 MongoDB中文社区
MongoDB中文社区

MongoDB sharding 实例从3.4版本升级到 4.0版本 以后插入性能明显降低,观察日志发现大量的 insert 请求慢日志:
2020-08-19T16:40:46.563+0800 I COMMAND [conn1528] command sdb.sColl command: insert { insert: "sColl", xxx} ... locks: {Global: { acquireCount: { r: 6, w: 2 } }, Database: { acquireCount: { r: 2, w: 2 } }, Collection: { acquireCount: { r: 2, w: 2 }, acquireWaitCount: { r: 1 }, timeAcquiringMicros: { r: 2709634 } } } protocol:op_msg 2756ms
日志中可以看到 insert 请求执行获取 collection 上的 IS锁 2次,其中一次发生等待,等待时间为2.7s,这与 insert 请求执行时间保持一致。说明性能降低与锁等待有明显的相关性。
追溯日志发现 2.7s 前,系统正在进行 collection 元数据刷新(2.7s的时长与collection本身chunk较多相关):
2020-08-19T16:40:43.853+0800 I SH_REFR [ConfigServerCatalogCacheLoader-20] Refresh for collection sdb.sColl from version 25550573|83||5f59e113f7f9b49e704c227f to version 25550574|264||5f59e113f7f9b49e704c227f took 8676ms
2020-08-19T16:40:43.853+0800 I SHARDING [conn1527] Updating collection metadata for collection sdb.sColl from collection version: 25550573|83||5f59e113f7f9b49e704c227f, shard version: 25550573|72||5f59e113f7f9b49e704c227f to collection version: 25550574|264||5f59e113f7f9b49e704c227f, shard version: 25550574|248||5f59e113f7f9b49e704c227f
chunk 版本信息
首先,我们来理解下上文中的版本信息。在上文日志中看到,shard version 和 collection version 形式均为 「25550573|83||5f59e113f7f9b49e704c227f」,这即是一个 chunk version,通过 “|” 和 “||” 将版本信息分为三段:
- 第一段为 major version : 整数,用于辨识路由指向是否发生变化,以便各节点及时更新路由。比如在发生chunk 在 shard 之间迁移时会增加
- 第二段为 minor version : 整数,主要用于记录不影响路由指向的一些变化。比如chunk 发生 split 时增加
- 第三段为 epoch : objectID,标识集合的唯一实例,用于辨识集合是否发生了变化。只有当 collection 被 drop 或者 collection的shardKey发生refined时 会重新生成
shard version 为 sharded collection 在目标shard上最高的 chunk version
collection version 为 sharded collection 在所有shard上最高的 chunk version
下文 “路由更新触发场景” – “场景一:请求触发” 中就描述了使用 shard version 来触发路由更新的典型应用场景。
路由信息存储
