 MongoDB中文社区
MongoDB中文社区
导语:本文为《MongoDB 熟练到精通》系列文章第一弹。该系列内容主要面向开发者,介绍在系统上线之前需要关注的事项,包括如何进行最关键的文档模型设计、读写事务操作,介绍数据安全和事务性等诸多高级参数和特性的含义及使用方式,以及开发者最佳实践。在最基本的数据库增删改查之余,我们更希望通过这部分的学习,让大家有足够的底气把简历上的“熟练使用 MongoDB 进行开发”,改为“精通使用 MongoDB 开发”。下面就让我们一起开启今日份的学习吧。
一、什么是数据模型?
按照《数据建模经典教程》作者 Steve Hoberman 的定义,数据模型“是一组由符号、文本组成的集合,用以准确表达信息,达到有效交流、沟通的目的”。
我们可以举一个生活中的例子。假设你是一个保险公司的经理人,当你在讨论一个客户的时候,更多考量的是客户的年收入、婚姻状态、家庭成员等信息。但如果背景换成理发店,考虑的内容就会变成:每个月会来几次理发店、偏好什么样的发型等等。二者所关注的客户属性是完全不同的。换言之,同样的概念可以以极为不同的表现形式来呈现。而数据模型就是希望通过一个逻辑化、物理化的模型来满足大家可以在同一个层面交流的目的——这是数据模型的基础。
二、数据设计模型包含哪些元素?
数据模型一般包含实体实体(Entity)、属性(Attribute),以及关系(Relationship)这三个关键元素。套入一个管理联系人的应用来看这三者的含义与联系,如下图所示:
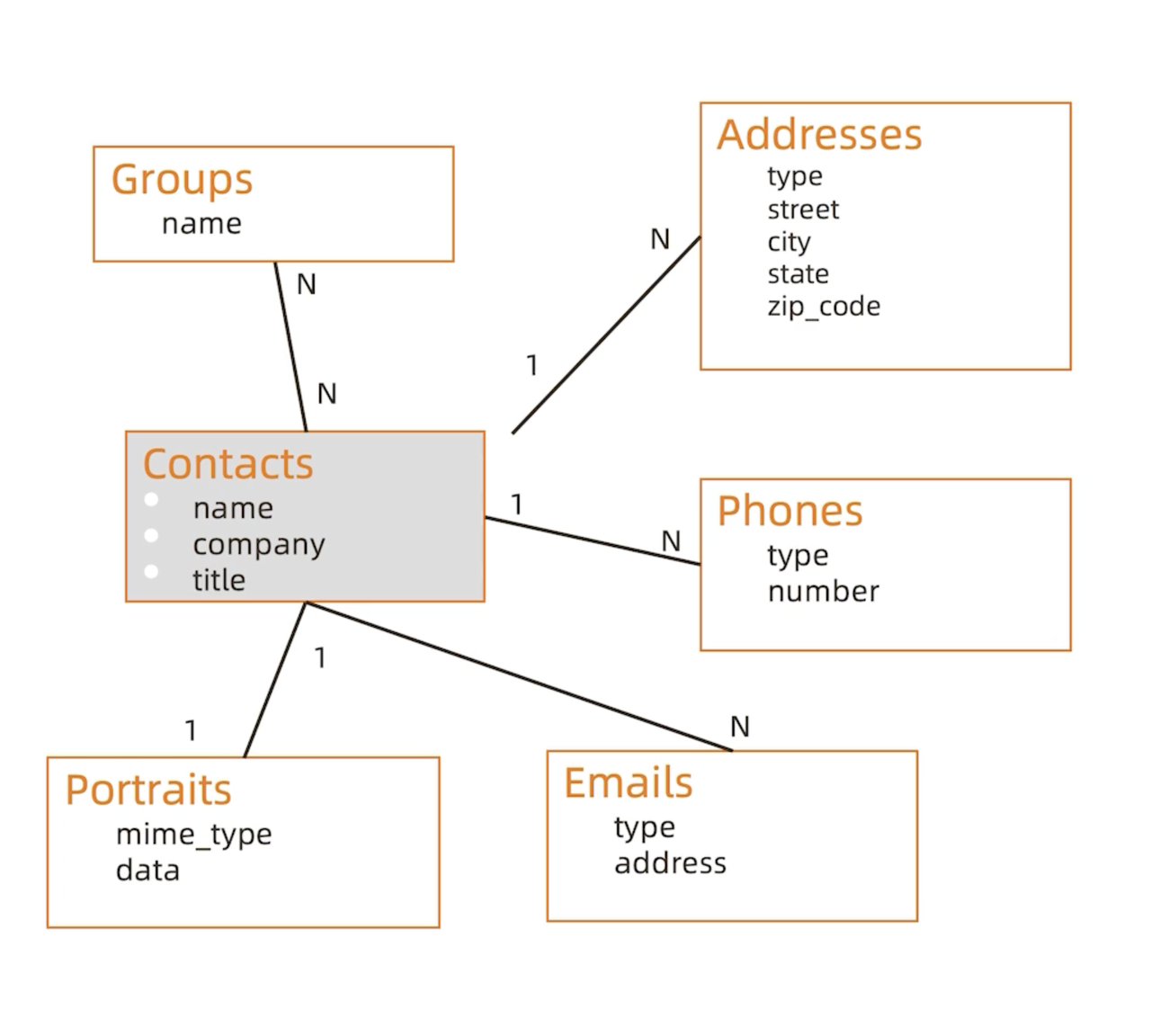
① 实体(Entity):描述业务的主要数据集合
