 MongoDB中文社区
MongoDB中文社区

译者:汪洋
文章来源:https://severalnines.com/database-blog/battle-nosql-databases-comparing-mongodb-and-oracle-nosql
为了能够更好的支持大数据或者实时应用,现在我们通常需要非关系型的、动态的schema,这样就没有必要进行表关联查询。NoSQL数据库的出现,就是要让多台服务器协同处理,提升数据处理的性能,以及通过横向扩展来承载分布式数据库负载,来满足新一代数据处理的需求。
MongoDB除了提供多样化的数据模型和脚本化语言之外,还可以让开发人员更容易地开始进行数据处理。
NoSQL开启了多种可能性:
- 使用脚本化语言的基于文本的协议(REST, JSON, BSON)
- 生成、存储以及访问数据成本最小化
- 支持海量的数据处理
- 大幅提升写性能
- 无需使用ORM模型以及范式化操作
- 对于参照完整性没有严格的控制
- 降低DBA的运维成本
- 降低扩容成本
- 快速的key-value访问
- 对于机器学习和智能的良好支持
MongoDB的市场接受程度
大数据分析和现在的应用系统需要不断提升数据处理的生命周期,它们扮演着重要的角色,同时又不希望硬件不断升级以及伴随着成本的上升。
现在市场上数据库产品众多,如果你正在计划建设一个新的应用系统并且需要选择一款数据库产品,要在如此多样化的产品中做出正确的选择,将是一个非常复杂的过程。
和Oracle NoSQL相比,在数据库引擎排名 我们可以看到 MongoDB 位列第一,而Oracle NoSQL排在第74位。这个趋势揭示了当前的一些改变。对于很多注重成本的扩容的需求开始使用更加简单的数据建模,数据库的管理维护也正在改变开发人员的想法,为他们的系统选择最好的解决方案。
根据Datanyze 的市场分析今天Oracle NoSQL占据11%的市场份额,大概有289个网站在使用,而MongoDB占据4.66%的市场份额,总共有12,185个网站在使用。这个数字说明了MongoDB的前景非常好。
NoSQL数据建模
数据建模需要对以下方面有所了解:
- 当前的数据类型
- 哪些是你未来所需要的数据类型?
- 应用如何来访问系统中的数据?
- 应用如何获取需要的数据来进行处理?
对于那些总是按照Oracle的方法来创建Schema,存储数据的人来说,MongoDB 让你能够在创建Document的同时自动创建Collection。这意味着在创建Document之前Collection不一定必须已经存在,这和关系型数据库完全不同,因此带来了极大的灵活性。
即使在Oracle NoSQL中,也必须先创建表,在表创建之后才能够创建数据行。
MongoDB 还有一个很大的优点是在Schema上没有强制的规则以及关系型数据库中关系的概念,这一点给系统的持续迭代更新带来了很大的自由度,从而没有必要总是担心要严格遵从模式设计。
让我们比较一些MongoDB 和Oracle NoSQL的不同。
MongoDB和Oracle在NoSQL概念上的比较
|NoSQL术语
| MongoDB | Oracle NoSQL | 备注 |
|---|---|---|
| Collection | Table/View | Collection和Table都是存储的容器,但他们又是不一样的 |
| Document | Row | 对于MongoDB来说,数据以Document和Field的形式存储在Collection中 |
| Field | Column | 对于Oracle NoSQL来说,table是row的集合,每一个row都是数据的一条记录。每个row都包含key和数据字段,这些都是在创建表时就定义好的 |
| Index | Index | 两种数据库都使用索引来提升查询速度 |
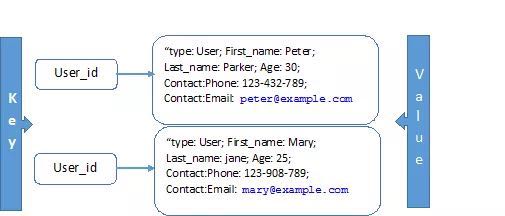
|Document和Key-Value存储
Oracle NoSQL提供的存储系统以key做为索引来存储value,所以数据集包含了索引的key-value,这个模型非常简单。每条记录通过主要的key和次要的key来组织。
主要的key被看成是对象指针,而次要的key做为记录的字段。就像通过使用主键查询数据一样,对于key-value数据的查找来通过这些key来进行。
MongoDB 对key-value的概念进行了扩展。每一个document都有一个唯一的key,用于访问document。这些document是动态的模式,因为一个collection中的document不需要包含完全一样的字段。一个collection也可以有对应于不同数据类型的一个公共字段。这些特性让document数据模型可以直接支持面向对象的语言,进行数据结构的映射。
| MongoDB | Oracle NoSQL |
|---|---|
| Document存储 示例:
|
Key-value存储 示例:
|

