%20issueFieldMatch(%22%20%22%2C%20fixVersions%2C%20%223.6.*%22)%20AND%20type%20%3D%20Bug%20AND%20(summary%20~%20migrat%20OR%20summary%20~%20chunk%20OR%20summary%20~%20balance)%20ORDER%20BY%20cf%5B13550%5D%20ASC
这个不认为是bug 而是认为设计原因 考虑方案时就没有考虑chunks数量特别多的场景。