 MongoDB中文社区
MongoDB中文社区
通过上一篇内容,我们学习了如何用内嵌来表示各种关系,包括 1-1,1-N,以及 N-N。在基础建模法宝“内嵌数组”的加持下,MongoDB 模型设计好似非常简单,但寄希望于内嵌“一招打遍天下”显然也不可能。接下来我们还需要通过技术场景的细化,来进行模型修饰,特别是使用引用的方式。本篇内容就来到了文档模型设计的下一步——工况细化。

在文档模型设计的第二步中,我们要根据具体的技术需求对模式进行调整,这是一个技术导向的过程。首先,需要通过和业务方的详细沟通,了解如下信息:
-
数据的使用方式,最频繁的数据查询模式 - 最常用的查询参数
- 最频繁的数据写入模式
- 读写操作的比例
-
数据量的大小
例如:在联系人应用中,我们需要先知道数据的使用方式是个人使用还是用于报表;对新闻网站而言,最主要的查询模式是否是按最新时间查询;如果银行希望做一个新场景,已知读写操作比例是 99:1,可以由此判断模型设计如何优化……这些都是在这一步工作中非常重要的输入参数。
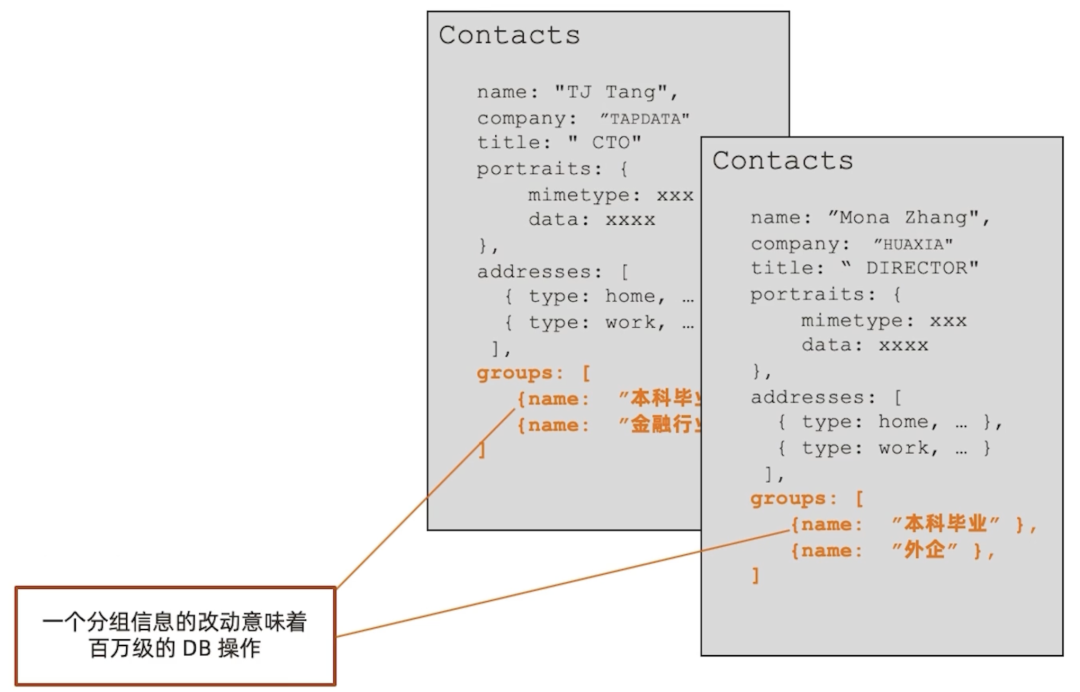
假设应用使用方为企业,现有千万级联系人,其中包含大量客户,现有明确的用于客户营销的场景需求,即跟随营销活动,对联系人进行标签分组,进行针对性操作,并查看活动进展,因此需要频繁变动分组(group)信息,如增加分组,修改名称、描述以及营销状态等。而前文提到的基础模型却只是简单地把所有相关信息全部放到一个 JSON 文档里中,在没有明确需求的情况下还不会暴露问题。但如果放到单个分组的联系人可达百万级的前提下,group 信息被冗余到每一个联系人里,无论是修改 group 名字、状态还是 id 属性,任何一个分组信息的改动都可能意味着百万级 DB 的操作——很显然,这样的基础模型不再是一个能够满足需求的好的设计。
针对这一问题,又该如何改善?
解决方案:Group 使用单独的集合
这里我们提出的解决方案类似于关系型设计。MongoDB 里也可以分表,我们可以把 group 信息放入另外一个表,之后仍然可以用 group_id 进行关联,当然也可以用其他的 id 字段或唯一键关联。

