 MongoDB中文社区
MongoDB中文社区

过去二十年,存储硬件的性能提升了两个数量级。首先,是SSD的出现;然后是计算机总线接口从SATA到PCIe的转变;最后在非易失性内存技术和制造工艺上的创新。就在2019年的4月份,Intel发布了首个商业化存储级内存产品(SCM)Optane DC Persistent Memory,它使用了3D XPoint技术,位于内存总线上,并且进一步降低了IO的时延。
在过去,IO时延主要受到设备访问的影响,但随着设备访问时间的减少,在IO路径上存储系统软件的成本开销显得越来越大。这些因素让很多科学研究进入这个领域并且造成了操作系统和文件系统上的改变。但即使如此,主流的系统软件仍然无法跟上快速发展的硬件速度。研究表明文件系统和其他操作系统的开销仍然主导了在使用快速存储设备如SCM情况下的大部分IO成本。
应对这些挑战,科研机构建议了新的用户层级的文件系统SplitFS,如6所示。SplitFS能够大幅减少IO过程中这些不必要的开销。但不幸的是,采用用户层级的文件系统对于很多商业化产品来说是不现实的。除了对于正确性、稳定性和可维护性的担忧,SplitFS的使用对产品的可移植性有很大的限制,它只能运行于Linux操作系统并且必须和ext4-DAX文件系统一起使用。
好消息是,在存储引擎中,确实有些东西我们可以做来提升IO性能。在MongoDB的存储引擎WiredTiger中,我们可以在不牺牲方便性和移植性的基础上将文件系统中影响性能的因素移除。我们做出的改变是使用内存映射文件(memory-mapped files)来进行IO并且批量进行昂贵的文件系统操作。在使用主流SSD进行的65个IO基准测试中,这些改变能够给我们带来其中19个场景中多达63%的性能提升。
WiredTiger中的流式I/O
UCSD的研究促使我们对WiredTiger做出了改进,如4所示。UCSD的研究表明,通过使用内存映射文件来进行IO访问,以及当文件需要扩展的时候预先分配额外的空间,那么性能可以达到和访问裸设备一样,就像文件系统不存在一样。
内存映射文件(Memory-mapped files)
内存映射文件的工作机制是这样的。应用系统发起mmap的系统调用,要求操作系统把它虚拟地址空间的一部分映射到需要访问文件中相同大小的一块区域(图1的步骤1)。这样当应用第一次访问被映射的内存区域时:
- 因为这块虚拟内存还未曾被访问过,硬件会产生一个trap并且将控制交给操作系统;
- 操作系统决定这是一个合法的虚拟内存地址,要求文件系统读入文件的对应页大小进入文件系统缓存;
- 创建页表条目,映射用户的虚拟页到文件系统缓存的物理页面(图1的物理页0xFEDC),物理页面就是被访问文件的对应页;
- 最后,虚拟到物理的转换条目会被插入TLB(Translation Lookaside Buffer),应用继续处理需要的数据;
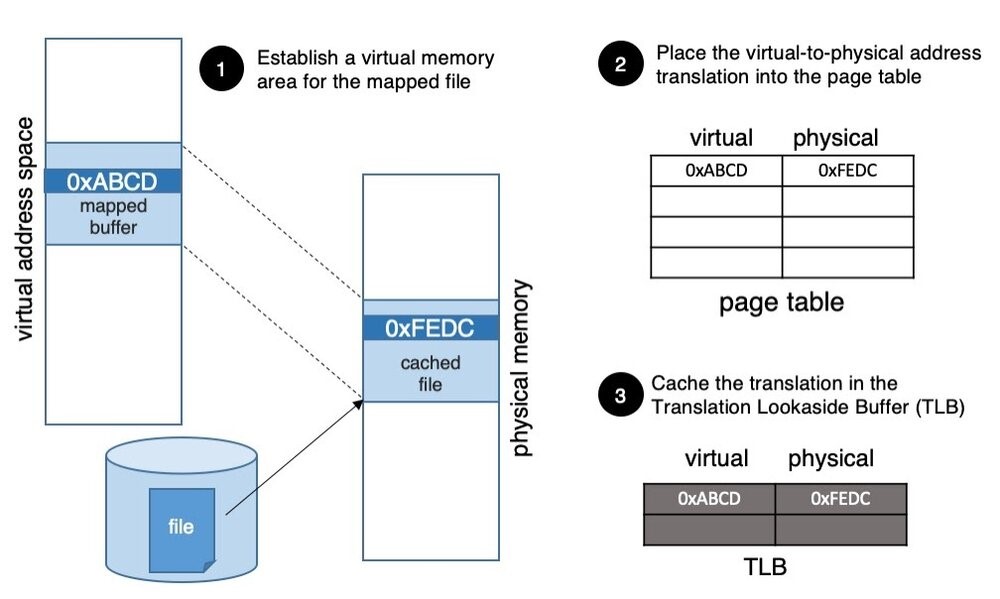
这就是内存映射文件的工作机制:
- 为映射的文件建立虚拟内存区;
- 把虚拟地址到物理地址的转换放于内存页表;
- 把同样的转换缓存在TLB中。
对于相同虚拟页的后续访问可能就不再需要操作系统的介入,是否需要取决于:
- 如果包含文件数据的物理页仍然在文件系统缓存中并且页表条目在TLB中,不需要操作系统介入,应用通过正常的load或者store指令访问数据;
- 如果包含文件数据的物理页仍然在文件系统缓存中,但在TLB中的转换条目已经不在了,那么硬件需要进入到内核态,重新在页表中搜寻条目并且再次加载到TLB中,之后应用才能够通过正常的load或者store指令访问数据;