// config.chunks{"_id" : "sdb.sColl-name_106.0","lastmod" : Timestamp(4, 2),"lastmodEpoch" : ObjectId("5f3ce659e6957ccdd6a56364"),"ns" : "sdb.sColl","min" : {"name" : 106},"max" : {"name" : 107},"shard" : "mongod8320","history" : [{"validAfter" : Timestamp(1598001590, 84),"shard" : "mongod8320"}]}
上面示例中记录的 document 表示该 chunk :
- 所属的 namespace 为 “sdb.sColl”,其 epoch 为 “5f3ce659e6957ccdd6a56364”
- chunk区间为 {“name”: 106} ~ {“name”: 107},chunk版本为 {major=4, minor=2},在 mongod8320 的shard上
- 同时记录了一些历史信息
路由更新触发场景
场景一:请求触发
mongos 收到客户端请求后,根据当前 CatalogCache 缓存中的路由信息,为客户端请求增加一个 「shardVersion」 的元信息。然后按照路由信息将请求分发到目标shard上。
{insert: "sCollName",documents: [ { _id: ObjectId('5f685824c800cd1689ca3be8'), name: xxxx } ],shardVersion: [ Timestamp(5, 1), ObjectId('5f3ce659e6957ccdd6a56364') ],$db: "sdb"}
shardServer 收到 mongos 发来的请求后,提取其中的 「shardVersion」 字段,并与本地存储的 「shardVersion」进行比较。比较二者 epoch & majorVersion 是否相同,相同则认为可以进行写入。如果版本不匹配,则抛出一个 StaleConfigInfo 异常。对于该异常,shardServer&mongos 均会进行处理,逻辑基本一致:如果本地路由信息是低版本的,则进行路由刷新。
场景二:特殊请求
- 一些命令执行一定会触发路由信息变化,比如 moveChunk
- 受其他节点行为影响,收到 forceRoutingTableRefresh 命令,强制刷新
- 一些行为必须要获取最新的路由信息,比如 cleanupOrphaned
路由刷新行为
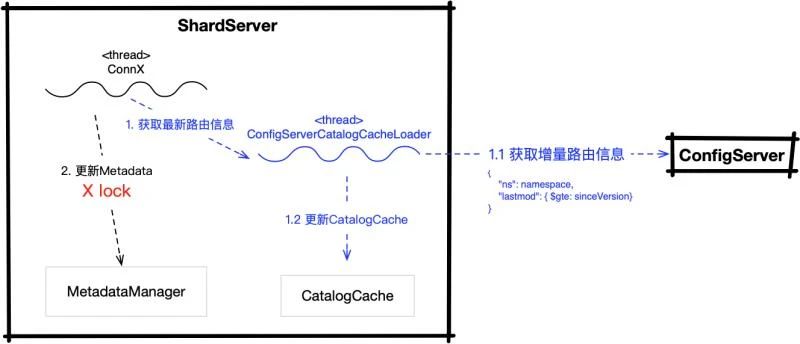
具体的刷新行为分为两步:
第一步:从config节点拉取权威的路由信息,并进行CatalogCache路由信息刷新。实际最终是通过 ConfigServerCatalogCacheLoader 线程来进行的,构造一个
{"ns": namespace,"lastmod": { $gte: sinceVersion}}
请求来获取路由信息。如果本地没有collection的路由信息,则会那么全量获取路由信息,sinceVersion = (0,0) ;否则只需增量获取路由信息, sinceVersion = 本地路由信息中最大的版本号,即 shard version。
ConfigServerCatalogCacheLoader 获得到路由信息以后,会刷新 CatalogCache中的路由信息,此时系统日志会打印上文中看到的:
2020-08-19T16:40:43.853+0800 I SH_REFR [ConfigServerCatalogCacheLoader-20] Refresh for collection sdb.sColl from version 25550573|83||5f59e113f7f9b49e704c227f to version 25550574|264||5f59e113f7f9b49e704c227f took 8676ms第二步:更新 MetadataManager(用于维护集合的元信息,并提供对部分场景获取一个一致性的路由信息等功能) 中的路由信息。更新 MetadataManager 时为了保证一致性,会给 collection 增加一个 X锁。更新过程中,系统日志会打印上文看到的第二条日志:
2020-08-19T16:40:43.853+0800 I SHARDING [conn1527] Updating collection metadata for collection sdb.sColl from collection version: 25550573|83||5f59e113f7f9b49e704c227f, shard version: 25550573|72||5f59e113f7f9b49e704c227f to collection version: 25550574|264||5f59e113f7f9b49e704c227f, shard version: 25550574|248||5f59e113f7f9b49e704c227f这里也即是文章开篇提到影响我们性能的日志,根因还是由于更新元信息的X锁导致。
3.6+版本对chunk version管理的变化
那么,为什么 3.4版本 没有问题,而到了 4.0版本 却发生了性能退化呢?这里直接给出答案:3.6&4.0的最新小版本当中,当shard进行 splitChunk 时,如果 shardVersion == collectionVersion ,则会增加 major version,进而触发路由刷新。而3.4版本中只会增加 minor version。这里首先来看下 splitChunk 的基本流程,随后我们再来详述为什么要做这样的改动。
splitChunk 流程

- 「auto-spliting触发」:在 4.0及以前的版本中,sharding实例的 auto-spliting 是由 mongos 来触发的。每次有写入请求时,mongos都会记录对应chunk的写入量,并判断是否要向 shardServer 下发一次 splitChunk 请求。判断标准:dataWrittenBytes >= maxChunkSize / 5(固定值)。
- 「splitVector + splitChunk」:向 chunk所在的shard 下发一个 splitVector 请求,获取对该chunk进行拆分的拆分点。该过程会根据索引进行一定的数据扫描及计算,详见:SplitVector命令。若 splitVector 获取到了具体的拆分点,则再次向 chunk所在的shard 下发一个 splitChunk 请求,进行实际的拆分。
- 「_configsvrCommitChunkSplit」:shardServer 收到 splitChunk 请求后,首先获取一个分布式锁,然后向 configServer 下发一个 _configsvrCommitChunkSplit。configServer 收到该请求后进行数据更新,完成splitChunk,过程中会有 chunk 版本信息的变化。
- 「route refresh」:上述流程正常完成后,mongos进行路由刷新。
splitChunk 时,chunk version变化
在SERVER-41480中,对splitChunk时,chunk version版本管理进行了调整
在3.4版本以及3.6、4.0较早的小版本中,「_configsvrCommitChunkSplit」 只会增加 chunk 的minor version。
The original reasoning for this was to prevent unnecessary routing table refreshes on the routers, which don’t ordinarily need to know about chunk splits (since they don’t change targeting information).
根本原因是为了保护 mongos 不做必须要的路由刷新,因为 splitChunk 并不会改变路由目标,所以 mongos 不需要感知。
但是只进行小版本的自增,如果用户进行单调递增的写入,容易造成较大的性能开销。
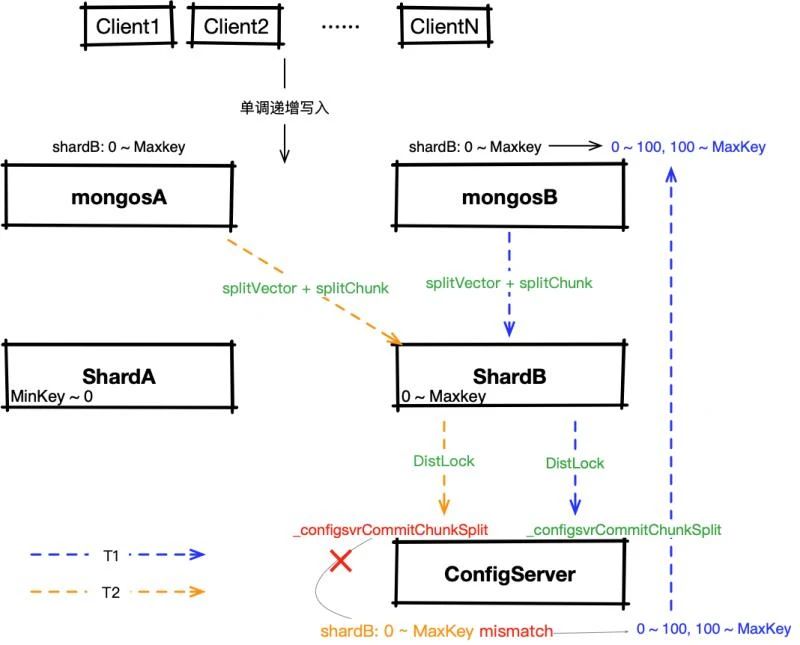
假设 sharding实例有2个mongos:mongosA、mongosB,2个shard:shardA(chunkRange: MinKey ~ 0),shardB(chunkRange: 0 ~ Maxkey)。用户持续单调递增写入。
- T1时刻:mongosB首先判断chunk满足「auto-spliting触发」 条件,向 shardB 发送「splitVector + splitChunk」,在请求正常结束后,mongosB触发路由刷新。此时,shardB 的 chunkRange 为 0 ~ 100,100 ~ Maxkey。