至于如何表示 1-N 或 N-N 的关系,还是用数组,只不过这里的 group_id 变成了一个 id 的数组,而不是完整的 group 的所有内容,像是名字等信息都不包含在内。我们在联系人表中只存了一个 group_id 的数组,通过这个方式来表示联系人属于哪几个group。具体的 group 的信息在我们的联系人中是没有的。如果有需要,可以做类似关联。
事实上,MongoDB 从 3. 2 版本开始就支持一个名为 $lookup 的操作,可以用来提供一次查询多表的能力,类似于关系型数据库里面的 JOIN 关联。虽然也存在一些限制,但原则上可完成类似操作。下面一起来看一下通过这种方式可以达到什么样的效果。
引用模式下的关联查询
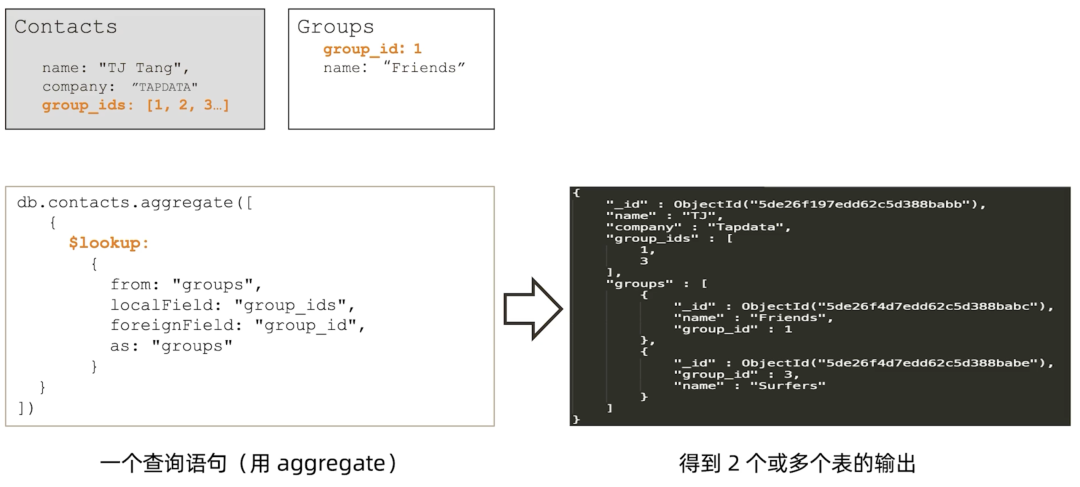
首先我们有两张表,分别为 Contacts 和 Groups。而最终呈现到移动或网页端的时候,我们希望看到的是完整的联系人的信息,包含分组的名字,这就需要我们来做关联,可以用 aggregate $lookup 来实现。
这里的 db.contacts.aggregate 是一个聚合运算。这个聚合框架属于 MongoDB 的特性之一,是一个非常强大的功能,很多通过查询 find 或是其他方式无法完成的操作,以及很多复杂的数据的处理,包括我们现在要做的关联,都可以在 aggregate 里完成。我们要用到的 $lookup 就是 aggregate 框架里面的一个操作符。
$lookup 如何操作?
首先有几个最基本的要求,关于属性字段,需要提供如下几个值:
- from:去哪里抓取信息,该例中,基础表是 Contacts,执行 $lookup 就是向另外一个表查询数据,表的名字在from 字段中指明;
-
localField 和 foreignField:本地表字段和目标表字段,该例中,指的是在当前的 Contacts 联系人表中,用 group_ids 字段和目标表 Groups 中的 group_id 字段进行一一对应; -
as: “groups” :将取回的数据放到什么字段名中。
如此,完成这一语句操作后,我们就实现了两表关联的等同效果。如上图所示,左侧用一个查询语句查询两张表,右侧得到两个表的联合输出,从中可见基础信息包括:联系人(name)、公司(company)、group_id 1和3。这里的 groups 字段,就是此前 $lookup 聚合语句生成的新的字段,这是动态生成的,原型里并没有。通过两表聚合,把 groups 表中的信息 $lookup 过来,放到一个目标最终结果的 JSON 数组里。

