 MongoDB中文社区
MongoDB中文社区
之前我们阅读了OPPO文档数据库mongodb负责人杨亚洲老师2020年分享干货-万亿级数据库MongoDB集群性能优化实践合辑(上),本次我们分享来自答疑内容核心18问,包括内容如下:
- 性能优化有推荐的分析和监控工具么?
- 会话加标签是怎么指定服务器?
- 脏数据比例多少算高?
- 写分开会有时延吗,是不是有一致性问题?
- 如何定位详细的慢查询呢?
- 如何快速定位MongoDB的问题发生在集群中的哪些节点?在启用读写分离的情况下?
- 如何保证MongoDB 的安全性呢?
- mysql和mongodb双写的话怎么保证事务呢?
- hashnum的方式来讲数组中的方式来拆分成多个表?没太明白
- 分片键设计要求高吗?
- 大表分片后,写表还是会跨机房吗?
- MongoDB适合做商城app数据库吗?一般在哪些场景使用呢?
- 容量预警怎么做呢?
- 数据一致性在迁移过程中同步你们是怎么保证的呢?
- 我们数据体量不太大,主要是杂,这种环境想做好数据治理,建议把重点放在哪些方面?然后有没有一些比较常见的坑?
- 删除数据空间不释放怎么办?
- 现在有多大数据量?
- 你们这个大数据平台有多少开发人员?
问题一、性能优化有推荐的分析和监控工具么?
MongoDB常用性能分析主要如下:
1.1 MongoDB自带性能分析工具
【MongoDB官方对外工具mongostat】
命令行使用方法(ip:port为代理ip和端口):
mongostat -h ip:port -u用户名 -p密码 –authenticationDatabase=admin –discover
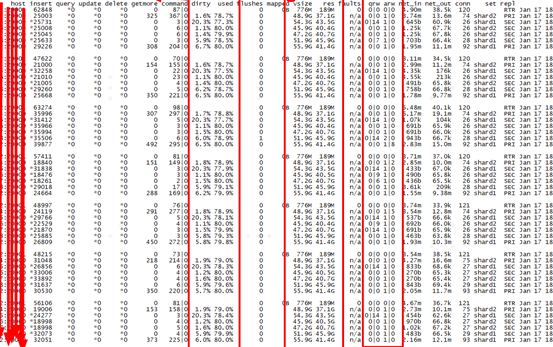
mongostat工具带上–discover,可以把所有分片节点信息一起打印出来,直观查看整个集群所有节点实例级监控信息。mongostat统计信息中最核心的几个影响性能的统计项:
- dirty:存储引擎脏数据比例,默认该值为5%的时候,wiredtiger存储引擎自带的evict现成开始选择脏数据page淘汰到磁盘;如果该值达到20%,客户端请求对应mongodb处理现成将会选择脏数据page淘汰到磁盘,等page淘汰腾出内存空间后,才会处理客户端请求的DB访问,所以如果阀值达到20%客户端访问将会变慢。
- used:存储引擎cacheSize配置占用百分比,如果配置cacheSize=10G,存储引擎实际使用了7G,则used赞比为70%。当该统计值达到80%,evict线程将会触发选择涨数据淘汰,如果这个占比提高到95%,用户请求线程将会触发淘汰,客户端请求将会变慢。
- qrw arw:等待队列数,如果该值越大,说明会引起客户端请求排队处理。一般该值会再dirty占比超过20%,used占比过高超过95%,或者磁盘IO慢会出现。
- vsize res:虚拟内存和物理内存真实占用,如果vsize过高,远远超过res,或者res过高,远远超过cachesize配置,则说明内存碎片,pageheap等问题,这时候可以通过加速tcmalloc内存释放速率来解决问题。
【慢日志分析】
通过以下命令分析日志文件
- 找出文件末尾1000000行中存在扫表的操作,不包含oplog,getMore
tail mongod.log -n 1000000 | grep ms |grep COLLSCAN |grep -v “getMore” | grep -v “oplog.rs”
- 找出文件末尾1000000行中所有的慢日志,不包含oplog,getMore
tail mongodb.log -n 1000000 |grep ms | grep op_msg | grep find | grep -v “oplog.rs” |grep -v “getMore”
- 找出文件末尾1000000行中执行时间1-10s的请求,不包含oplog,getMore
tail mongodb.log -n 1000000 |grep ms | grep op_msg | grep find | grep -v “oplog.rs” |grep -v “getMore” | egrep 1-90-9ms
- currentOp正在执行的慢操作分析
慢日志只有当请求执行完毕才会,如果一个表很大,一个查询扫表,则整个执行过程可能需要数小时,可能还没记录慢日志,则可以通过如下命令获取当前执行时间超过5s的所有请求,查询请求,command请求:
db.currentOp({“secs_running”:{“$gt”:5}})
db.currentOp({“secs_running”:{“$gt”:1}, “op”:”query”})
db.currentOp({“secs_running”:{“$gt”:5}, “op”:”command”})
kill查询时间超过5s的所有请求:
db.currentOp().inprog.forEach(function(item){if(item.secs_running > 5 )db.killOp(item.opid)})
【节点存储引擎监控信息】
db.serverStatus().wiredTiger可以获取mongod节点对应存储引擎的各自详细统计信息,里面可以完整获取时延消耗在存储引擎哪一个环节。
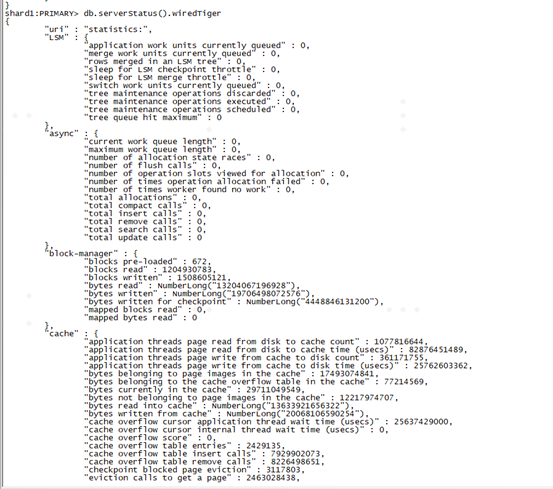

下面是空余时间分析的wiredtiger源码,分析不是很完整,后续等mongodb server层单机、复制集、分片等完整模块化分析后,会回头继续分析。
1.2 操作系统性能瓶颈分析
系统层面性能分析工具主要有:top、iostat、pstak、ptress、perf、iotop、isof等,具体请参考对应工具说明。
1.3 开源MongoDB详细监控套记
开源方案可以参考以下组件:
Grafana+Prometheus+node_exporter+mongodb_exporter
【服务端组件:】 Prometheus #服务端 Grafana #前端展示
【客户端组件:】 node_exporter mongodb_exporter
问题二、 会话加标签是怎么指定服务器?
举一个例子形象说明:我们把用户分为三组,20 岁以下(junior),20 到 40 岁(middle)和 40 岁以上(senior),按照下面的几条命令执行以后,我们的数据会按照用户年龄段拆分成若干个 chunk,并分发到不同的 shard cluster 中。
如果对下面的命令不熟悉,可以查看 MongoDB 官方文档关于 Shard Zone/Chunk 的解释。
sh.addShardTag(‘shard01’, ‘junior’)
sh.addShardTag(‘shard02’, ‘middle’)
sh.addShardTag(‘shard03’, ‘senior’)
sh.addTagRange(‘test.users’, {‘user.age’: MinKey}, {‘user.age’:20}, ‘junior’)
sh.addTagRange(‘test.users’, {‘user.age’: 21}, {‘user.age’:40}, ‘middle’)
sh.addTagRange(‘test.users’, {‘user.age’: 41}, {‘user.age’: MaxKey}, ‘senior’)
通过上面的6个命令给’test库的user表加标签,20以下对应标签为’junior’,21-40对应标签为’middle’,41以上对应标签为’senior’。同时把’junior’标签分配给’shard01’,也就是0-20岁的user会全部写到’shard01’,21-40岁的user会全部写到’shard01’,41岁以上的user会全部写到’shard01’。
这样就可以解决跨机房写的问题,只要对应分片主节点在对应机房即可。
问题三、脏数据比例多少算高?
默认20%算高,如果脏数据比例持续性超过20%,可以试着提高wiredtiger存储引擎后台淘汰线程数:
db.adminCommand( { setParameter : 1, “wiredTigerEngineRuntimeConfig” : “cache_size=35GB, eviction=(threads_min=4, threads_max=12)”})
问题四、写分开会有时延吗,是不是有一致性问题?
一致性默认完全由mongodb复制集自带的主从同步机制来保证最终一致性,不存在双向同步两集群的一致性问题。
如果要实现复制集中主从节点的强一致性,可以通过客户端配置writeconcern策略来解决。
问题五、如何定位详细的慢查询呢?
和问题1雷同,可以通过分析currentop、日志文件或者system.profile慢日志表来获取详细的慢日志信息。
建议平台化收集慢日志,这样界面展示分析更加直观。
问题六、如何快速定位MongoDB的问题发生在集群中的哪些节点?在启用读写分离的情况下?