|BSON和JSON
Oracle NoSQL使用JSON做为传输数据的标准格式(数据+属性-值对),而MongoDB则使用BSON。
| MongoDB | Oracle NoSQL |
|---|---|
| BSON | JSON |
| Binary JSON – 二进制格式 – 更快的处理速度 | Javascript Object Notation – 标准格式。相比BSON而言,处理速度很慢 |
| 特性: – BSON格式对于我们来说不可读 – 轻量 – 可遍历 – 高效 – 更多的数据类型:BinData和Date |
特性: – 可读的数据格式 – 轻量 – 内容简洁 – 基本文本的数据交换格式 – 独立于编程语言 |
BSON不像JSON,对于我们来说是不可读的。BSON是将JSON进行二进制序列化之后的数据,主要用于MongoDB 中的数据存储和传输。BSON数据格式由有序的元素列表组成,包含字段名称(字符串),类型和值。BSON支持的数据类型除了JSON中的之外,还包含了两个附加的数据类型,Binary Data和Date。小于16MB的Binary Data可以被直接存储在document中,也称之为BinData。但BSON比起JSON文档会消耗更多的存储空间。
MongoDB 消耗比Oracle NoSQL更多的存储空间主要有以下两个原因:
- MongoDB对于对象的遍历访问更加快速,为了达到这个目标,需要BSON文档包含更多的元数据,例如字符串和子对象的长度。
- BSON的编码和解码非常快速。例如,数值使用32或者64位的整数来存储,从而避免了基于文本的解析操作。对于小的数值来讲,相比JSON会使用更多的空间,但同时解析效率会提升很多。
|数据模型定义
MongoDB Collection语句
创建一个collection
db.createCollection("user")
创建一个collection,同时文档的ID自动产生
db.users.insert
( {
User_id: "U1",
First_name: "Mary"
Last_name : "Winslet",
Age : 15
Contact : {
Phone: "123-456-789"
Email: "mary@example.com"
}
access : {
Level:5,
Group:"dev"
}
})
MongoDB可以让有关联的信息嵌入到相同的数据库记录也就是document中。Data model Design
Oracle NoSQL表语句
使用SQL命令行定义命名空间:
Create namespace newns1;
使用命名空间来关联表和子表
newns1:users
newns1:users.access
创建一个有IDENTITY字段的表
Create table newns1.user (
idValue INTEGER GENERATED ALWAYS AS IDENTITY (START WITH 1 INCREMENT BY 1 MAXVALUE 10000),
User_id String,
First_name String,
Last_name String,
Contact Record (Phone string,
Email string),
Primary key (idValue));
使用SQL JSON创建一张表:
Create table newns1.user (
idValue INTEGER GENERATED ALWAYS AS IDENTITY (START WITH 1 INCREMENT BY 1 MAXVALUE 10000),
User_profile JSON,
Primary Key (shard(idValue),User_id));
User表中行的格式:JSON
{
"id":U1,
"User_profile" : {
"First_name":"Mary",
"Lastname":"Winslet",
"Age":15,
"Contact":{"Phone":"123-456-789",
"Email":"mary@example.com"
}
}
根据以上的数据定义示例可以看出,MongoDB 可以使用多种方式来创建Schema。可以显式地定义Collection,也可以在数据第一次插入的时候隐式地定义。在创建一个collection,可以定义一个objectid。objectid是MongoDB文档的主键。Objectid 是一个12字节的BSON类型,由MongoDB服务器和驱动产生。MongoDB objectid 用于一个collection中document的排序。
Oracle NoSQL同样也有几种不同的方法来进行表的定义。如果使用SQL命令行来进行定义,新创建的表会被放在sysdefault中,直到一个新的命名空间被创建并且把相关的表和命名空间关联起来。上面的例子展示了一个新的命名空间newns1 被创建,并且关联了user表。
除了定义主键,Oracle NoSQL也使用IDENTITY 在新数据行插入的时候自增值。IDENTITY的值是自动生成的,而且必须是Integer、long或者number类型。在Oracle NoSQL中,与MongoDB生成objectid类似,IDENTITY由序列生成器产生。IDENTITY可以作为主键字段。如果考虑使用IDENTITY作为主键,可能对数据的插入和更新产生影响,这点需要仔细考虑。
上面的例子展示了在不需要额外的Schema定义情况下,MongoDB 和Oracle NoSQL如何在一个单一的数据结构中嵌入user 信息。带来的好处是无需进行另外的查询来获取需要的数据。
如果你计划将系统的管理尽量简单化,MongoDB 提供了很好而且简单的方法。同时,通过使用schema validation tool MongoDB可以从关系型Schema中实现复杂的数据模型。
而Oracle NoSQL可以让有关系型数据库系统经验的用户使用SQL语句来进行DDL和DML操作。
MongoDB shell使用Javascript,如果你不习惯使用Javascript或者MongoDB shell,那么只能使用IDE工具。2020年,头5个MongoDB IDE工具分别是studio 3T, Robo 3T, NoSQLBooster, MongoDB Compass和Nucleon Database Master。这些工具可以对于实现复杂的查询是非常有帮助的。
|性能和可用性
MongoDB 数据结构模型使用document和collection,和Oracle NoSQL相比,处理海量数据时使用BSON处理性能要高出很多。可能对于很多用户来讲,使用SQL会舒服很多,但容量变成一个问题。当我们有海量的数据需要处理,对于不断增加的系统吞吐量和使用SQL语句来进行复杂查询的需求,需要我们仔细评估服务器的容量和不断增加的成本。
MongoDB 和Oracle NoSQL都支持Sharding和Replication。Sharding可以让数据库和系统整体的负载分布在多个物理分区,从而增加处理速度。Oracle的Shard实现需要我们事先了解sharding key如何工作。这是因为在最初创建Schema的时候就需要按照sharding的方式来进行。
而MongoDB 对于Shard的实现让我们在实施前,基于系统的查询模式,在数据集中找到可能的正确的sharding key。MongoDB的复制速度也很快,在一台服务器发生问题的时候,复制可以自动完成复制集副本间的切换。
结论
MongoDB 相比Oracle NoSQL更加受欢迎是因为它的二进制编码格式以及设计中就已经考虑到的轻量性、可遍历性以及效率。这些特性让它在机器学习和人工智能领域能够支持快速发展的应用系统。
MongoDB 的特性让开发人员更有信心以及更快地开发应用系统。相比Oracle NoSQL,MongoDB的数据模型能够让我们非常有效地处理海量的非结构化数据。另一方面,Oracle NoSQL提供了大量的工具和选项让我们建立数据模型。但归根结底,能够让开发和设计人员快速地学习和采用新技术才是最重要的,而Oracle NoSQL很难做到这一点。




评论前必须登录!
注册