如图中高亮部分,包括联系人(Contacts)、联系人分组(Groups)、联系人地址(Addresses)、电话号码(Phones)、邮箱(Emails),以及头像(Portraits),都可以理解为实体。这里的实体指的就是我们主要用以描述业务的数据集合,笼统概括,像是表达谁、什么、何时、何地、为何、如何等等。
② 属性(Attribute):描述实体中的单个信息
属性则是用来进一步描述实体的。实体是比较概念性的东西,一个实体中还包含诸多具体属性。参考图例,联系人一般还会包含姓名、公司、职务等信息;地址可以细分到所属省、市、区、街道,以及邮政编码等;电话号码同样如此,不同的类型或具体的号码串等也都属于“属性”。
③ 关系(Relationship):描述实体与实体之间的数据规则
关系描述的是属性与属性之间存在的关联。在上述例子中,一个联系人可能有多个地址录入,比如家庭制地址、工作地址等。电话号码、邮箱等亦然——同一个联系人有多个电话,多个邮箱——这些都属于一对多的关系。与此同时,还存在一对一的关系,像是头像,因为每个联系人都只有一个头。
此外,多对多的关系也是存在的,例如分组。我们可以为联系人建立朋友、同事、旅伴等多个不同的分组标签加以区分,同一个人可能兼具多个标签属性,也即属于多个分组。换个角度来看,一个分组中自然也可以包含多个联系人。因此,联系人和分组之间就属于多对多的关系。我们将这些不同的结构规则,用我们用 1-N / N-1 / N-N 来表示。同时在关系中也会涉及到一些引用规则,例如电话号码不能单独存在,如果没有联系人的话,单独存在的电话号码也就毫无意义,这里包含了一层从属关系。
到这里,我们对传统模型的几大要素已经有了一定的理解,而模型设计就是需要我们能够把这些要素列出来。
三、如何进行模型设计?
