 MongoDB中文社区
MongoDB中文社区
1. 业务迁移背景
2. 为何选择MongoDB-附十大核心优势总结
|
|
|
|
|
|
|
|
|
|
|
|
- 分布式事务支持
3. MongoDB资源评估及部署架构
3.1 MongoDB资源评估
- 内存评估
- 分片评估
- 磁盘评估
- CPU规格评估
- mongos代理及config server规格评估
|
|
|
|
|
|
|
|
|
|
|
|
3.2 集群部署架构

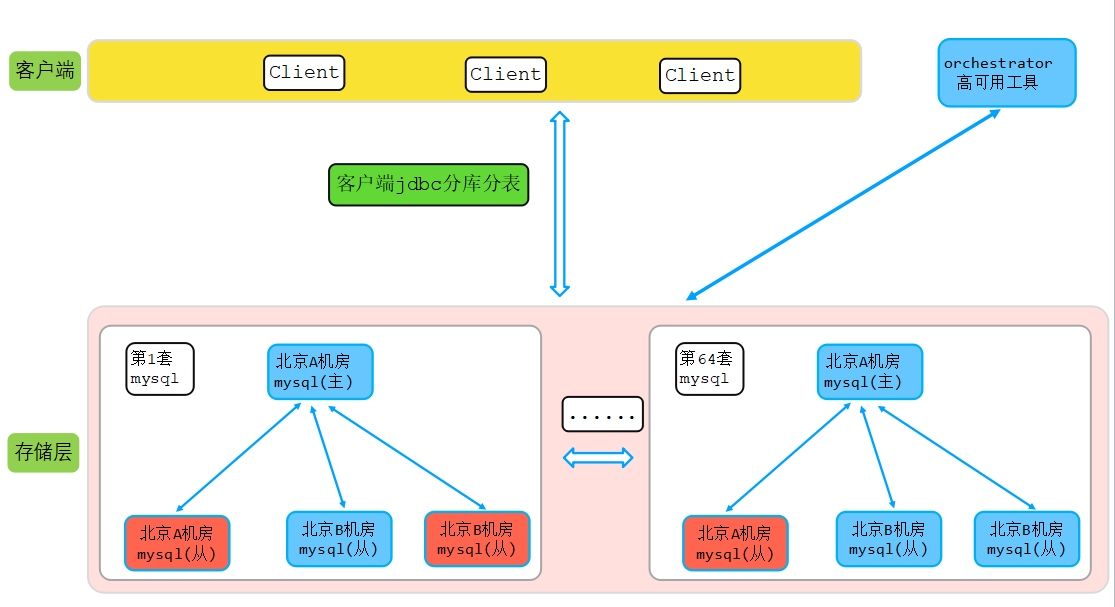
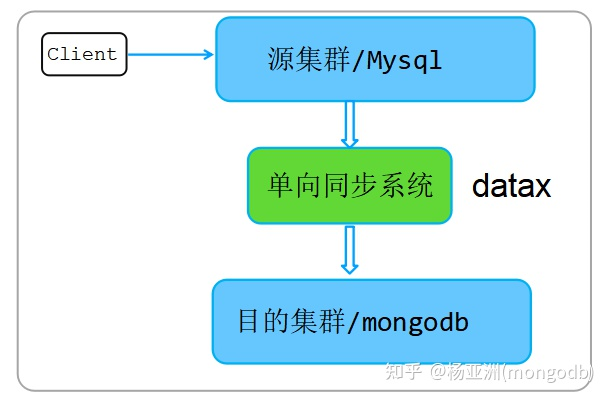
4. 业务全量+增量迁移方式
5. 性能优化过程
5.1 数据迁移开始前的提前预操作
- 分片方式
- 预分片
- 就近读
- mongos代理配置
- 禁用enableMajorityReadConcern
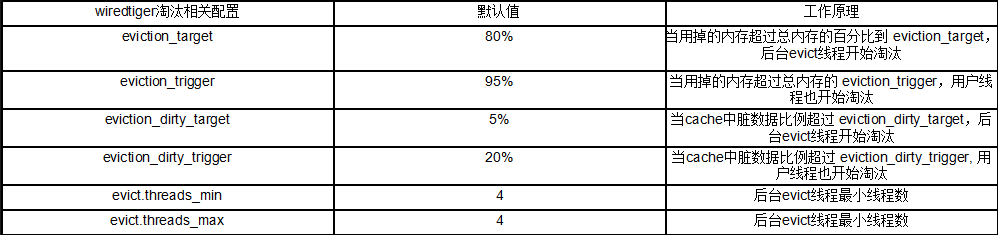
- 存储引擎cacheSize规格选择
5.2 数据全量迁移过程中优化过程
5.3 全量迁移完成后,业务流量读写优化
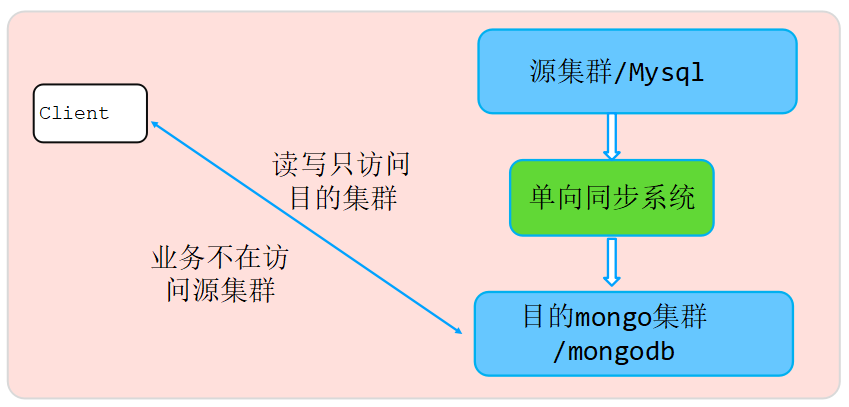
- 节点cacheSize从之前的42G调整到55G,尽量多的缓存热点数据到内存,供业务读,最大化提升读性能。
- 每天凌晨低峰期做一次cache内存加速释放,避免OOM。
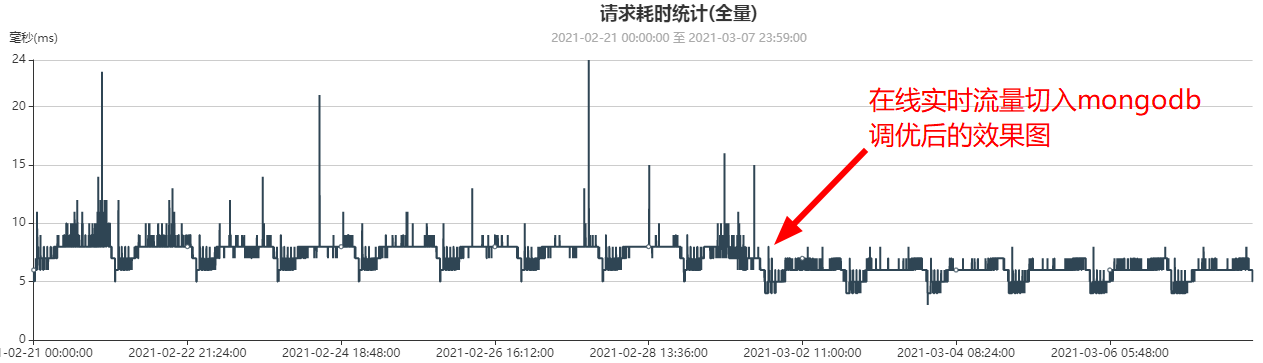
6. 迁移前后,业务测时延统计对比(MySQL vs MongoDB)
6.1 性能收益对比
- 迁移前业务测时延监控曲线(平均时延7ms, 2月1日数据,此时MySQL集群只有300亿数据):