- 更进一步,如果包含文件数据的物理页都已经不在文件系统缓存中,那么硬件会产生trap,操作系统会要求文件系统获取对应的文件数据,建立虚拟物理映射,放入页表,继续第2步的操作来访问数据。
和内存映射文件不同的是,系统调用syscall在每一次我们访问一个文件时都需要跨越用户态和内核态的边界。虽然在上面对于内存映射文件工作机制的描述中,第2和第3步也需要跨越用户态和内核态的边界,但即使如此,它所经历的路径也比系统调用效率更高。调用系统调用以及从系统调用中返回会增加内存映射文件方式所没有的CPU开销,参见第8点。更进一步地说,如果数据从内存映射区域拷贝到另一块应用的缓冲区,它可以使用经过高度优化基于AVX的memcpy实现方式。在系统调用中,当数据从内核态拷贝到用户空间时,内核只能使用较低效的实现方式,因为内核无法使用AVX寄存器。参见第8点。
预先分布文件空间(Pre-allocating file space)
内存映射文件允许我们在访问固定大小的文件时,很大程度上减少操作系统和文件系统的介入。如果文件增长,我们确实需要让文件系统介入。文件系统需要更新文件的元数据信息来反映增加后的大小并且确保这些更新被持久化,不会在主机崩溃时丢失。
确保持久化是非常昂贵的操作,因为每一个日志记录都必须保存到持久性存储上来确保他们不会在主机发生崩溃时丢失。如果我们一点点地扩展文件,就会导致这种开销经常出现,造成性能下降。这就是为什么SplitFS(参见6)和UCSD的作者(参见4)在应用扩展一个文件时要预先分配额外的空间。本质上,这就是批量处理文件系统的操作来降低开销。
我们的实现方式
我们对于WiredTiger做出的改变一直在2020年1月的开发版本中进行测试。到本文截稿,这些改变只在POSIX系统中采用,对于Windows的支持计划在未来发布。
固定大小映射文件区的情况
这部分不需要太多的代码改变。WiredTiger对于所有的文件相关操作提供了封装,所以我们只需要改变这些封装接口。打开文件时,我们调用mmap系统调用将文件映射到虚拟地址空间。随后读写文件而对于封装接口的调用将仅仅从映射区域拷贝需要访问的部分到提供的缓冲区中。
WiredTiger对于文件的扩展和缩小有3种方式。文件可以通过显式地调用fallocate系统调用进行扩展;也可以在写入到文件边界以外时隐式地扩展;文件可以通过truncate系统调用进行缩小。在最初的设计中我们禁止显式地扩展和缩小文件,这样不会影响WiredTiger的正确性。如果WiredTiger写入到了映射区域以外的地方,我们的封装接口函数就会切换到调用系统调用。如果WiredTiger读取到了文件中还没有映射的部分,我们也会使用系统调用来解决。
这种实现方式对于早期的产品原型是足够的,但对于在生产系统中使用则限制太大。
改变映射文件区域的大小
如前所述,这个特性最具技巧的地方是同步。让我们想像一下包含两个线程的场景,一个正在读取文件,而另一个正在缩小文件。在读取之前,第一个线程会检查映射区来确保它所读取的数据在映射区范围之内。如果在,它会继续从映射区拷贝数据。如果这时第二个线程在第一个线程拷贝数据之前缩小了文件,文件的大小现在小于了第一个线程所需访问数据的地址,那么第一个线程读取数据的尝试就会导致系统崩溃。这是因为映射区域要比缩小后的文件还要大,从映射区域拷贝数据的尝试已经超出了文件的边界,这会产生一个内存段错误。
