从本月起,我们将从逻辑正确、内容完整的角度全面介绍WiredTiger存储引擎,推出WiredTiger存储引擎系列文章。由于源码体量很大,通读工作量巨大,细节之处如有问题和错误,欢迎大家指出。
本篇作为WiredTiger存储引擎介绍系列文章第一篇,包含如下内容:
存储引擎要做的事情无外乎是将磁盘上的数据读到内存并返回给应用,或者将应用修改的数据由内存写到磁盘上。如何设计一种高效的数据结构和算法是所有存储引擎要考虑的根本问题,目前大多数流行的存储引擎是基于B-Tree或LSM(Log Structured Merge) Tree这两种数据结构来设计的。
像Oracle、SQL Server、DB2、MySQL (InnoDB)和PostgreSQL这些传统的关系数据库依赖的底层存储引擎是基于B-Tree开发的;而像Cassandra、Elasticsearch (Lucene)、Google Bigtable、Apache HBase、LevelDB和RocksDB这些当前比较流行的NoSQL数据库存储引擎是基于LSM开发的。当然有些数据库采用了插件式的存储引擎架构,实现了Server层和存储引擎层的解耦,可以支持多种存储引擎,如MySQL既可以支持B-Tree结构的InnoDB存储引擎,还可以支持LSM结构的RocksDB存储引擎。
对于MongoDB来说,也采用了插件式存储引擎架构,底层的WiredTiger存储引擎还可以支持B-Tree和LSM两种结构组织数据,但MongoDB在使用WiredTiger作为存储引擎时,目前默认配置是使用了B-Tree结构。
因此,本章后面的内容将以B-Tree为核心来分析MongoDB是如何将文档数据在磁盘和内存间进行流传以及WiredTiger存储引擎的其它高级特性。
B-Tree是为磁盘或其它辅助存储设备而设计的一种数据结构,目的是为了在查找数据的过程中减少磁盘I/O的次数,一个典型的B-Tree结构如下图所示:
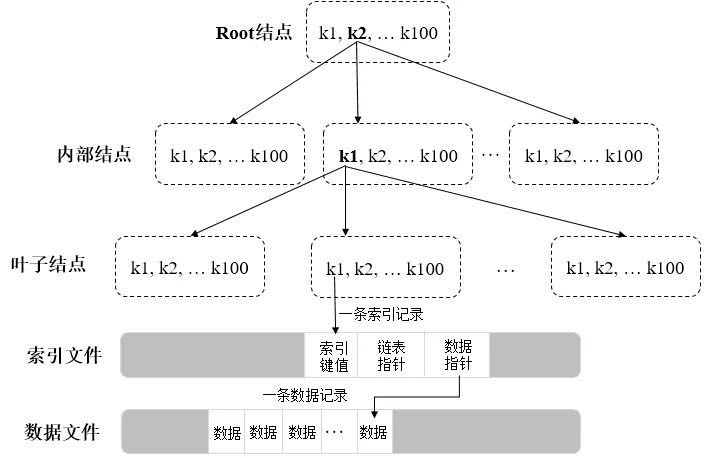
图:典型的B-Tree数据结构
在整个B-Tree中,从上往下依次为Root结点、内部结点和叶子结点,每个结点就是一个Page,数据以Page为单位在内存和磁盘间进行调度,每个Page的大小决定了相应结点的分支数量,每条索引记录会包含一个数据指针,指向一条数据记录所在文件的偏移量。
如上图,假设每个结点100个分支,那么所有叶子结点合起来可以包含100万个键值(等于100*100*100)。通常情况下Root结点和内部结点的Page会驻留在内存中,所以查找一条数据可能只需2次磁盘I/O。但随着数据不断的插入、删除,会涉及到B-Tree结点的分裂、位置提升及合并等操作,因此维护一个B-Tree的平衡也是比较耗时的。
对于WiredTiger存储引擎来说,集合所在的数据文件和相应的索引文件都是按B-Tree结构来组织的,不同之处在于数据文件对应的B-Tree叶子结点上除了存储键名外(keys),还会存储真正的集合数据(values),所以数据文件的存储结构也可以认为是一种B+Tree,其整体结构如下图所示:
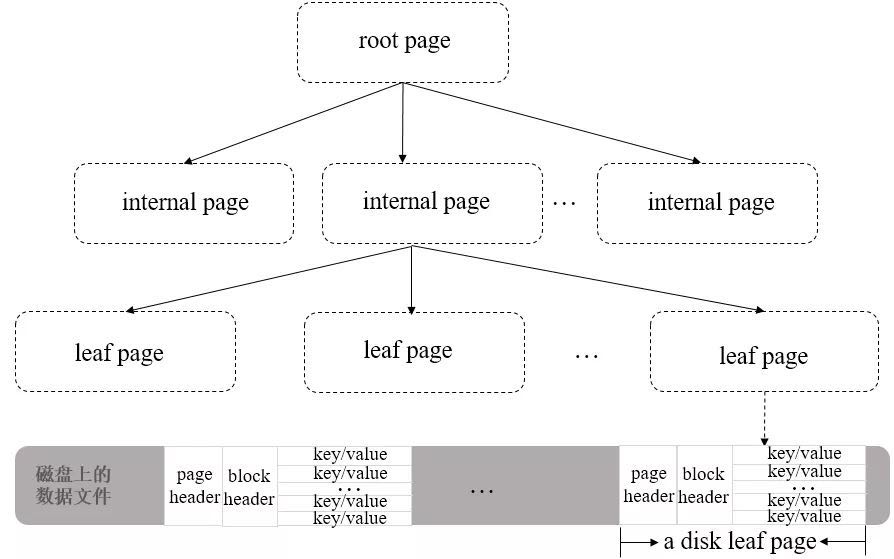
图:WiredTiger数据文件在磁盘上的存储结构
从上图可以看到,B+ Tree中的leaf page包含一个页头(page header)、块头(block header)和真正的数据(key/value),其中页头定义了页的类型、页中实际载荷数据的大小、页中记录条数等信息;块头定义了此页的checksum、块在磁盘上的寻址位置等信息。
WiredTiger有一个块设备管理的模块,用来为page分配block。如果要定位某一行数据(key/value)的位置,可以先通过block的位置找到此page(相对于文件起始位置的偏移量),再通过page找到行数据的相对位置,最后可以得到行数据相对于文件起始位置的偏移量offsets。由于offsets是一个8字节大小的变量,所以WiredTiger磁盘文件的大小,其最大值可以非常大(264bit)。
WiredTiger会按需将磁盘的数据以page为单位加载到内存,同时在内存会构造相应的B-Tree来存储这些数据。为了高效的支撑CRUD等操作以及将内存里面发生变化的数据持久化到磁盘上,WiredTiger也会在内存里面维护其它几种数据结构,如下图所示:

图:WiredTiger在内存上的数据结构
上图是WiredTiger在内存里面的大概布局图,通过它我们可梳理清楚存储引擎是如何将数据加载到内存,然后如何通过相应数据结构来支持查询、插入、修改操作的。
- 内存里面B-Tree包含三种类型的page,即rootpage、internal page和leaf page,前两者包含指向其子页的page index指针,不包含集合中的真正数据,leaf page包含集合中的真正数据即keys/values和指向父页的home指针;
- 内存上的leaf page会维护一个WT_ROW结构的数组变量,将保存从磁盘leaf page读取的keys/values值,每一条记录还有一个cell_offset变量,表示这条记录在page上的偏移量;
- 内存上的leaf page会维护一个WT_UPDATE结构的数组变量,每条被修改的记录都会有一个数组元素与之对应,如果某条记录被多次修改,则会将所有修改值以链表形式保存。
- 内存上的leaf page会维护一个WT_INSERT_HEAD结构的数组变量,具体插入的data会保存在WT_INSERT_HEAD结构中的WT_UPDATE属性上,且通过key属性的offset和size可以计算出此条记录待插入的位置;同时,为了提高寻找待插入位置的效率,每个WT_INSERT_HEAD变量以跳转链表的形式构成。

图:跳转链表示意图
假如现在插入一个16,最终结果如下:

图:跳转链表插入一个元素16后的示意图
如果是一个普通的链表,寻找合适的插入位置时,需要经过:
开始结点->2->5->8->10->20的比较;
对于跳转链表来说只需经过:开始结点->5->10->20的比较,可以看到比在普通链表上寻找插入位置时需要的比较步骤少,所以,通过跳转链表的数据结构能够提升插入操作的效率。
对于一个面向行存储的leaf page来说,包含的数据结构除了上面提到的WT_ROW(keys/values)、WT_UPDATE(修改数据)、WT_INSERT_HEAD(插入数据)外,还有如下几种重要的数据结构:
WT_PAGE_MODIFY:
保存page上事务、脏数据字节大小等与page修改相关的信息;
read_gen:
page的read generation值作为evict page时使用,具体来说对应page在LRU队列中的位置,决定page被evict server选中淘汰出去的先后顺序。
WT_PAGE_LOOKASIDE:
page关联的lookasidetable数据。当对一个page进行reconcile时,如果系统中还有之前的读操作正在访问此page上修改的数据,则会将这些数据保存到lookasidetable;当page再被读时,可以利用lookasidetable中的数据重新构建内存page.
WT_ADDR:
page被成功reconciled后,对应的磁盘上块的地址,将按这个地址将page写到磁盘,块是最小磁盘上文件的最小分配单元,一个page可能有多个块。
checksum:
page的校验和,如果page从磁盘读到内存后没有任何修改,比较checksum可以得到相等结果,那么后续reconcile这个page时,不会将这个page的再重新写入磁盘。
MongoDB中文社区委员,长沙分会主席
《大数据存储MongoDB实战指南》作者资深大数据架构师,通信行业业务架构与数据迁移专家
 MongoDB中文社区
MongoDB中文社区





innodb和wt的数据结构都是b+tree,不过innodb的root page和internal page中存的是id+偏移量。不知道mongo是不是document的id+偏移量,否则如何根据documentId找到对应的page呢?
和mysql的结构主要的区别是什么呢?为什么说mongo存储非结构化数据
👍
按你这个说法WiredTiger无论在磁盘还是内存都是b+树呀,叶级页保存数据。那平常为啥不直接说wt的默认数据结构是b+树而是说是b树呢