传统模型设计,一般会从采用“从概念到逻辑到物理”的三层流程来实现,分别对应概念模型(Conceptual Data Modeling)阶段、逻辑模型(Logical Data Modeling)阶段以及物理模型(Physical Data Modeling)阶段,是一个逐层细化的过程。
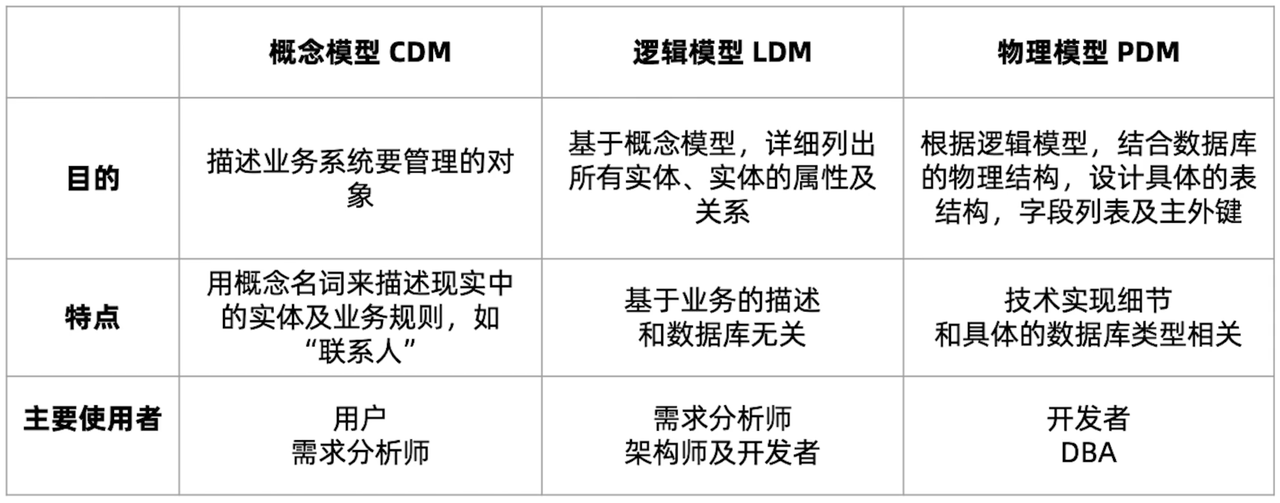
其中,概念模型相对比较抽象,往往由我们的用户和需求分析师用来描述“想要构建一个什么样的应用”,比如客户管理、地址管理、业务流程管理等。这一阶段大多不涉及详细的技术概念,只是对需求的初步说明。因此还需要分析师或架构师根据业务需求进行细化,画出逻辑模型。
逻辑模型阶段需要我们基于对业务的理解,列出业务中需要用到的全部实体,例如想要做一个 CRM,用来管理客户信息、交互渠道、联系方式等,就要先把这些实体以及每个实体的属性都列出来,同时还要通过与需求方的沟通,把其间的关系也明确地描述出来。在这一层,我们其实仍然没有真正进入到非常具体的技术实现,模型的主要使用者是架构师、开发者或需求分析师。
逻辑模型之上再进一步细化,就来到了第三层——物理模型。物理模型阶段是一个非常具体的过程,需要先结合实际的数据库特性和结构,再考虑如何把逻辑模型表示到物理层中来。此时最常见的使用对象,一般是 DBA 或建模分析师,他们会把逻辑模型转化成真正的物理模型。