- 随后在一定时间内(比如T2时刻),mongosB无法满足「auto-spliting触发」 条件,而mongosA持续判断满足条件,向shardB发送 「splitVector + splitChunk」,但最终在「_configsvrCommitChunkSplit」步骤,由于 mongosA 的路由表不是最新的,所以无法按照其请求将 0 ~ Maxkey 进行拆分,最终无法成功执行。由于整个流程没有完整结束,所以 mongosA 也无法进行 路由表更新,则在这段时间内持续会有这样的无效请求。
而如上文描述的,splitVector 根据索引进行一定的数据扫描、计算,splitChunk 会获取分布式锁,均为耗时较高的请求,所以这种场景对性能的影响不可忽视。
在 SERVER-41480中对上述问题进行修复,修复的方式是如果 shardVersion == collectionVersion (即 collection上次的 chunk split 也发生在该shard上) ,则会增加 major version,以触发各节点路由的刷新。修复的版本为3.6.15, 4.0.13, 4.3.1, 4.2.2。
而这个修复则导致了开篇我们遇到的问题,确切些来说,任何在 shardVersion == collectionVersion 的 shard 上进行 split 操作都会导致全局路由的刷新。
官方修复
SERVER-49233 中对这个问题进行了详细的阐述:
we chose a solution, which erred on the side of correctness, with the reasoning that on most systems auto-splits are happening rarely and are not happening at the same time across all shards.
我们选择的方案,宁可过于注重正确性(SERVER-41480),理由是在大多数的系统中,auto-split很少发生,而且不会同时在所有shard上发生。
However, this logic seems to be causing more harm than good in the case of almost uniform writes across all chunks. If it is the case that all shards are doing splits almost in unison, under this fix there will constantly be a bump in the collection version, which means constant stalls due to StaleShardVersion.
然而,在对所有chunk进行均衡写入的情况下,这个逻辑似乎弊大于利。如果这种场景下,所有的shard同时进行split,那么在 SERVER-41480 修复下,collection version 将不断出现颠簸,也就意味着不断由于 StaleShardVersion 而导致不断暂停。
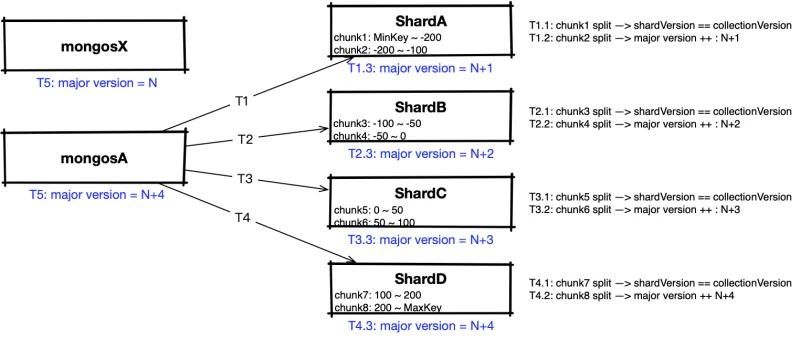
举例来详细说明下这个问题:假设某sharding实例有4个shard,各持有2个chunk,当前时刻major version=N。客户端对sharding实例的所有chunk进行均衡的写入,某时刻mongosA判断所有chunk符合split条件,依次对各shard进行连续的 split chunk 触发。为了便于说明,假设如图所示,在T1,T2,T3,T4时刻,依次在ShardA、shardB、shardC、shardD进行连续的chunk split触发,那么:
- T1.1时刻 chunk1 发生 split,使得 shardA 的 shardVersion == collection;T1.2时刻 chunk2 发生 split,触发 configServer major version ++ ,此时最新的major version=N+1;随后的T1.3时刻,shardA感知后刷新本地major version=N+1