我们再来看另外一个例子——联系人的头像。最初,我们习惯地将联系人头像作为一个子属性,放置于主表,也就是联系人之下。但经过对业务方的业务和技术需求的仔细研究,我们发现,头像的使用高保真,大小在 5MB-10MB 不等,甚至更大,远超预估,同时存在一个月不可更换的上传限制条件,这就需要我们来重新考虑这一层的设计问题了。
一方面,是图像文件较大,更换频率较低;另一方面,如前文所述,我们需要理解头像数据将会怎样被调用,被谁调用,从数据访问的角度来看,不难发现,在进入明细数据之外,一般不需要调用头像数据,联系人大部分情况下都不太关注头像数据,只会做不含头像的基础信息查询,像是地址、公司、部门等信息。非头像信息查询和头像查询比例大致为 9:1。
什么时候该使用引用方式?
- 内嵌文档太大,数 MB 或者超过 16MB。例如前文提到的头像文档,大小可能是几兆到十几兆,且不常同主数据一起使用,此时就可以考虑用引用方式。
- 内嵌文档或数组元素会频繁修改。例如第一个例子中的分组信息,如果直接内嵌到联系人中,分组信息的频繁修改就容易导致 DB 的频繁更新操作,会很占资源。这就合适用引用的方式把这部分数据拿出来。相反,如果是像是联系人地址这种极少修改的数据,就不存在这种放到外表的需要。
- 内嵌数组元素会持续增长且没有封顶。如果数组的大小无法确定。例如日志表、交易表等,一般信息条数上限无法保证,极有可能16M限制,或导致文档太大。同样需要考虑把这部分数据数据放到另外一张表来管理。
MongoDB 引用设计的限制
当然,引用设计同时也存在一些限制,并不是“万金油”式的存在。如果过度引用就会变成关系模型设计,这也是走入了另外一个误区。因此,对于引用设计,我们使用起来要格外小心,做到必要时在使用。此外,在技术层面,MongoDB 的一些限制我们也需要了解:
- MongoDB 对使用引用的集合之间并无主外键检查。MongoDB 不似关系型数据库那样有主外键的检查,虽然在实际使用过程中,即使在关系型设计里我们也不一定会使用主外键。但如果真的有需要,在 MongoDB 中,主外键之间的关系则完全靠我们自己来维护,因此就有可能出现一个联系人和一个头像完全分隔,头像找不到其主体联系人的状况,MongoDB 是无法支持这种完整性检查的。
- MongoDB 使用聚合框架的 $lookup 来模仿关联查询。我们所说的引用,只是通过 $lookup 来模仿的关联,只是帮助我们把一些信息合并进来,太复杂的关联还无法实现。换言之,$lookup 虽然是可以做关联,但只支持 left outer join,其他像是 inner join(内关联)、non-equality join(非等同关联)等关联方式,MongoDB 目前还无法支持。
- $lookup 的关联目标(from 字段)不能是分片表。已知 MongoDB 可以支持分片分布式的架构,当数据量达到比如数十乃至数百亿量级时,一个数据库无法承载,则需要分多个实例来实现。这里的实例在 MongoDB 中就属于一种分布式的分片概念。但如果我们关联涉及到的两个表都是分片表,目前 MongoDB 是无法支持的。也就是说,当我们需要用 $lookup 去关联另外一张表时, 只有当前的主表可以是分片的,关联的目标表不行。
以上,是本篇的全部内容,我们具体讲解了 MongoDB 文档模型设计方法论的第二步“工况的细化”,下一步我们将共同学习三步曲中的最后一步“套用模式”。
【关联阅读】
-
干货教程 | MongoDB 熟练到精通(一):模型设计基础知识详解 - 干货教程 | MongoDB 熟练到精通(二):JSON 文档模型设计的常见误区及其与关系模型的区别
-
干货教程 | MongoDB 熟练到精通(三): 文档模型设计三步曲之基础建模篇

MongoDB全周期数据库服务



评论前必须登录!
注册