防止这个问题发生的有效手段是每次在访问或者改变文件大小之前先获取一个锁。但这样会把IO操作串行化,从而导致性能急剧下降。我们使用一种受到RCU(read-copy-update)启发的无锁协议(参见第9点)。我们会把所有可能改变文件大小的线程称为写入者。因此,一个写入者可能是写入到文件边界之外,或者通过fallocate系统调用扩展文件,或者缩小文件的任何线程。而读取者则是任何读取文件的线程。
我们的解决方案工作机制是:一个写入者首先执行改变文件大小的操作并且重新映射文件到虚拟地址空间。在这个过程中其他任何人都不能够访问映射区域,无论是读取者还是写入者。但这样做并不妨碍IO操作的进行,当写入者正在调整映射区域时,我们可以将IO请求通过系统调用来进行。系统调用在内核中能够正确地和其他文件操作进行同步。
为了在不加锁的情况下达到目的,我们依赖于两个变量:
- mmap_resizing: 当写入者需要通知其他人它将要排他性地调整映射区域时,它原子地设置这个标志;
- mmap_use_count: 一个读取者在使用映射区域前会增加这个计数器,并在完成操作后递减。这个计数器告诉我们映射区域是否正在被使用。写入者需要等待,一直等到计数器归零。
- 在改变文件大小和映射区域之前,写入者执行prepare_remap_resize_file函数。它的伪代码如下。本质上,写入者一直等到没有人在改变映射区域大小,就会设置mmap_resizing来声明对于该操作的排他权限。然后写入者会等待所有读取者使用完毕映射区域,也就是mmap_use_count归零。
prepare_remap_resize_file:wait:/* wait until no one else is resizing the file */while(mmap_resizing != 0)spin_backoff(...);/* Atomically set the resizing flag, if this failsretry. */result = cas(mmap_resizing, 1, …);if(result) goto wait;/* Now that we set the resizing flag, wait for allreaders to finish using the buffer */while(mmap_use_count > 0)spin_backoff(...);
在执行prepare_remap_resize_file后,写入者执行改变文件大小的操作,取消映射,重新建立改变大小后的文件映射并且重置mmap_resizing。
被读取者执行的同步函数read_mmap伪代码如下:
read_mmap:/* Atomically increment the reference counter,* so noone unmaps the buffer while we use it. */atomic_add(mmap_use_count, 1);/* If the buffer is being resized, use the systemcall instead of the mapped buffer. */if(mmap_resizing)atomic_decr(mmap_use_count, 1);read_syscall(...);elsememcpy(dst_buffer, mapped_buffer, …);atomic_decr(mmap_use_count, 1);
