 MongoDB中文社区
MongoDB中文社区

全民K歌后台开发一组/腾讯MongoDB团队
全民K歌作为腾讯音乐集团四大产品线之一,月活超过1.5亿,并不断推出新的音娱功能及新玩法,极大丰富了数亿用户的音乐娱乐活动。
本文主要分享K歌技术演进过程中的一些踩坑过程、方案设计、性能优化等,主要包括以下技术点:
- 全民K歌业务特性
- Feed业务读写选型
- Feed数据吐出控制策略优化
- Feed核心表设计
- K歌业务层面踩坑及优化过程
- K歌业务MongoDB使用踩坑及优化
第一章:业务层面优化过程
每一个社交产品,都离不开Feed流设计,在全民K歌的场景,需要解决以下主要问题:
- 我们有一些千w粉丝,百万粉丝的用户,存在关系链扩散的性能挑战
- Feed业务种类繁多,有复杂的业务策略来控制保证重要的Feed曝光
对于Feed流的数据吐出,有种类繁多的控制策略,通过这些不同的控制策略来实现不通功能:
- 大v曝光频控,避免刷流量的行为
- 好友共同发布了一些互动玩法的Feed,进行合并,避免刷屏
- 支持不同分类Feed的检索
- 安全问题需要过滤掉的用户Feed
- 推荐实时插流/混排
- 低质量的Feed,系统自动发类型的Feed做曝光频控
2.读写选型
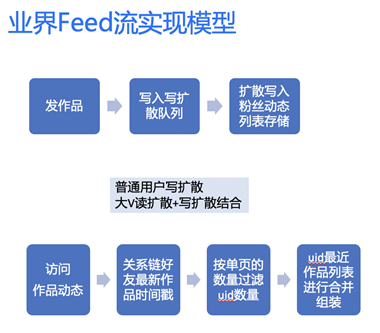
Feed主流实现模型主要分为3种,这些模型在业界都有大型产品在用:
- 读扩散 (QQ空间)
- 写扩散 (微信朋友圈)
- 大v读扩散+普通用户写扩散(新浪微博)
没有最好的模式,只有适合的架构,主要是权衡自己的业务模型,读写比,以及历史包袱和实现成本。
K歌使用的是读扩散模型,使用读扩散模型的考虑如下:
- 存在不少千万/百万粉丝的大v,写扩散严重,推送延迟高,同时存储成本会高
- 低活用户,流失用户推送浪费计算资源和存储资源
- 安全合规相关的审核会引发大量写扩散
- 写扩散qps=3 x 读扩散qps
- K歌关系链导入的历史原因,早起写扩散成本高,同时后期改成读写扩散混合的模式改造成本大
但是读扩散模式存在以下比较明显的缺点:
- 翻页把时间线前面的所有数据拉出来,性能开销越来越大,性能越来越差
- 关注+好友数量可达万级别,实现全局的过滤,插流,合并,频控策略复杂,性能不足
3.读扩散优化
读扩散模型的存储数据主要分为3大块:
- 关系链
- Feed数据
- 最新更新时间戳
3.1.优化背景
3.2. 优化过程

Cahce优势
- 灵活过滤,实现复杂的过滤合并逻辑
- 翻页读Cache性能高,首页使用Cache避免重复计算
时间线Cache需要解决的问题?弊端?
