 MongoDB中文社区
MongoDB中文社区
传统的数据库由于服务于单个节点,因此自然地为读写操作提供了顺序保证,这称为“因果一致性(causal consistency)”。分布式系统同样可以提供这些保证,但要做到这一点,就必须对所有节点上的相关事件进行协调和排序,并对某些操作完成的速度进行限制。虽然在所有数据顺序能得到保证时因果一致性很容易理解(模拟一个纵向扩展的数据库,即使系统遇到类似节点崩溃或网络分区等故障),但系统依旧需要在合理的一致性和持久性上进行许多权衡。
MongoDB多年来不断在使用并努力通过Jepsen测试。最近,我们在与Jepsen团队一起测试因果一致性。在他们的帮助下,我们了解到为提高数据吞吐量和时效性而妥协掉一致性保证会使故障模式变得多么复杂。
因果一致性定义
为了保持因果一致性,必须有以下保证:
| Read your writes | 读操作必须能够反映出在其之前的写操作。 |
| Monotonic reads | 如果某个读取操作已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值。 |
| Monotonic writes | 如果某些写操作必须先于其它写操作执行,那么它们会确实先于那些写操作执行。 |
| Writes follow reads | 如果某些写操作必须发生在读操作之后,那么它们会确实在那些读操作之后执行。 |
为了展示因果保证如何为应用程序提供价值,让我们看一个没有强制执行因果顺序的示例。图1中描述的分布式系统是一个复制集。这个复制集有一个主节点(或leader节点)接收所有传入的客户端写入,以及两个复制这些写入的从节点(或follower节点)。主从节点均可以为客户端提供读服务。

图1:一个没有强制因果一致性的副本集中的操作流程
- 客户端应用将234号订单写入主节点
- 主节点回复写入成功
- 234号订单从主节点复制到其中一个从节点
- 客户端应用从一个从节点读取订单集合
- 目标从节点没有查询到234号订单,所以返回结果为空
- 234号订单从主节点复制到另一个从节点
客户通过应用程序下订单,而应用程序将订单写入主节点并从一个从节点进行读取。如果是从一个尚未接收到复制的从节点进行这次读取,则应用程序将无法读取到自己写操作的结果。为了确保应用程序能够读取到自己的写操作,我们必须将单个节点上的操作顺序扩展为系统中所有节点的全局偏序关系。
实现
到目前为止,本文只讨论了副本集。但要在分布式系统中建立事件的全局偏序关系,MongoDB不仅要考虑副本集,还要考虑分片集群,其中每个分片都是一个包含部分数据的副本集。
为了建立副本集和分片集群事件的全局偏序关系,MongoDB实现了一个基于Lamport逻辑时钟(Lamport logical clock)的混合逻辑时钟。在系统中每个写入或更改状态的事件在应用于主节点时都会被分配一个时间。这一时间可以在部署的所有成员之间进行比较。从驱动到查询路由器再到数据承载节点,分片集群中的每个成员都必须在每条消息中跟踪和发送其最新时间值,从而允许分片之间的每个节点在“最新时间”这个概念上保持一致。主节点将最新的逻辑时间赋值给后续的写入,这为任何一系列相关操作创建了一个因果顺序。节点可以使用这个因果顺序在执行所需的读或写之前等待,以确保它在另一个操作之后发生。
