 MongoDB中文社区
MongoDB中文社区
背景
MongoDB内核代码中提供有完善的gotool工具,这些开源工具作用主要有:数据导出及恢复(mongodump、mongorestore、mongoexport、mongoimport)工具、客户端shell链接工具(mongo)、IO测试工具(mongoperf)、流量qps/时延等监控统计工具(mongostat、mongotop)。
MongoDB默认只提供mongostat和mongotop工具来完成流量和时延统计,这两个工具的主要功能如下:
- mongostat:监控整个集群的qps统计信息
- mongotop:监控表级的读写时延统计信息
问题:
问题一:mongostat可以监控整个集群的qps信息,但是表级的qps信息如何监控?例如如果某一时刻读写流量突然暴涨引起集群抖动,怎么知道是那个具体的表引起?
问题二:mongotop可以获取整个表的读写时延消耗,如果某个表写时延很高,我们如何快速定位写时延高具体由增、删、改操作中的那个操作引起?
显然,mongostat和mongotop满足不了我们怼上面的两个问题的需求。实际上,MongoDB内部实现上提供有对应的表级别qps和表级别时延统计接口,拿到这些接口统计后,我们就可以快速获取对应的数据结果,本文讲分析表级统计的实现原理及核心代码实现。
1. mongostat、mongotop监控统计信息
MongoDB官方对外开源的qps及时延监控主要有mongostat和mongotop,本章节分析这两个工具的用法及监控项。
1.1 mongostat监控统计
MongoDB提供了mongostat工具来监控当前集群的各种操作统计。Mongostat监控统计如下图所示:

其中,insert、delete、update、query这四项统计比较好理解,分别对应增、删、改、查,getMore记录批量拉数据时候的游标操作统计,command统计在mongos和mongod中有不同的涵义,具体参考:MongoDB内核源码实现、性能调优、最佳运维实践系列-command命令处理模块源码实现三https://zhuanlan.zhihu.com/p/308428327
mongostat help参数功能详细说明如下:
| 参数项 | 功能说明 |
|---|---|
| general options: | 获取版本信息、help帮助信息 |
| verbosity options: | 是否打印日志信息,-v表示打印日志,v个数越多日志打印越多 quiet默认不答应日志 |
| connection options: | 链接的mongo实例ip:port地址 |
| ssl options: | SSL认证相关配置 |
| authentication options: | 鉴权认证的用户名和密码 |
| uri options: | uri链接认证方式,类似MongoDB://username1:password1@ip:port |
| stat options: | 统计选项设置: –discover:如果链接的是复制集节点,则输出整个复制集所有节点监控信息;如果 链接的是代理mongos节点,则输出整个分片集群节点监控信息。 -n:一共输出多少行即停止监控输出,默认没限制 –json:指定输出个数为json格式 -i: 直接同一个屏幕显示统计信息,屏幕刷新周期就是-i指定的时间 –humanReadable:是否进行字节到M或者K等的转换,默认true |
1.2 mongotop监控统计
mongotop实现对所有表的读写时延消耗统计,并按照总耗时排序直观输出,对应统计打印信息如下图所示:

mongotop监控输出项各字段说明如下:
- ns: 表名
- read:1秒钟内客户端对该表读操作消耗的总时间
- write:1秒钟内客户端对该表写操作消耗的总时间
- total:1秒钟内客户端对该表读写消耗的总时间
mongotop工具help参数信息说明如下表所示:
| 参数项 | 功能说明 |
|---|---|
| general options: | 获取版本信息、help帮助信息 |
| verbosity options: | 是否打印日志信息,-v表示打印日志,v个数越多日志打印越多 quiet默认不答应日志 |
| connection options: | 链接的mongo实例ip:port地址 |
| ssl options: | SSL认证相关配置 |
| authentication options: | 鉴权认证的用户名和密码 |
| uri options: | uri链接认证方式,类似MongoDB://username1:password1@ip:port |
| stat options: | 统计选项设置: -n:一共输出多少行即停止监控输出,默认没限制 –json:指定输出个数为json格式 |
2. 表级详细操作统计及其时延监控统计
mongod实例会对表级别的增、删、改、查、getMore、command进行详细的操作统计,并对每种操作的时延进行统计。每个表都拥有一个CollectionData结构,该结构中存储所有操作统计和时延统计;同一个操作的qps统计和时延统计通过UsageData结构实现,包含count和time两个成员。
2.1 表级统计实现原理
详细的表级统计通过以下几个类结构分层实现:
- 全局UsageMap表
UsageMap是一个StringMap表结构,该map表中的成员类型为CollectionData,一个CollectionData对应一个表名及其该表的各自详细qps和时延统计信息,核心代码定义如下:
typedef StringMap<CollectionData> UsageMap;
- CollectionData表统计信息
CollectionData结构中包含多个成员,包含了三个维度的统计,每个维度中的成员对应一个操作统计项,统计维度及其操作类型如下表:
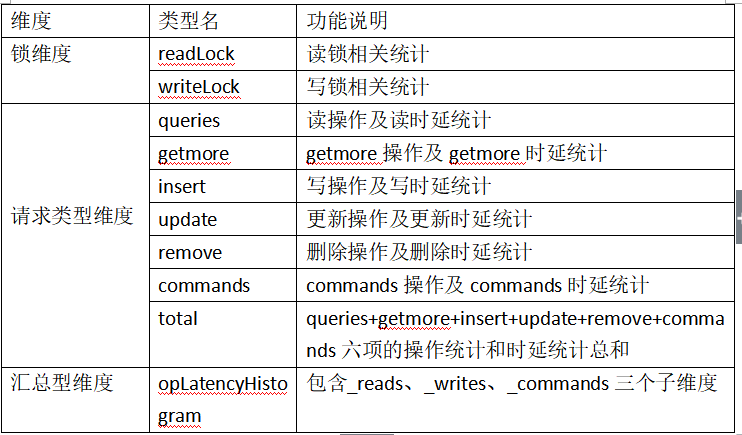
- UsageData
UsageData完成上面的锁维度和请求类型维度的操作计数和时延计数,UsageData包含count和time两个成员,分别用于操作计数和时延计数。
- OperationLatencyHistogram表级汇总型统计
OperationLatencyHistogram实现表级别的操作汇总计数和汇总型时延统计,在该汇总型统计中把请求类型维度中的六项操作(queries、getmore、insert、update、remove、commands)合并汇总为三项统计:reads、writes、_commands。
2.2 核心代码实现
MongoDB表级详细统计实现主要由src/mongo/db/stats/目录中的top.cpp、top.h、operation_latency_histogram.cpp、operation_latency_histogram.h四个文件完成。
2.2.1 核心数据结构实现
核心数据结构代码实现如下:
写入多个分片。预分片的好处可以规避非预分片情况下的chunk迁移问题,最大化提升写入性能。
class Top {......//map表中每个表占用一个struct CollectionData {......//锁维度UsageData readLock;UsageData writeLock;//表级别不同操作的时延统计,粒度相比OperationLatencyHistogram更小//请求类型维度,包含增、删、改、查、getMore、command六类UsageData queries;UsageData getmore;UsageData insert;UsageData update;UsageData remove;UsageData commands;//总的,上面的[queries,commands]UsageData total;//汇总型维度,包含读、写、command三个维度OperationLatencyHistogram opLatencyHistogram;};//锁类型,读锁还是写锁enum class LockType {ReadLocked,WriteLocked,NotLocked,};//Top._usage 各种命令的详细统计记录在该map表中//map表中每个表占用一个,参考Top::recordtypedef StringMap<CollectionData> UsageMap;public://全局UsageMap表,表中每个成员对应一个collection表UsageMap _usage;......}
从上面的核心算法可以看出,UsageMap 为map表结构,包含有所有表名及其对应的表级请求统计和时延统计,每个表的所有统计记录到struct CollectionData {} 结构中。
CollectionData 结构中的成员可以分为三类:锁统计、详细请求统计、汇总型统计,其中汇总型统计由class OperationLatencyHistogram {}类实现,核心成员如下:
class OperationLatencyHistogram {......private://可以用于记录历史统计,通过buckets来区分,最大可以记录kMaxBuckets个历史统计信息struct HistogramData {std::array<uint64_t, kMaxBuckets> buckets{};uint64_t entryCount = 0;uint64_t sum = 0;};......HistogramData _reads, _writes, _commands;}
2.2.2 核心算法实现
按照不同的维度,表级详细统计核心算法实现可以包含:锁及请求类型详细统计算法实现、汇总型表级详细统计算法实现。
- 锁类型统计和请求类型详细统计核心算法实现
MongoDB按照不同统计维度,同一个请求可以归纳到不同锁类型,同时也可以归纳到不同请求类型。例如,db.test.find({xxx})这个查询,在对test表详细统计的时候,该查询会同时对该表的读锁readLock统计及queries统计进行计数,也就是会同时记录该操作锁操作计数和查询操作计数。
锁类型统计及请求类型表级统计核心算法实现如下:
1. 找出对应表统计存储结构CollectionData
void Top::record(...) {......//根据表名从Map表种找到该表在表中对应hash位置auto hashedNs = UsageMap::HashedKey(ns);stdx::lock_guard<SimpleMutex> lk(_lock);//如果ns是已经删除的表,直接返回if ((command || logicalOp == LogicalOp::opQuery) && ns == _lastDropped) {_lastDropped = "";return;}//找到改表对应的CollectionDataCollectionData& coll = _usage[hashedNs];//开始表级计数统计_record(opCtx, coll, logicalOp, lockType, micros, readWriteType);}
2. 对该表进行真正的计数统计操作
//Top::record**调用 各个命令的op及时延统计**void Top::_record(...) {//**汇总型详细表级统计**_incrementHistogram(opCtx, micros, &c.opLatencyHistogram, readWriteType);//**该表总时延计数,包括增删改查getMore command六项** 及其他所有的统计c.total.inc(micros);//**写锁计数**if (lockType == LockType::WriteLocked)c.writeLock.inc(micros);//**读锁计数**else if (lockType == LockType::ReadLocked)c.readLock.inc(micros);//**详细增 删 改 查 getMore command统计及时延**switch (logicalOp) {//**无效类型**case LogicalOp::opInvalid:// use 0 for unknown, non-specificbreak;case LogicalOp::opUpdate: //**增**c.update.inc(micros);break;case LogicalOp::opInsert: //**插入**c.insert.inc(micros);break;case LogicalOp::opQuery: //**查询**c.queries.inc(micros);break;case LogicalOp::opGetMore: //getMore**游标**c.getmore.inc(micros);break;case LogicalOp::opDelete: //**删除**c.remove.inc(micros);break;case LogicalOp::opKillCursors: //break;case LogicalOp::opCommand:c.commands.inc(micros);break;default:MONGO_UNREACHABLE;}}
- 表级汇总型操作及时延统计
汇总型操作详细统计主要实现读、写、command操作统计及对应时延统计,这类操作核心代码实现如下:
1. 按照不同操作分类
//不同请求归类参考getReadWriteType//Top::_incrementHistogram 操作和时延计数操作void OperationLatencyHistogram::increment(uint64_t latency, Command::ReadWriteType type) {//确定latency时延对应在[0-2]、(2-4]、(4-8]、(8-16]、(16-32]、(32-64]、(64-128]...中的那个区间int bucket = _getBucket(latency);switch (type) {//读时延累加,操作计数自增case Command::ReadWriteType::kRead:incrementData(latency, bucket, &reads);break;//写时延累加,操作计数自增case Command::ReadWriteType::kWrite:incrementData(latency, bucket, &writes);break;//command时延累加,操作计数自增case Command::ReadWriteType::kCommand:incrementData(latency, bucket, &commands);break;default:MONGO_UNREACHABLE;}}
2. 对应分类操作计数、时延计数
//OperationLatencyHistogram::increment中调用//读 写 command总操作自增,时延对应增加latencyvoid OperationLatencyHistogram::_incrementData(uint64_t latency, int bucket, HistogramData* data) {//落在bucket桶指定时延范围的对应操作数自增data->buckets[bucket]++;//该操作总计数data->entryCount++;//该操作总时延计数data->sum += latency;}
3. 时延范围分区桶统计
MongoDB进行汇总型操作及时延统计后,可以获取总体的读、写、command平均时延,但是无法获取例如最大时延、95%分位时延、99分位时延等。MongoDB为了满足这些需求,同时降低代码实现难度,通过分区时延统计来满足业务的这些需求。
时延范围分区桶实现原理:根据时延值,按照如下时延范围和分区桶得对应关系来完成统计操作,时延和桶的对应关系如下图所示:

时延范围分区桶核心算法实现核心代码实现如下:
//桶计数void OperationLatencyHistogram::_incrementData(uint64_t latency, int bucket, HistogramData* data) {//落在bucket桶指定时延范围的对应操作数自增data->buckets[bucket]++;......}//不同请求归类参考getReadWriteType//Top::_incrementHistogram 操作和时延计数操作void OperationLatencyHistogram::increment(uint64_t latency, Command::ReadWriteType type) {//确定latency时延对应在[0-2]、(2-4]、(4-8]、(8-16]、(16-32]、(32-64]、(64-128]...中的那个区间int bucket = _getBucket(latency);switch (type) {//读时延累加,操作计数自增case Command::ReadWriteType::kRead:incrementData(latency, bucket, &reads);break;//写时延累加,操作计数自增case Command::ReadWriteType::kWrite:incrementData(latency, bucket, &writes);break;//command时延累加,操作计数自增case Command::ReadWriteType::kCommand:incrementData(latency, bucket, &commands);break;default:MONGO_UNREACHABLE;}}
从上面的代码可以看出,汇总型统计中的读、写、command操作统计及时延统计包含该请求类型中的所有时延范围分区桶统计,已下图中的collection表read统计为例:
1. reads.ops=reads.histogram[]数组count之和
2. histogram.micros代表时延范围分区桶的时延边界值,例如2、4、8、16,以此类推。

