 MongoDB中文社区
MongoDB中文社区
导语:本文为《MongoDB 熟练到精通》系列文章第五篇。该系列内容主要面向开发者,介绍在系统上线之前需要关注的事项,包括如何进行最关键的文档模型设计、读写事务操作,介绍数据安全和事务性等诸多高级参数和特性的含义及使用方式,以及开发者最佳实践。在最基本的数据库增删改查之余,我们更希望通过这部分的学习,让大家有足够的底气把简历上的“熟练使用 MongoDB 进行开发”,改为“精通使用 MongoDB 开发”。下面就让我们一起开启今日份的学习吧。
通过前两章内容,我们学习了文档模型设计三步曲中的基础建模,以及如何根据技术工况来进行模型细化,本篇将重点讲解模式套用的相关内容。
一、三步曲终章:套用模式设计

Java 程序员面试中有这样一个关于设计模式的经典问题,“你都了解什么样的设计模式,熟悉掌握哪些,在什么场景下使用”,因为一个好的模式往往可以达到事半功倍的效果,这就是套用模式的力量。
对应到 MongoDB,以 IoT 场景为例,如果能利用好分桶设计模式,可以在存储空间降低 10 倍的同时,实现查询效率的数十倍提升,效益非常显著。之所以能够做到这一点,是因为文档模型本身并没有一个固定的范式,无固定的思维定式,允许我们充分发挥想象力,在模型上做很多有创意的尝试。而所谓的设计模式,就是在这些过程中,基于前人的应用开发留存下来的,经过实战屡试不爽的设计技巧。接下来我们就把这些总结下来的技巧分享出来,帮助大家快速掌握在什么样的场景下可以快速应用这些优秀的设计模式,从而将模型优化到最佳状态。
二、举例详解
问题:物联网场景下的海量数据处理-飞机监控数据
继续看前文提到的 IoT 场景,假设现有监控飞机状态的需求,对包括飞行位置、发动机运行状态等在内的各项指标进行记录,字段包括 ID、航班号、时间戳等等,数据实时性保障在分钟级以上。这是一个非常简单的时序数据模型。

但当我们将其放置到实际场景下来思考,就不难发现,这个问题所面临的最大挑战在于数据量——假设全世界有 10 万架飞机,现要存 1 年的数据,按照每分钟采集 1 条来计算,总计约为 526 亿条数据,这还仅仅是条数。放到数据库中来看,我们还需要创建很多索引,才能实现快速搜索到某一架飞机在某一个时间点的轨迹或性能参数。因此我们在条数基础上,还需要将索引大小也考虑在内(130 字节),总结索引需要的存储空间约为 6TB。

再到数据量,虽然单条数据本身可能并不大,约为 92 字节,但同样的,放到实际应用环境中,代入各项条件数据来计算,整体数据大小约为 4.5TB 左右,加上索引的 6TB,对于数据库而言,无疑可以算作一个比较大型的应用场景了,尤其是数据条数,已达数百亿,这往往就需要用到类似于 64核、512G 内存这样的大型机或是架设更多服务器通过分布式存储来管理这些海量数据,才能满足较为高效的存取需求。
MongoDB 的解决方案:分桶设计
但在 MongoDB 中,有一个专门应对这种时序数据的非常经典的模式设计,也就是前文提及的“分桶”。所谓分桶,就是通过对业务的分析,将这些数据“分桶组合”存储到一个组中,每个文档会保存特定时间范围内的数据,这比在每个时间点/数据点创建一个文档更高效。对应到我们的例子中,就是与其 1 分钟一条数据,不如考虑每 1 个小时存一条,每分钟的数据仍然存在,只不过换用了数组的方式。