如果想更深入地了解集群范围内因果一致性的实现,请看Misha Tyuleev的演讲。
重新回到图1中的示例,但现在我们对因果一致性进行强制要求:

图2:一个具有强制因果一致性的副本集中的操作流程
- 客户端应用将234号订单写入主节点
- 主节点回复已将这一写入的时间记为T1
- 234号订单从主节点复制到其中一个从节点
- 客户端应用在T1时间后从一个从节点进行读取
- 目标从节点还没有看到时间T1,因此必须等待
- 234号订单从主节点复制到另一个从节点
- 这个从节点可以将234号订单的内容返回给客户端了
Write Concern 和 Read Concern
Write concern 和 read concern 是可以应用于每个操作的设置,而且也可以用在一组因果一致的操作中。Write concern 提供了延迟和持久性之间的选择。而 read concern 更微妙一些;它用更严格的隔离级别以换得更新的结果。这些设置会影响系统故障期间的保证
WRITE CONCERN
Write concern 或者说写入确认(write acknowledgement)是指在向客户端返回成功消息之前必须满足的写操作的持久性要求。Write concern 选项包括:
| 1 | 一旦写入操作应用到主节点,则返回成功 |
| n | 一旦写入操作应用到n个节点,则返回成功 |
| majority | 一旦写入操作应用到大多数节点,则返回成功 |
只有 write concern 为 majority 的成功写入才能保证在任何系统故障下都能保存下来,并且永远不会回滚。
在发生网络分区时,两个节点可能暂时都认为自己是副本集的主节点,但只有真正的主节点才能看到并提交到大多数节点。Write concern 为 1 的写操作可以成功地应用于任一主节点,而 write concern 为 majority 的写操作只能在真正的主节点上成功。然而,这种持久性是有性能成本的。使用 write concern 为 majority 的每个写操作都必须等待大多数节点提交,然后客户机才能收到来自主节点的响应。只有这时,线程才能被释放以执行其它工作。在MongoDB中,你可以根据需要选择在某个操作上支付这一成本。
READ CONCERN
Read concern 是指读取的隔离级别。Read concern local 会返回本地提交的数据,而read concern majority 会返回每个节点维护的多数提交快照(majority committed snapshot)中的数据。多数提交快照包含已提交给多数节点的数据,并且在主节点选取时不会回滚。然而读操作可能会比 read concern local 更频繁地返回过时数据,因为多数快照可能缺少尚未经过多数提交的最新写入,这种权衡可能会让应用程序使用旧数据。就像 write concern 一样,你可以在操作级别选择适当的 read concern。