-
开发者视角的概念模型
仍然以联系人管理应用场景为例:起初,业务需求方给到了管理联系人,方便快速分类检索的需求。这里包含两个关键词,一是联系人,一是分组,停留在概念模型,还比较粗粒度。

-
开发者视角的逻辑模型
下一步到逻辑模型,需要列出这些实体里具体有哪些的属性,像是联系人姓名、电话号码等;有哪些关系,同一个联系人有几个联系电话,涉及几个分组,有几处地址,以及关系结构等。
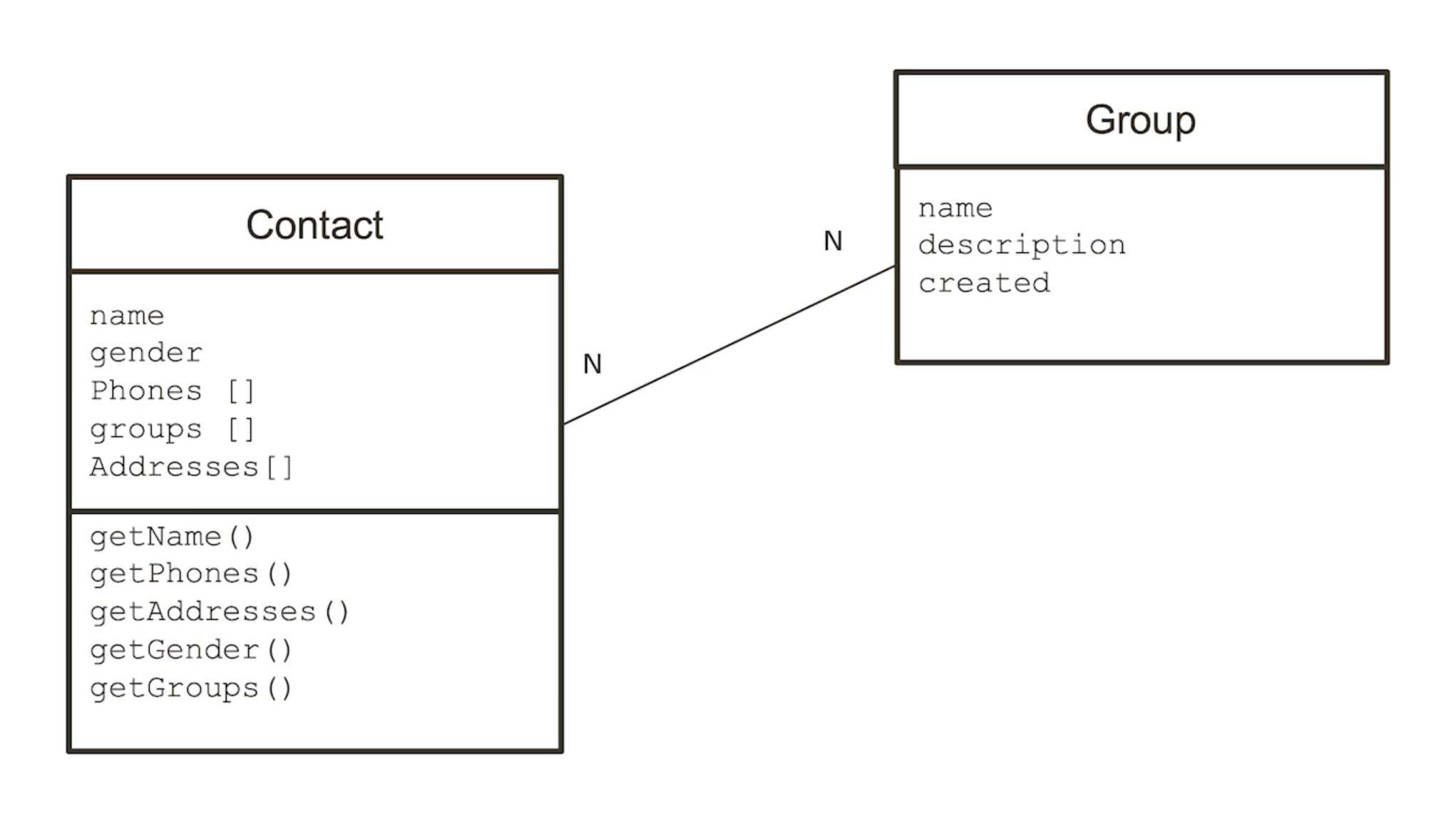
开发者视角的逻辑模型
-
开发者视角的物理模型
已知这是一个简单的联系人管理应用,已完成两大实体和主要属性的定义,下一步就应当由 DBA 或开发者着手,真正落定到物理模型的设计。常见的主流物理模型是关系式模型,而关系模型的一大特点就是第三范式——数据在库里尽量不可能存在冗余,也就是当设计完成后,所涉元素在数据库里面,每一个实体和数值都应当只存在一次,通过关联的方式可以把各种信息组合到一起。
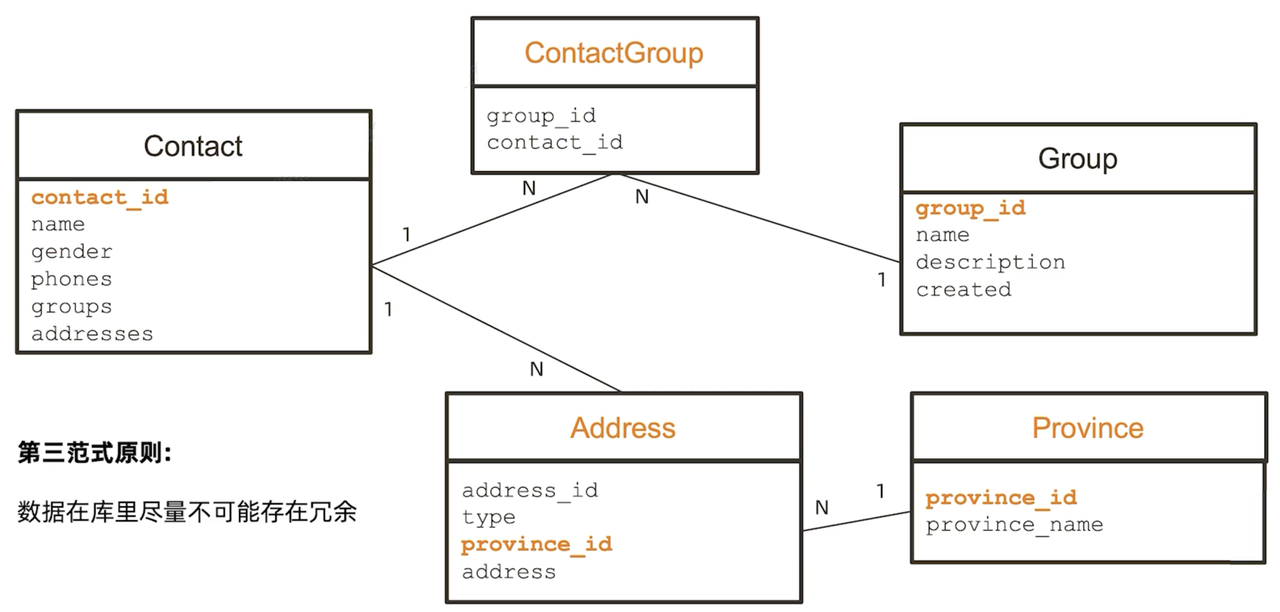
开发者视角的物理模型