- 迁移MongoDB后并且业务流量全部切到MongoDB后业务测时延监控曲线(平均6ms, 3月6日数据,此时MongoDB集群已有约500亿数据)

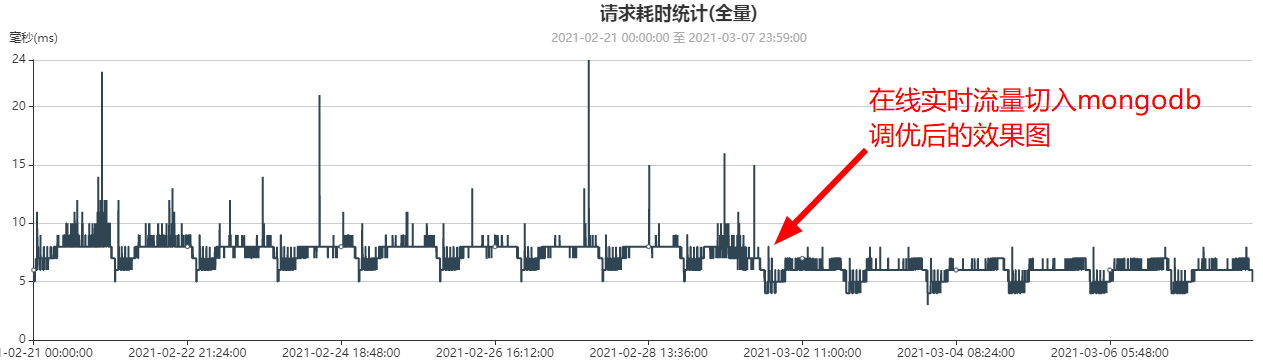
- MySQL(300亿数据)时延:7ms
- MongoDB(500亿数据)时延:6ms
6.2 性能质疑解答