- 关系链变更Cache有延迟
- 脏Feed导致Cache体积减小
- 全量是在首次拉取,和24小时定时更新
- 增量则是在首页刷新,无最新数据则复用Cache
- 通过缓存关系链,如果关系链变更,活脏Feed太多过滤后导致的Cache体积过小,则触发修补逻辑
- 减少重复计算
- 有全局的Feed视图,方便实现全局策略
4. 主要表设计
4.1. Feed表设计
- 一个是Feed详情表
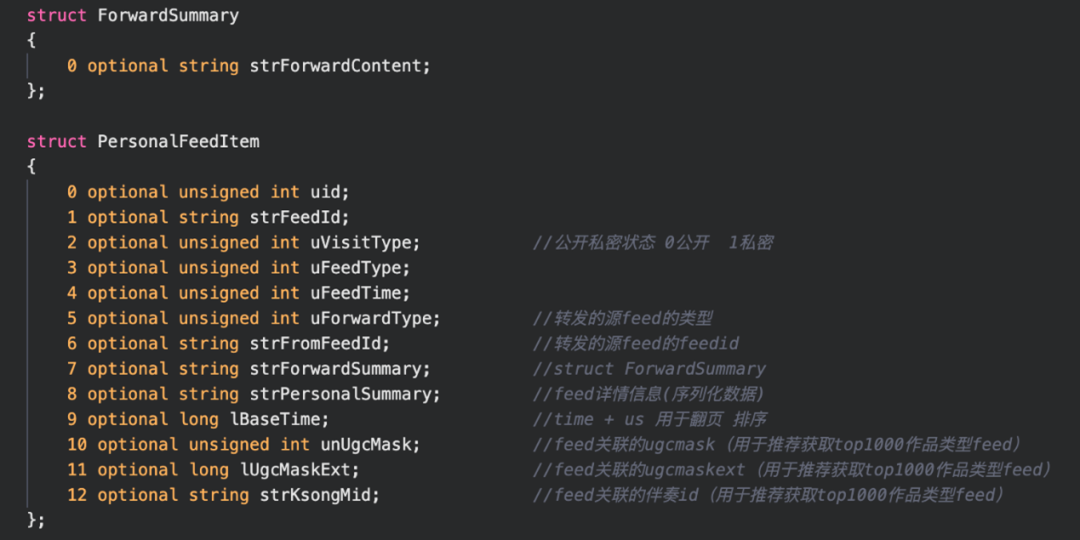
- Feed Cache表

4.2. 账号关系表设计
- 关注列表


- 粉丝
第二章:MongoDb使用层面优化
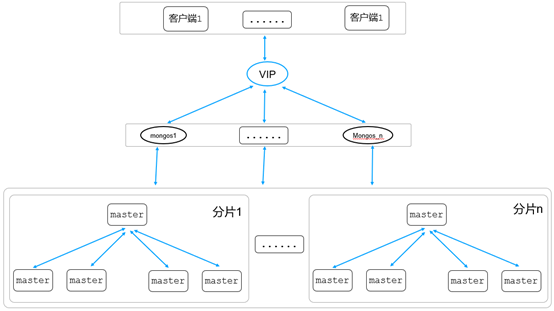
1. 最优片建及分片方式选择
- 数据写
- 数据读
说明:由于查询都是指定id类型查询,因此可以保证从同一个shard读取数据,实现了读取性能的最大化。但是,如果查询是例如userId类的范围查询,例如db.FeedInfo.find({userId:{$gt: 1000,$lt:2000}}),这种场景就不适合用hashed分片方式,因为满足{$gt: 1000}条件的数据可能很多条,通过hash计算后,这些数据会散列到多个分片,这种场景范围分片会更好,一个范围内的数据可能落到同一个分片。所以,分片集群片建选择、分片方式对整个集群读写性能起着非常重要的核心作用,需要根据业务的实际情况进行选择。
2. 查询不带片建如何优化
- FeedId字段
- UserId
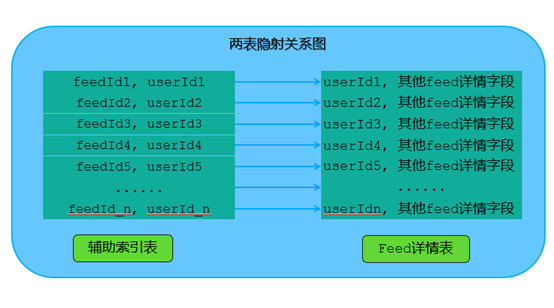
//根据feedId获取对应的userIddb.FeedId_userId_relationship.find({“FeedId”: “375”}, {userId:1}) //假设返回的userId为”3567”//根据userId+FeedId的组合获取具体的某条feed信息db.FeedInfo.find({“userId”: “3567”,“FeedId”:“375”})
3.count慢操作优化