主要通过如下几个步骤来分析:
- db.serverStatus().opLatencies监控mongod实例时延
- 如果由运维研发能力,可以自己收集时延展示,如果没有。则可以借助开源工具系统实现,参考《1.3 开源mongodb详细监控套记》
- 充分利用mongostat监控集群所有节点实时脏数据、队列、内存信息
参考《1.1 mongodb自带性能分析工具》
- 慢日志分析
参考《比如想定位详细的慢查询呢?》
问题七、杨老师,就您经验来讲,您觉得如何保证MongoDB 的安全性呢?
安全性方面主要由以下几方面保证:
- 账号鉴权认证,一个库一个账号
- readWrite权限去除删库、删表等危险操作权限
- 不同业务不混用同一个集群
- 启用黑白名单功能
- 我司mongodb内核增加审计、流量控制、危险操作控制等功能。(注:部分功能是mongodb企业级功能,需要付费,也可以使用percona mongodb版本)
- 数据定期备份,我司mongodb内核增加有热备功能。
注意:如果数据量很大,建议不要使用mongodump备份,mongodump备份会很慢,同时通过mongorestore恢复也是一条数据一条数据恢复,同样很慢。如果有内核研发能力,可以增加热备功能。如果没有内核研发能力,可以通过如下步骤备份:1. 隐藏节点;2. 锁库;3. 拷贝数据文件。或者采用percona mongodb版本来备份。
问题八、mysql和mongodb双写的话怎么保证事务呢?
mysql我不是很了解,mongodb不推荐搭两集群双向同步来备份,直接利用mongodb原生的复制集功能来完成多活容灾,成本、性能、一致性都可以得到保证。即使是4.2分布式事务功能也可以直接利用mongodb自身的机制来保证,具体方案参考我在Qcon全球软件开发大会的分享:
问题九、hashnum的方式来讲数组中的方式来拆分成多个表?没太明白
分享的案例2:万亿级数据量mongodb集群性能数倍提升优化实践,不是拆分数据到多个表,而是把一条数据(该数据保护一个数组,数组中包含数百万个子文档)通过hash的方式散列为多条数据。也就是之前数百万个子文档归属于一条数据,现在把他拆分为归属到多条数据。
通过这样合理的数据合并和拆分,最终平衡磁盘IO,实现读和写达到一种平衡态,既能满足业务读需求,同时也能满足业务写需求。
问题十、分片键设计要求高吗?
分片集群片建选择非常重要,对分片模式集群性能起着核心至关重要的作用,分片集群片建选择遵循以下几个原则:
- 首先需要考虑集群部署是否需要分片?
只有以下情况才需要分片功能:1. 数据量太大,一个分片撑不住;2. 写流量太大,写只能走主节点,一个主节点撑不住,需要扩分片分担写流量。
- 片建选择原则?
片建选择原则如下: 1. 保证数据尽量离散;2. 尽量保证更新和查询到同一个分片(如果同一次更新或者查询到多个分片,只要任何一个分片慢,该操作都会慢;同时部分查询会进一步加剧代理聚合负担)。
此外,如果查询注意是范围查询,建议选择范围分片,这样有利于范围数据集中到同一个分片。
问题十一、大表分片后,写表还是会跨机房吗?
机房多活打标签方式解决跨机房写问题,同样可以对对应tag表启用分片功能,保证数据到指定的多个分片,每个分片主节点在指定机房,可以解决跨机房问题。详情参考:《会话加标签是怎么指定服务器?》
问题十二、老师您好,想请问下:MongoDB适合做商城app数据库吗?一般在哪些场景使用呢?谢谢!
个人觉得完全可以满足要求,同时还有利于业务的快速迭代开发。mongodb天然的模式自由(加字段方便)、高可用、分布式扩缩容、机房多活容灾机制,可以快速推进业务迭代开发。以我的经验,至少90%以上使用mysql的场景,mongodb同样可以满足要求。mongodb唯一缺点可能是生态没mysql健全,研究mongodb的人比较少。
问题十三、老师能讲讲你们容量预警是怎么做的吗?
容量水位我们分为以下几种:
- 磁盘容量限制
当一个分片中磁盘使用率超过80%,我们开始扩容增加分片。
- 流量超过阀值
读写流量阀值水位如下:1. 如果是分片的写流量持续性超过3.5W/s(ssd服务器)则扩容分片;2. 如果是读流量单节点持续性超过4W/s(ssd服务器,所有读走磁盘IO),则扩容从节点来解决读流量瓶颈,注意需要配置读写分离。
- CPU阀值
我们所有实例容器部署,实例如果CPU使用率持续性超过80%,考虑增加容器CPU。
问题十四、数据一致性在迁移过程中同步你们是怎么保证的呢?