根据这一原则,先在关系模型设计里面做一个 N-N 的关系设计。由于第三范式的限制,只能通过一个 Mapping Table,也就是中间表 ContactGroup——把 Contact 和 Group 这两个表组合在一起,用来表示某个联系人属于哪个分组,以及某个分组里有多少位联系人。
再来看地址实体,因为存在多个地址,按照第三范式也必须分表,分到一个单独的地址表可能还不够,因为一个地址往往包含多个字段,例如省份、城市等等,这些字段在不同的地址里也会重复多次。在第三范式的要求下,这种重复也是不被允许的,因此还需要进一步范式化,把这些可能重复的数值再单独列出一张表,例如 Province 省份表,每一行代表一个省份。通过这种方式,我们极大限度地满足了第三范式的要求。优势就是,数据完全没有重复。
至此,我们就完成了一个经典的传统关系模型的建模,从概念到逻辑到物理。
本篇主要主要介绍了数据模型设计的基础概念和传统流程:模型的三要素是实体、属性、关系;数据模型的构建就是从概念到逻辑到物理逐层细化的过程,最后达成完整的物理模型。在此基础上,下一篇我们将具体讲述 MongoDB 如何进行模型设计,敬请期待。
⭐️ 碰上 MongoDB 使用问题?想要寻求更多咨询及运维帮助?这里有↓↓




评论前必须登录!
注册