Write Concern 和 Read Concern 的效果
随着因果一致性的推出,我们让Jepsen团队帮助我们探索因果一致性如何与 read concern 和 write concern 进行交互。虽然我们都对该特性在 read/write concern 为 majority 情况下的行为比较满意,但Jepsen团队确实在read/write concern为其它组合时发现了一些异常。虽然更宽松的组合可能更适合某些应用程序,但了解任何数据库(无论是否分布式)所应用的确切的折衷方案是很重要的。
故障场景示例
现在看一下在网络分区期间 read concern 和 write concern 不同组合的行为,其中 P1 已经和大多数节点分离,P2 已被选为新的主节点。由于 P1 还不知道自己不再是主节点,所以它可以继续接受写操作。一旦 P1 重新连接到大多数节点,那么它自从时间线分歧以来的所有写入操作都将被回滚。
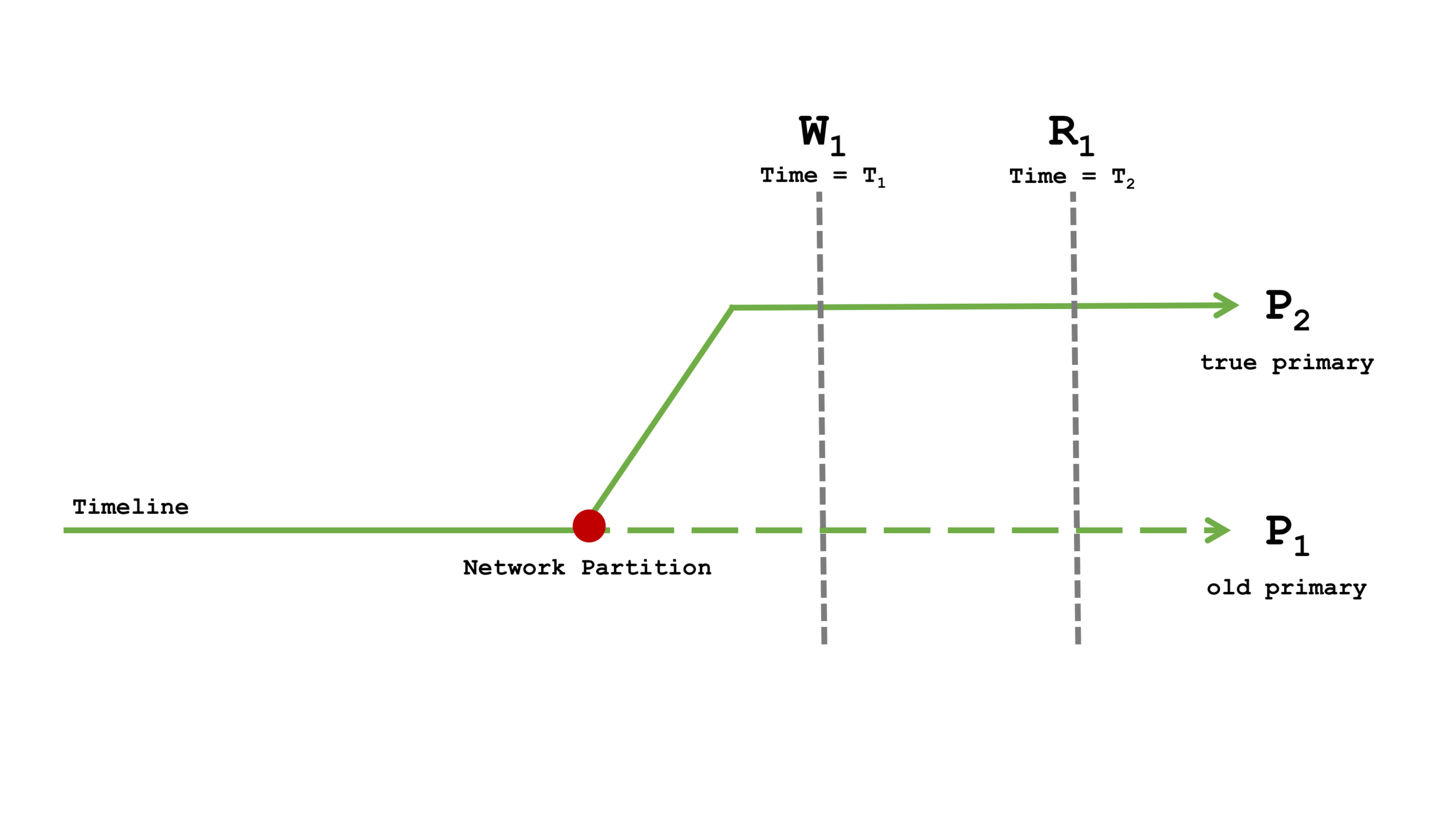
图3: 网络分区时间线
在这段时间,有一个客户端发出了一系列具有因果关系的操作,如下所示:
- 在 T1 时间执行了写操作 W1
- 在 T2 时间执行了读操作 R1
下面四个场景讨论了不同的 read/write concern 组合及其权衡。
Read Concern majority 和 Write Concern majority
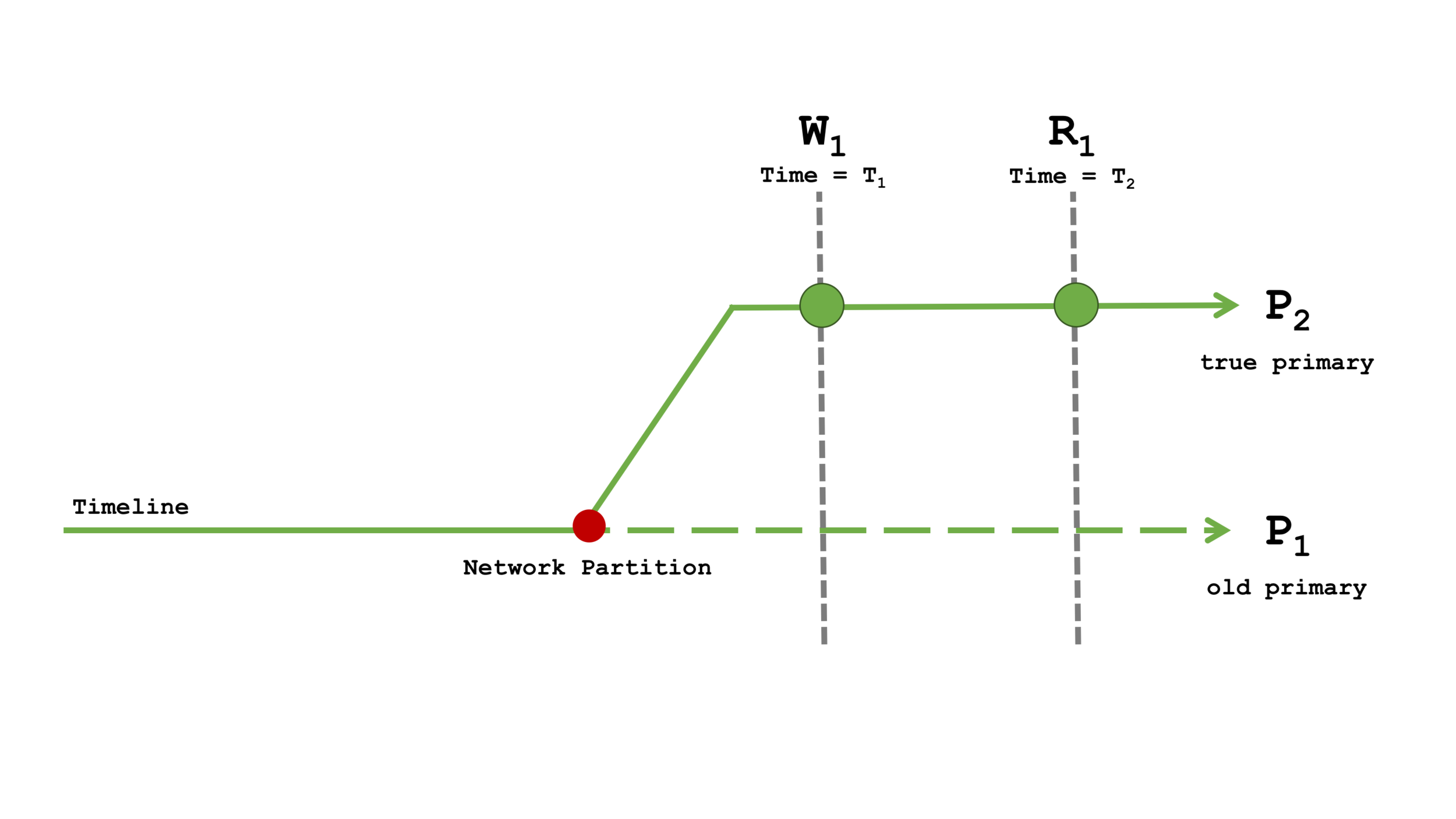
图4: Read Concern majority 和 Write Concern majority
只有当 write concern 为 majority 的写操作 W1 应用于大多数节点时,它才算写入成功。这意味着 W1 必须在真正的主节点时间线上执行,并且不能回滚。
Read concern 为 majority 的具有因果关系的读操作 R1 在返回成功之前会等待 T1 时间点的多数提交。由于 P1 与大多数节点分区而无法进行它的多数提交,因此 R1 只有在真正的主节点时间线上才会成功。所以 R1 会得到 W1 的最终结果。
无论发生任何故障,所有的因果保证都可以得到维持。所有具有 write concern majority 的写操作都会防止在失败场景中出现不可预期的行为,代价就是写入会较慢。对于最关键的数据,比如金融应用中的订单和交易,开发人员可以牺牲一些性能来换取持久性和一致性。
Read Concern majority 和 Write Concern 1

图5: Read Concern majority 和 Write Concern 1