3. 表级详细统计对外接口
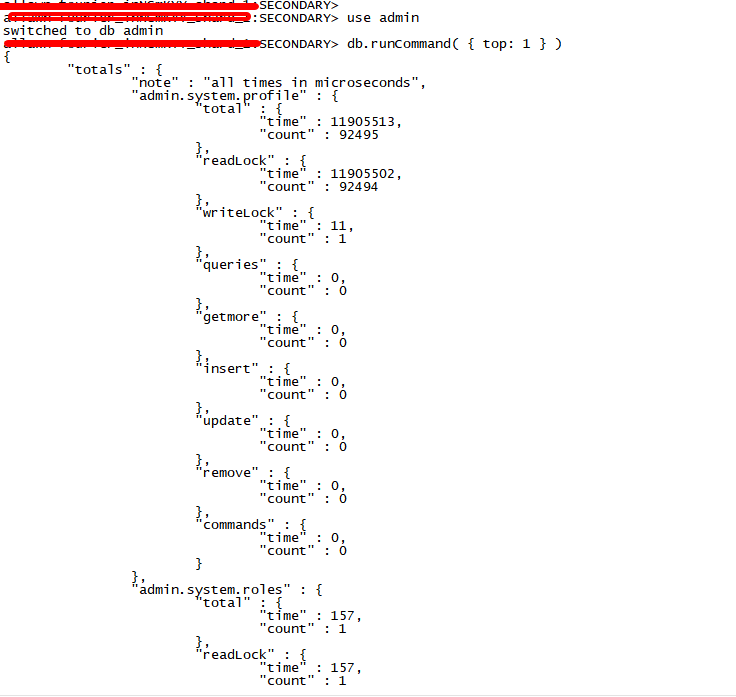
3.1 表级别锁维度及请求类型维度相关统计接口
表级别锁维度及请求类型维度相关统计对外接口可以通过下面的命令获取得到(注:只能在mongod实例执行):
use admin
db.runCommand( { top: 1 } )
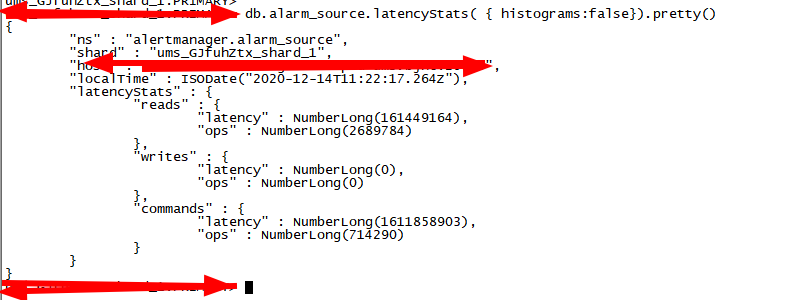
3.2 汇总型表级别统计
表级别汇总型读、写、command相关操作及时延统计可以通过如下命令获取:
db.collection.latencyStats( { histograms:false}).pretty()
不同时间段对应有那些操作,例如那些操作时延比较高,可以通过时延范围分区桶统计接口获取:

更多文章:
MongoDB Command命令处理模块源码实现一https://mp.weixin.qq.com/s/66dKYHGiIq3KXqSGo7oM5g
MongoDB Command命令处理模块源码实现二https://mp.weixin.qq.com/s/9NEmBFitapKMN4d3mMCz-w
常用高并发网络线程模型设计及MongoDB线程模型优化实践https://mp.weixin.qq.com/s/rdnu90ICRXQBZM9eXqSDRQ
MongoDB网络传输处理源码实现及性能调优-体验内核性能极致设计https://mp.weixin.qq.com/s/SzQiOfzsCj8JkorhI7CsEA
OPPO百万级高并发MongoDB集群性能数十倍提升优化实践https://mp.weixin.qq.com/s/FL1dnmqE6LySYMMxxoPp9Q
盘点 2020 | 我要为分布式数据库 MongoDB 在国内影响力提升及推广做点事https://mp.weixin.qq.com/s/9Totvf5fc2awI5l5oIYvEA
MongoDB网络传输层模块源码实现二
https://mp.weixin.qq.com/s/CGjUICVh3D6-J5xa4C_PTA
MongoDB网络传输层模块源码实现三
https://mp.weixin.qq.com/s/s4Lo6eLd4VHshWeBWuSO3w
MongoDB网络传输层模块源码实现四
https://mp.weixin.qq.com/s/Xm6lxwWvesCdV0ICyKKVsA

作者:杨亚洲
前滴滴出行技术专家,现任OPPO文档数据库MongoDB负责人,负责oppo千万级峰值TPS/十万亿级数据量文档数据库MongoDB内核研发及运维工作,一直专注于分布式缓存、高性能服务端、数据库、中间件等相关研发。Github账号地址:

来这里,点亮自己!
MongoDB中文社区北京大会将于7月31日(周六)在北京市朝阳区举办,点击报名:https://sourl.cn/fWyXBY
加入MongoDB北京交流群:添加小芒果微信,并备注:mongo北京
MongoDB中文社区技术大会议题征集中,打开链接来这里分享经验与见解——
活动资料发布消息订阅:
报名MongoDB免费线上培训:
我们还将继续在上海广州深圳南京等城市举办技术大会,有合作意向请提前联系小芒果微信或社区核心成员。

MongoDB-全球领先的现代通用数据库
点击访问MongoDB官网www.mongodb.com/zh

Tapdata-异构数据库实时同步工具
点击访问Tapdata官网https://tapdata.net/

Mongoing中文社区
MongoDB中文社区微信公众号
扫描关注,获取更多精彩内容
社区网站www.mongoing.com
长按二维码关注我们



评论前必须登录!
注册