简言之,我们可以把这一个小时间的 60 条事件视作一个包含 60 个元素的事件数组放在文档中,从而让原本的 1 分钟一条成功变为 1 小时一条。如此一来,假设一架飞机本次航班飞行两个小时,仅需两条数据就可以完成所有相关事件的记录。下面让我们通过直接的数据对比,来更直观地理解如此设计的意义与价值:
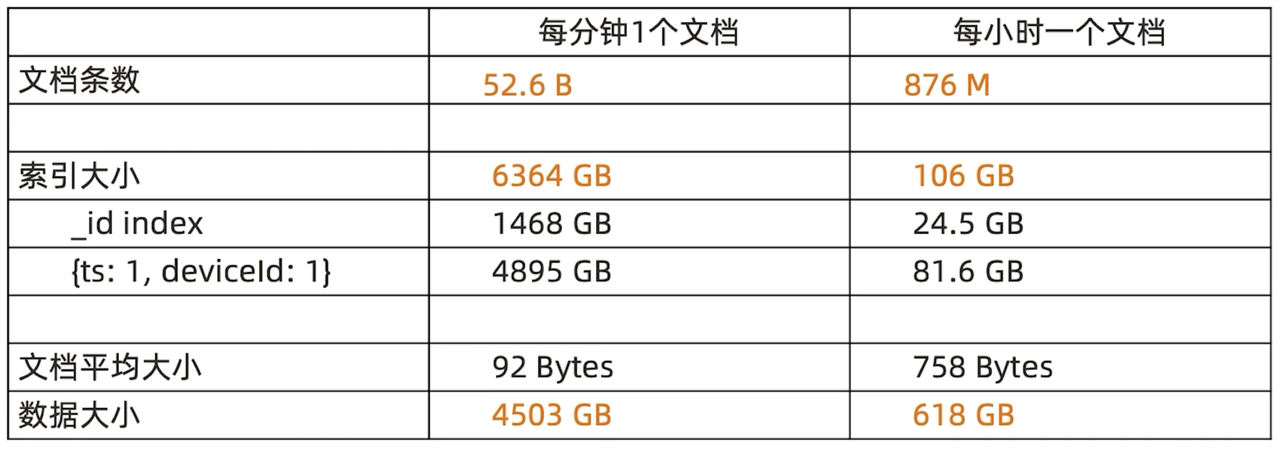
如上表所示,每小时 1 个文档的新模式下,文档条数从每分钟1个文档的 526 亿,骤缩至 8.76 亿,相差数十倍;索引基于数据条数产生,每条数据都至少有一个索引向,因此随着条数的骤缩,索引项也相应地急剧减少,索引大小从 6T 变为 100G。但数据大小的变化程度就小了很多,从原本的 4.5T 减少至大约 600G。这是因为我们的变化并没有丢失数据,仍然是分钟级的监控,并没有变为低保真,仅仅是将每一条数据汇总到1个小时中,这就导致单条数据变大了,文档平均大小由原本的 92 字节,变为 758 字节,但仍控制在 1KB 之内。整体大小的差异则来自于公用字段的节省。总结下来,存储减少了 10 倍左右,索引和条数都是 60 倍缩小。
面对如此显著的优化,就不得不考虑到另一个问题——这些改变是否需要以降低读取效率,影响正常使用为代价。
而这个问题又显然不能脱离实际使用场景来判断。就像本例中的飞机监控,很多时候并不需要进行每分钟的读取,通常只需要一次性获取整个航班某一时段内的全部数据,比如去年整年或是最近两天,用于在程序或 dashboard 等做一些展现。比如可视化地表现 24 小时的飞行数据,通过传统方式需要 1000 多次读,但新的方式仅需24 次,因为每小时一个文档。因此,新模式不仅没有降低效率,反而在读取表现上也更加出色。这也是我们在很多时序数据处理的相关场景中,推荐采用分桶模式的原因。
模式小结:时序数据场景与分桶的适配度
类似的时序数据场景还有很多,以物联网相关为最,例如智能手表、智能家居、智慧城市、智慧交通等,凡是涉及到需要定时定刻不间断采集数据,在后台做分析并展现的,都非常适合使用这种分桶模式。分桶的范围包含分钟、小时、天等等,着主要取决于我们的业务需求,但核心痛点是相同的,即数据点采集频繁,数据量、存储量太大,都可以通过这种分桶嵌套的模式来大量减少文档数量及索引所占用的空间。这已经是一个在很多实际案例中被证实非常有效的解决方案。
三、小结
综上所述,一个好的设计模式可以在显著提升数据读写效率的同时,大大降低对资源的需求。
除了分桶,MongoDB 中类似的模式还有很多:

例如和分桶同属于组织结构分类的预聚合,以及列转行、文档版本的管理、近似处理、子集等等。本篇通过分桶设计模式为大家演示了套用一个设计模式可以对我们的数据模型带来多大的改观,之后的系列文章中,将为大家分享更多设计模式。
【关联阅读】
-
干货教程 | MongoDB 熟练到精通(一):模型设计基础知识详解 - 干货教程 | MongoDB 熟练到精通(二):JSON 文档模型设计的常见误区及其与关系模型的区别
-
干货教程 | MongoDB 熟练到精通(三): 文档模型设计三步曲之基础建模篇 - 干货教程 | MongoDB 熟练到精通(四): 文档模型设计三步曲之工况细化篇

MongoDB全周期数据库服务



评论前必须登录!
注册