使用 write concern 1 的写操作 W1 可能在 P1 或 P2 任一时间线上执行成功;而在 P1 上执行成功的 W1 最终会回滚。
Read concern 为 majority 的具有因果关系的读操作 R1 在返回成功之前会等待 T1 时间点的多数提交。由于 P1 与大多数节点分区而无法进行它的多数提交,因此 R1 只有在真正的主节点时间线上才会成功。所以 R1 会得到 W1 的最终结果。在W1 在 P1 上执行的情况下,W1 最终可能并没有提交。如果 R1 发现 W1 没有提交,那么 W1 将永远不会提交。如果 R1 可以看到 W1,那么说明 W1 在 P2 上成功提交,并且永远不会回滚。
这个 read/write concern 组合给出了因果顺序的保证,但不保证故障发生时的持久性。
假设现在有一个需要快速服务其用户的大型平台,其中的大规模应用程序需要具备高吞吐量以及对请求的低延迟响应。当系统尝试跟上负载的增长时,如果每个请求都有一个较长的响应时间是无法满足需求的。Twitter的发帖界面可以很好地模拟这种 read/write concern 组合:
处于pending状态的tweet是以灰色显示的,可以认为是一个 write concern 为 1 的写操作。当我们进行刷新时,这个工作流可以利用 read concern majority 来明确告诉用户这次发布是否已经保存成功。Read concern majority 可以帮助用户安全地从错误中恢复。当刷新并且帖子消失时,我们可以重试而不会有重复发布的风险。如果在刷新后看到了发布的帖子,我们就知道这个帖子不会消失了。
Read Concern local 和 Write Concern majority

图6: Read Concern local 和 Write Concern majority
只有当 write concern 为 majority 的写操作 W1 应用于大多数节点时,它才算写入成功。这意味着 W1 必须在真正的主节点时间线上执行,并且不能回滚。
在 read concern 为 local 的情况下,具有因果关系的读操作 R1 可能发生在 P1 或 P2 任一时间线上。当 R1 在 P1 上执行时会出现异常情况。在P1上无法看到多数提交的写操作,这打破了 “read your own writes” 的保证。如果跨 P1 和 P2 时间线陆续执行多次读取,那么 monotonic reads 也无法满足。在发生故障的情况下,因果顺序将无法保证。
假设现在有一个可以评论各种产品或服务的网站,其中所有写操作的 write concern 都是 majority,所有读操作的 read concern 都是 local。这些评论需要用户的大量投入,应用程序希望在进行下一步之前能确保它们都被持久化下来。想象一下,一个用户深思熟虑地写了两段评论,结果它却被弄丢了。在 write concern 为 majority 的情况下,成功被确认的写操作永远不会丢失。对于一个具有繁重的读取操作负载的网站,由于写入操作较少,majority 所产生的高延迟可能不会影响性能。而 read concern 为 local,使得客户端可以读取到目标节点的最新评论。但是目标节点有可能是 P1,并且不保证包含客户端自己的写入,而这些写入已成功地在真正的时间线上持久化。此外,这个节点的最新评论可能会包含其它评论者尚未被确认的写入,而这些写入是有可能回滚的。