需要注意的是,写文件的线程既要执行读取者的同步函数read_mmap,来决定他们是否可以使用映射区域进行IO操作;同时也需要执行写入者同步函数来决定是否写入超过了文件边界(因此需要扩展文件大小)。大家可以到WiredTigerdevelop branch来看完整的源码。
批量处理文件操作
前面提到,我们的设计受到UCSD研究的启发(参见第4点),通过预先分配大块的文件空间来批量化昂贵的文件系统操作。而WiredTiger在一定范围内已经采用了这个策略。我们在两种设置下进行试验:
- 在缺省设置下:WiredTiger使用fallocate系统调用来扩展文件;
- 在限制设置下:WiredTiger不允许使用fallocate,因此只能在写入超过文件边界时切换到隐式扩展。
我们在两种情况下采集了文件系统唤起的次数,发现在缺省设置下这个次数比限制模式下少了至少一个数量级。这告诉我们WiredTiger已经批处理了文件系统操作。至于调查批处理是否可以被优化以进一步提升性能我们计划将来再进行。
性能
为了测量我们做出的改变的影响,我们在WiredTiger基准测试包WTPERF上比较了mmap和develop分支的性能。WTPERF是一个可设置的基准测试工具,它可以模拟不同的数据组织形式,模式以及访问负载模式,支持所有的数据库设置。在65种负载下,mmap分支在19个场景中提升了性能。而在剩余的场景中,性能要么维持不变,要么只有非常微小的变化(在两个标准方差之内)。在两个负载下的性能变化(更新LSM)增加了几个百分点,除了这些,我们没有观察到任何使用mmap的坏处。
下面的图显示了mmap分支性能的提升百分比,这是针对mmap产生较好效果的19个基准测试。试验运行在Intel Xeon processor E5-2620 v4(8核),64GB内存,以及Intel Pro 6000p系列512GB SSD磁盘上。在所有的基准测试中,我们使用了缺省的设置,并且每个负载运行至少3次来确保结果是稳定和有效的。
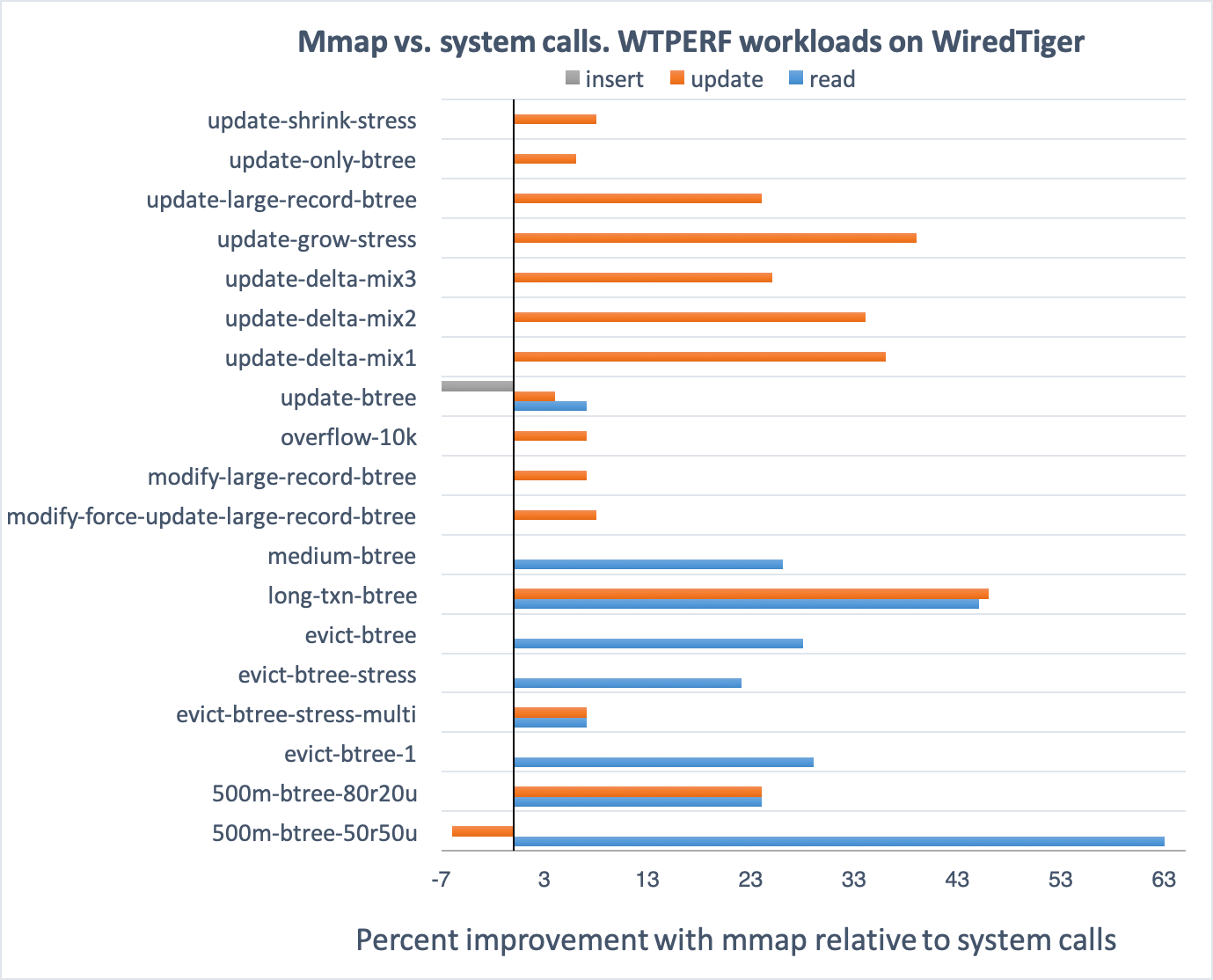
总的来讲,对于这些负载有非常明显的性能提升,但同时也有一些有趣的例外发现。对于500m-btree-50r50u以及update-btree操作(例如updates或者inserts)使用mmap会稍慢,但其他的操作,特别是读操作明显快了很多。看上去一些操作从mmap中获取的性能提升是用另外一些操作的性能下降换取的。我们还在调查为什么会发生这样的事情。
有一个变量可以很好地说明使用mmap带来的性能提升,那就是IO的吞吐量增加。例如,在500m-btree-50r50u负载下(这个负载模拟了典型的MongoDB负载),使用mmap后IO吞吐量比使用系统调用增加了30%。这个统计数据并没有解释所有事情,毕竟在这个负载下使用mmap后读吞吐量要比使用系统调用高出63%。这很有可能是归功于mmap相比系统调用更高效的代码路径,如在第8点中看到的。事实上,在使用mmap时,我们经常观察到更高的CPU使用率。
我们的实现方式
MongoDB官网原文链接:
https://engineering.mongodb.com/post/getting-storage-engines-ready-for-fast-storage-devices
Reference
[1] List of Intel SSDs. https://en.wikipedia.org/wiki/List_of_Intel_SSDs