{ "_id" : ObjectId("6176647d2b18266890bb7c63"), "userid" : “345”, "follow_userid" : “3333”, "realtiontype" : 3, "follow_time" : ISODate("2017-06-12T11:26:26Z") }{"executionSuccess" : true,"nReturned" : 0,"executionTimeMillis" : 0,"totalKeysExamined" : 156783,"totalDocsExamined" : 0,"executionStages" : {"stage" : "COUNT","nReturned" : 0,......"nSkipped" : 0,"inputStage" : {"stage" : "COUNT_SCAN",......}},"allPlansExecution" : [ ]}
4. 写大多数优化
{w:“majority”}:数据写入到副本集大多数成员后向客户端发送确认。场景:数据完整性要求比较高、避免数据回滚场景,该选项会降低写入性能。
对于可靠性要求比较高的场景往往还会使用{j: true}选项来保证写入时journal日志持久化之后才返回给客户端确认。数据可靠性高的场景会降低写的性能,在K歌Feed业务使用初期的场景会发现写大多数的场景都写延迟不太稳定,核心业务都出现了这种情况,从5ms到1s抖动。通过分析定位,我们发现是写时候到链式复制到策略导致的。
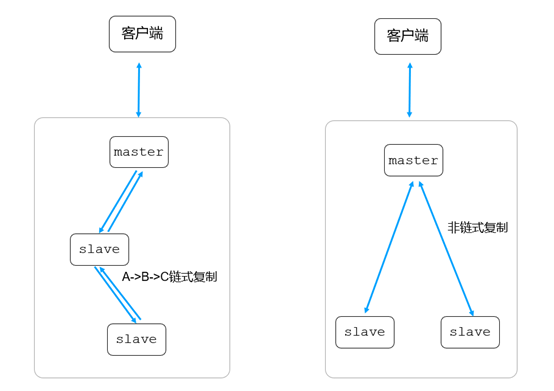
链式复制的概念:假设节点A(primary)、B节点(secondary)、C节点(secondary),如果B节点从A节点同步数据,C节点从B节点同步数据,这样A->B->C之间就形成了一个链式的同步结构,如下图所示:

cmgo-xx:SECONDARY> rs.conf().settings.chainingAllowedtruecmgo-xx:SECONDARY>
cmgo-xx:SECONDARY> rs.status().syncSourceHostxx.xx.xx.xx:7021cmgo-xx:SECONDARY>
cfg = rs.config()cfg.settings.chainingAllowed = falsers.reconfig(cfg)