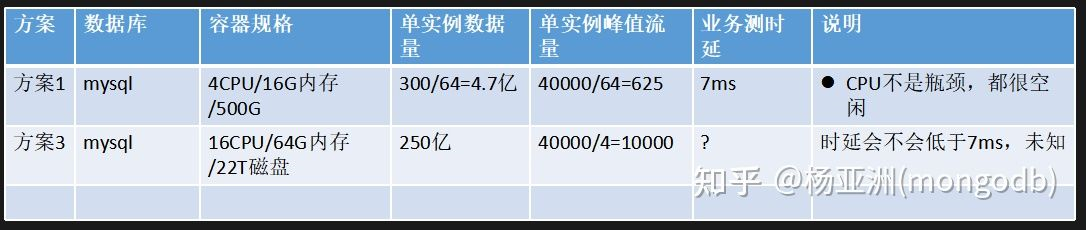
7. 迁移成本收益对比
7.1 MySQL集群规格及存储数据最大量
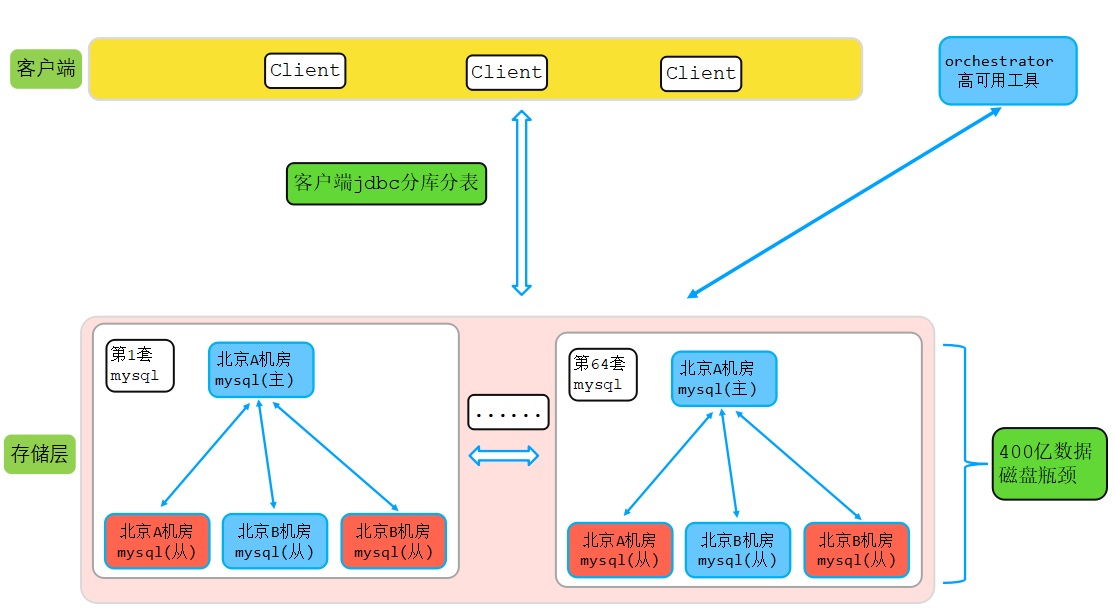
7.2 MongoDB集群规格及存储数据最大量

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
7.4 收益总结(客观性对比)
- CPU/内存节省原因:
- 磁盘节省原因:
8. 最后:千亿级规模MongoDB集群注意事项
9. 未来挑战(该集群未来万亿级实时数据规模挑战)
- 但是,IOT业务数据存在明显的冷数问题,一年前的数据用户基本上不会访问,因此我们考虑做如下优后来满足性能、成本的进一步提升:冷数据归档到低成本SATA盘;
- 冷数据提升压缩比,最大化减少磁盘消耗;
- 如何解决冷数据归档sata盘过程中的性能问题。
10. 最后说明(业务场景)
阅读更多:
记一次十亿级时延敏感集群加索引引起的业务抖动及快速恢复方法

作者:杨亚洲
![]()
点击访问MongoDB官网www.mongodb.com/zh
![]()
Tapdata DaaS – 一站式实时数据服务平台 (tapdata.net)

Mongoing中文社区
MongoDB中文社区微信公众号
扫描关注,获取更多精彩内容
社区网站www.mongoing.com



你好,我们现在的iot数据也使用mongodb做存储,但是在使用过程中经常会出现集群内存不够用的情况。
文中提到的"每天凌晨低峰期做一次cache内存加速释放,避免OOM",我们现有的办法就是监控集群状态,在内存占用高的时候,就对集群分片重启,所以想问下您说的内存释放方法。
另外对mongo cacheSize的设置,只能限制wiredTiger本身的内存使用,高频的读写情景,mongo server还是会将数据load到内存,最终导致OOM。
您好,请教下mongo中字段太多对mongo影响大吗 使用对象嵌套数组的方式可以避免字段过多的问题么