[2] Optane DC PersistentMemory. https://www.intel.ca/content/www/ca/en/architecture-and-technology/optane-dc-persistent-memory.html
[3] Linux® Storage SystemAnalysis for e.MMC with Command Queuing, https://www.micron.com/-/media/client/global/documents/products/white-paper/linux_storage_system_analysis_emmc_command_queuing.pdf?la=en
[4] Jian Xu, Juno Kim,Amirsaman Memaripour, and Steven Swanson. 2019. Finding and Fixing PerformancePathologies in Persistent Memory Software Stacks. In 2019 Architectural Supportfor Program- ming Languages and Operating Systems (ASPLOS ’19). http://cseweb.ucsd.edu/~juk146/papers/ASPLOS2019-APP.pdf
[5] Jian Xu and StevenSwanson, NOVA: A Log-structured File System for Hybrid Volatile/Non-volatileMain Memories, 14th USENIX Conference on File and Storage Technologies(FAST’16). https://www.usenix.org/system/files/conference/fast16/fast16-papers-xu.pdf
[6] Rohan Kadekodi, Se KwonLee, Sanidhya Kashyap, Taesoo Kim, Aasheesh Kolli, and Vijay Chidambaram. 2019.SplitFS: reducing software overhead in file systems for persistent memory. InProceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP’19). https://www.cs.utexas.edu/~vijay/papers/sosp19-splitfs.pdf
[7] SDD vs HDD. https://www.enterprisestorageforum.com/storage-hardware/ssd-vs-hdd.html
[8] Why mmap is faster thansystem calls. https://medium.com/@sasha_f/why-mmap-is-faster-than-system-calls-24718e75ab37
[9] Paul McKinney. What is RCU, fundamentally? https://lwn.net/Articles/262464/

———————————————————————————
进入MongoDB技术交流群/投稿/合作 请添加社区助理小芒果微信 (ID:mongoingcom),添加请备注mongo



评论前必须登录!
注册