链式复制不足:当写策略为majority时,写请求的耗时变大。
当业务采用“写大多数”策略时,也相应的关闭链式复制;避免写请求耗时变大。我们关闭了链式复制后整体写延迟文档在10ms以内。
5. 海量qps业务抖动优化
在一些核心集群,我们发现在高峰期偶尔会慢查询变多,服务抖动,抖动的表象看起来是因为个别CPU飙升导致的,通过分析具体高CPU的线程,以及perf性能分析具体的函数,我们发现主要是两个问题:
- 高峰期连接数量陡涨,连接认证开销过大,导致的CPU飙升。
- WT存储引擎cache使用率及脏数据比例太高,MongoDB的用户线程阻塞进行脏数据清理,最终业务侧抖动。
为了优化这两个问题,我们通过优化MongoDB的配置参数来解决:
- MongoDB连接池上下限一致,减少建立连接的开销
- 提前触发内存清理eviction_target=60 ,用户线程参与内存清理的触发值提高到97%:eviction_trigger=97,增加更多的清理线程:evict.threads_max:20,从而减少高峰期慢查询150k/min=>20k/min,服务稳定性也的到了提升
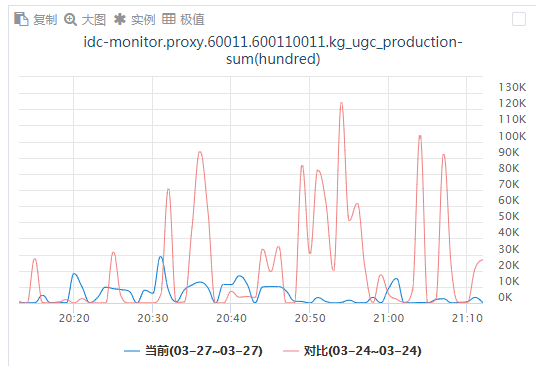
6. 数据备份过程业务抖动优化
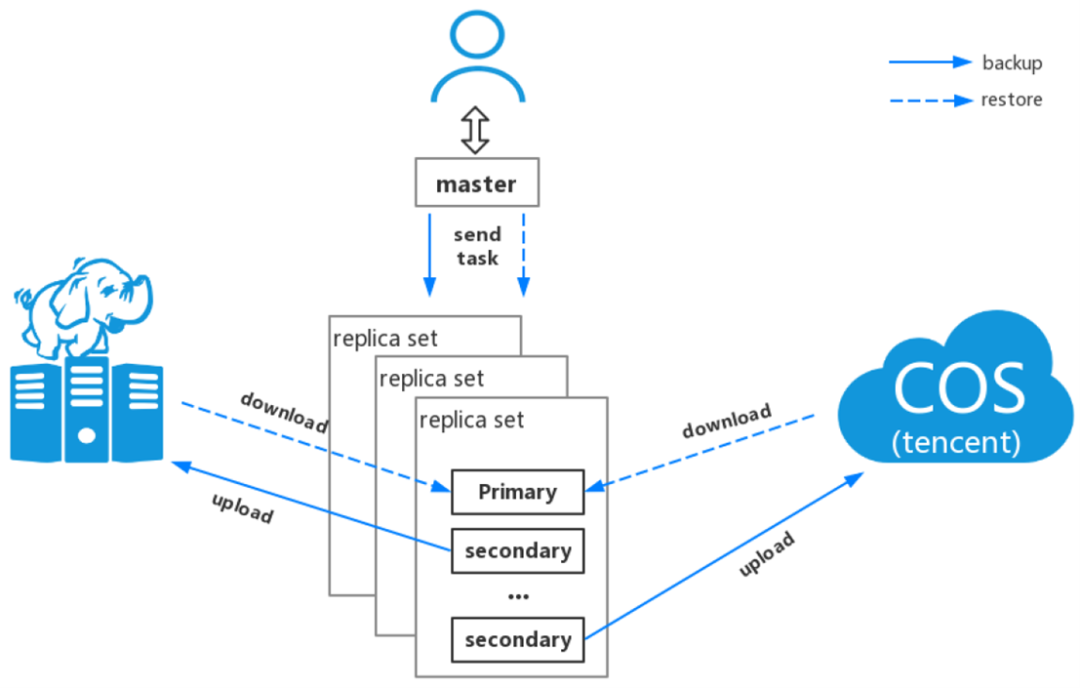
- 访问时延增加
- 慢日志增加
- CPU使用率增加
关于作者
全民K歌后台开发一组:
腾讯云MongoDB:
来这里,点亮自己!
添加小芒果微信(ID:mongoingcom)进入中文用户组技术交流群。
加入MongoDB技术交流群:添加小芒果微信,并备注:mongo
MongoDB中文社区技术大会议题征集中,点击下方链接来这里分享经验与见解:
MongoDB技术实践与应用案例征集活动进行中,截至11月30日,快来提交文稿拿大奖:https://sourl.cn/VHYHUt
MongoDB中文社区Freetalk系列筹备中,来提交你想分享/听其它大佬分享的内容:https://sourl.cn/QdDigu
点击申请加入核心用户组:
活动资料发布消息订阅:



评论前必须登录!
注册