如果通过mongoshake等工具迁移集群,需要提前关闭blance功能,否则无法解决一致性问题。
我们线上集群只有把数据从集群迁移到另一个集群的时候才会使用mongoshake,我们机房多活不是多个集群双写方式,而是同一个集群,通过夫直接的主从同步拉取oplog机制实现一致性,所以不存在一致性问题。可以参考 万亿级数据库MongoDB集群性能优化及机房多活容灾实践。
问题十五、我们数据体量不太大,主要是杂,这种环境想做好数据治理,老师你建议把重点放在哪些方面?然后有没有一些比较常见的坑?
数据量不大,比较杂的场景,一般集群搞一个复制集即可满足要求,无需分片模式部署。
我猜测你们的比较杂可能是利用mongodb的模式自由,造成每条数据的字段各不相同,数据长度大小各不一致。建议在使用模式自由这一功能的时候,一定不要”滥用”、”乱用”,在使用时代码逻辑需要简单控制。我重节线上遇到的对模式自由的”滥用”、”乱用”引起的集群问题:
- 同一个表的数据的字段控制在50个KV以内,这样对应更新、查询等性能分析有利,减少磁盘IO消耗。
- 如果数据字段过多,查询的时候不要返回所有字段,只获取对本次查询有用的字段,减少网络IO开销。
- 数组别乱用,数组中的文档保持格式统一。
- 数组中的子文档如果需要查询指定字段,一定记得对数组中嵌套的字段添加子索引。
- 数组字段中的文档一定要控制在一定范围,避免该数组过大,数组过大有遍历、磁盘IO过高等问题。
- 嵌套子文档层数不宜过多。
- ……
问题十六、删除数据空间不释放怎么办?
mongodb内核默认删除数据不会释放磁盘空间,这部分空间可以被新的写入重复利用,这样可以提升性能。此外,mongodb提供了compact命令来进行空间释放,但是实际环境中有时候该命令执行后效果不理想,这时候可以通过清除从节点数据进行全量同步来释放空间。注意:全量同步如果数据量很大,可能oplog空间不够用,造成同步失败,这时候需要合理跳大主节点oplog size大小,确保全量同步期间产生的增量数据oplog可以全部容纳。
问题十七、现在有多大数据量?
超过万亿级。
问题十八、你们这个大数据平台有多少开发人员?
我们研发+运维人员很少,我和另外一个小伙伴,总共2人。mongodb拥有天然的高可用、分布式扩缩容、机房多活容灾、高压缩比、客户端均衡策略、分片策略等功能,保证了可以用很少的人力来满足公司快速增长的业务需求。
最后
国内真正拥有企业级分布式数据库自研能力的公司主要集中在阿里、腾讯头部几家,即使二三线互联网公司也无法做到真正意义上的企业级分布式数据库研发能力,拥抱开源是一个明智的选择。
mongodb拥有天然的高可用、分布式扩缩容、机房多活容灾、完善的负载均衡、高压缩比及一致性策略等功能,可以做到最少人力成本满足业务快速增长的需求,个人认为mongodb绝对是头部公司以外企业会分布式数据库需求的一个值得信赖的选择。
正如在Qcon专题:现代数据架构、dbaplus、mongodb中文社区所分享,当前mongodb国内影响力待提升最大的问题在于国内真正研究mongodb内核实现细节的人太少,造成很多复杂问题无法解决,最终这些”人”的问题演变为“mongodb问题”。
在此,后续持续性分享业务接入过程中的典型踩坑,同时持续性模块化分析mongodb内核设计原理,为mongodb国内影响力提升做点实事,具体计划如下(详见:盘点 2020 | 我要为分布式数据库 mongodb 在国内影响力提升及推广做点事)。
此外,任何主流数据库都有其存在的理由,业务场景很重要,脱离业务场景评判数据库优劣是不客观的行为。可以说某数据库在某种场景下不适合,千万不能否定整个数据库。
更多文章:
OPPO百万级高并发MongoDB集群性能数十倍提升优化实践
盘点 2020 | 我要为分布式数据库 MongoDB 在国内影响力提升及推广做点事
前滴滴出行技术专家,现任OPPO文档数据库MongoDB负责人,负责oppo千万级峰值TPS/十万亿级数据量文档数据库MongoDB内核研发及运维工作,一直专注于分布式缓存、高性能服务端、数据库、中间件等相关研发。Github账号地址:https://github.com/y123456yz
更多问题可以添加社区助理小芒果微信(mongoingcom)咨询,进入社区微信交流群请备注“mongo”。



评论前必须登录!
注册