- 随后的T2、T3、T4时刻依次发生上述流程。
- 最终在T5时刻,mongosA 在触发完split chunk后主动刷新路由表,感知major version = N+4
那么当系统中另外一个mongos(未发生更新,路由表中major version=N)向shard(比如shardB)发送请求时:
- 在第一次请求交互后,mongosX感知自身major version落后,与configServer交互,更新本地路由表后下发第二次请求
- 第二次请求中,shardB感知自身major version落后,通过configServer拉取并更新路由表
- 在第三次请求中,双方均获得最新的路由表,而完成此次请求
- mongos&shard之间感知路由表落后靠请求交互时的 StaleShardVersion 来完成,而路由表更新的过程中,所有需要依赖该集合路由表完成的请求,都需要等待路由表更新完成后才能继续。所以上述过程即jira中描述的:不断由于 StaleShardVersion 而导致不断暂停。
同时 SERVER-49233 提供了具体的解决方案,在 3.6.19、4.0.20、4.2.9 及后续的版本中,提供 incrementChunkMajorVersionOnChunkSplit 参数, 默认为 false(即 splitChunk 不会增加major version),可在配置文件或者通过启动setParameter的方式设置为true。
而由于 auto-spliting 逻辑在 4.2版本 修改为在 shardServer 上触发(SERVER-34448), 也就不会再有 mongos 频繁下发无效 splitChunk 的场景。所以对于 4.4 版本,SERVER-49433 直接将增加 major version 的逻辑回滚掉,只会增加 minor version。(4.2版本由于中间版本提供了 major version 逻辑,所以提供 incrementChunkMajorVersionOnChunkSplit 来让用户选择)
这里对各版本行为总结如下:
- 只会增加 minor version:3.4所有版本、3.6.15 之前的版本、4.0.13之前的版本、4.2.2之前的版本、4.4(暂未发布)
- shardVersion == collectionVersion 会增加 major version,否则增加minor version:3.6.15~ 3.6.18(包含)之间的版本、4.0.13 ~ 4.0.19(包含)之间的版本、4.2.2 ~ 4.2.8(包含)之间的版本
- 提供 incrementChunkMajorVersionOnChunkSplit 参数,默认只增加 minor version:3.6.19及后续版本、4.0.20及后续版本、4.2.9及后续版本
使用场景与解决方案
| MongoDB版本 | 使用场景 | 修复方案 |
|---|---|---|
| 4.2以下 | 数据写入固定在某些Shard | 采用可以增加major version的版本(或设置 incrementChunkMajorVersionOnChunkSplit = true) |
| 4.2以下 | 数据在shard之间写入较均衡 | 采用仅增加minor version的版本(或设置 incrementChunkMajorVersionOnChunkSplit = false) |
| 4.2 | 所有场景 | 采用仅增加minor version的版本(或设置 incrementChunkMajorVersionOnChunkSplit = false) |
阿里云MongoDB 4.2版本中已经跟进了官方修复。遇到该问题的用户可以将实例升级到4.2的最新小版本,而后按需配置incrementChunkMajorVersionOnChunkSplit即可。
更多文章:




MongoDB中文手册翻译正在进行中,欢迎更多朋友在自己的空闲时间学习并进行文档翻译,您的翻译将由社区专家进行审阅,并拥有署名权更新到中文用户手册和发布到社区微信内容平台。点击下方图片即可领取翻译任务——

更多问题可以添加社区助理小芒果微信(mongoingcom)咨询,进入社区微信交流群请备注“mongo”。

长按二维码关注我们



感谢分享!