Read Concern local 和 Write Concern 1

Diagram 7: Read Concern local 和 Write Concern 1
Read concern local 和 write concern 1 的组合与上一个场景有相同的问题,但此外写入还缺乏持久性。使用 write concern 1 的写操作 W1 可能在 P1 或 P2 任一时间线上执行成功;而在 P1 上执行成功的 W1 最终会回滚。在 read concern 为 local 的情况下,具有因果关系的读操作 R1 可能发生在 P1 或 P2 任一时间线上。当 R1 在 P1 上执行时会出现异常情况。在P1上无法看到多数提交的写操作,这打破了 “read your own writes” 的保证。如果跨 P1 和 P2 时间线陆续执行多次读取,那么 monotonic reads 也无法满足。在发生故障的情况下,因果顺序将无法保证。
假设现在有一个智能设备的传感器网络,它不处理报告事件数据时遇到的故障。这些应用可能有颗粒传感器的数据,而这些数据驱动的写入吞吐量很高。传感器事件数据的顺序对于跟踪和分析随时间变化的数据趋势很重要。一小段时间内的视图对于整体趋势分析并不重要,因为数据包可能会丢失。而 write concern 为 1 的写入操作可能适合于这种没有严格耐久性要求但需要保证系统吞吐量的场景。对于高吞吐量的工作负载和更希望读取到最新数据的读取操作,read concern local 和 write concern 1 的组合实现了前面所提到的权衡。在系统所有节点范围内看,它提供了与仅在主节点上的操作相同的行为。
结论
任何系统(无论是否是分布式)中的每个操作都会做出一系列影响应用程序行为的权衡。与Jepsen团队的合作促使我们思考 read/write concern 与因果一致性结合在一起所涉及的权衡。MongoDB现在建议同时使用 read concern majority 和 write concern majority 使得可以在所有故障场景中保持因果一致和持久性。但是其它组合,特别是 read concern majority 和 write concern 1,可能更适合于某些应用程序。
为开发者提供各种 read/write concern 可以让他们能够精确调整工作负载的一致性、耐久性和性能。我们与Jepsen的合作有助于更好地描述不同故障场景下系统的行为,使开发者能够在可用的保证和权衡中做出更明智的选择。



赞,通俗易懂