 MongoDB中文社区
MongoDB中文社区
上一篇中,我们已经初步掌握了模型设计的基础以及关系模型的建模过程,本篇重点为:JSON 文档模型的设计。
-
MongoDB 是 Schemaless,不需要模型设计(❌) - MongoDB 设计模式非常简单,就是用一个超级大文档来组织所有数据,一张表即可搞定(❌)
-
MongoDB 是 NoSQL 不支持关联或者事务,因此只能用在较为边缘化的小场景上(❌)
以上是三个关于 MongoDB 文档模型设计的常见误区,那么正确的 MongoDB 模型设计应该是怎么样的,这种误解又是如何产生的?
① 关于 MongoDB 是否需要建模
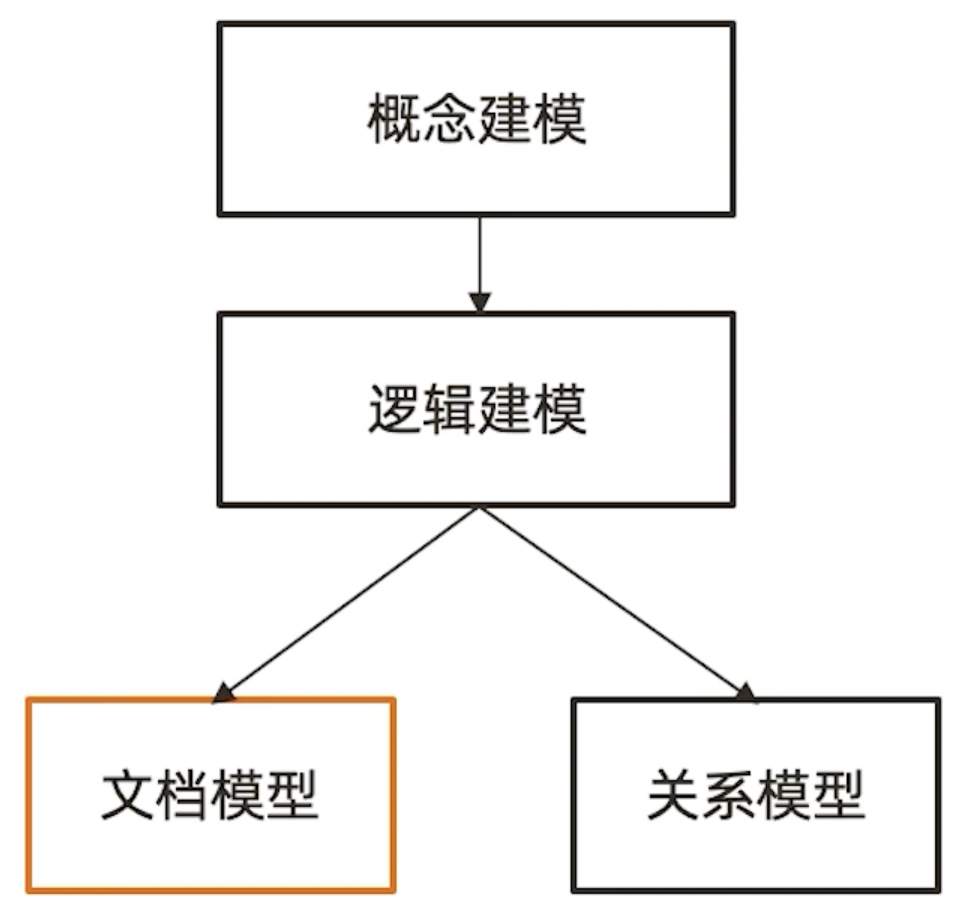
上一篇有提到,传统建模过程通畅包括三个步骤,从概念建模到逻辑建模到物理建模。在关系模型设计中,真正的关系模型设计就处于第三层物理建模。同样的,在 JSON 文档模型设计中,文档模型设计也属于第三层。虽然前两步也都是必要的,但在实际工作中,其实很少会真正依循这个步骤来执行,往往都是直接跳到第三步物理建模。但非常不同的是,关系模型在物理建模时需要明确画出 ERD 图,把表和主外键定义出来,然而文档模型只需要定义出 JSON 文档,不遵从第三范式,允许冗余,不需要用主外键关联,而是通过内嵌数组或引用字段来表示关系。
② 为什么都说 MongoDB 是无模式?

对于文档模型而言,由于其自身的 JSON 特色,建模时的物理模型和逻辑模型中的对象模型其实非常接近。简言之,JSON 文档模型设计的物理层架构可以和逻辑模层类似。因此从某种程度来看,我们可以跳过物理模型建模,仅用逻辑模型就可以完成类似的文档模型建模过程。那么假如我们最初就没有从概念模型开始,物理建模的具体过程又可以省略,就显得 MongoDB 好像完全是无模式的,这便是 Schemaless 误区的由来。但事实上,严格来说, MongoDB 和关系型数据库一样,同样需要概念建模和逻辑建模这两个必不可少的步骤。模型设计对于 MongoDB 而言,同样非常重要。
附逻辑模型与 JSON 模型的举例对比:
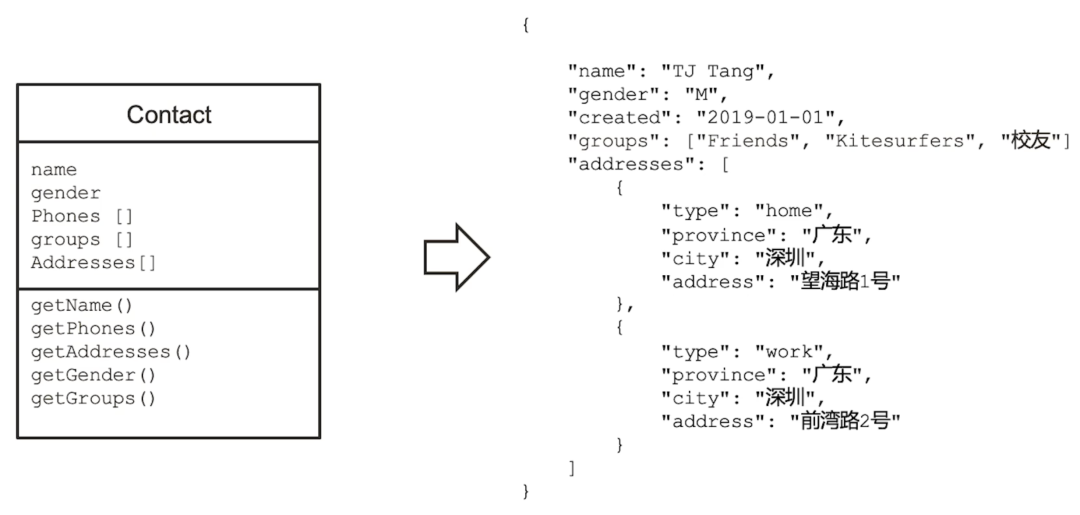
然而对于文档模型设计而言,不受第三范式原则约束,既有好处,也存在弊端,那就是会导致我们很难明确按照什么样的法则来建模,以及如何判断模型的好坏。
谈及文档模型的设计原则,主要有以下两个关键点:
-
性能(Performance):能否支撑得非常高并发、低延迟的读写。 -
开发易用(Ease of Development):设计出的模型在程序中开发时是否容易使用
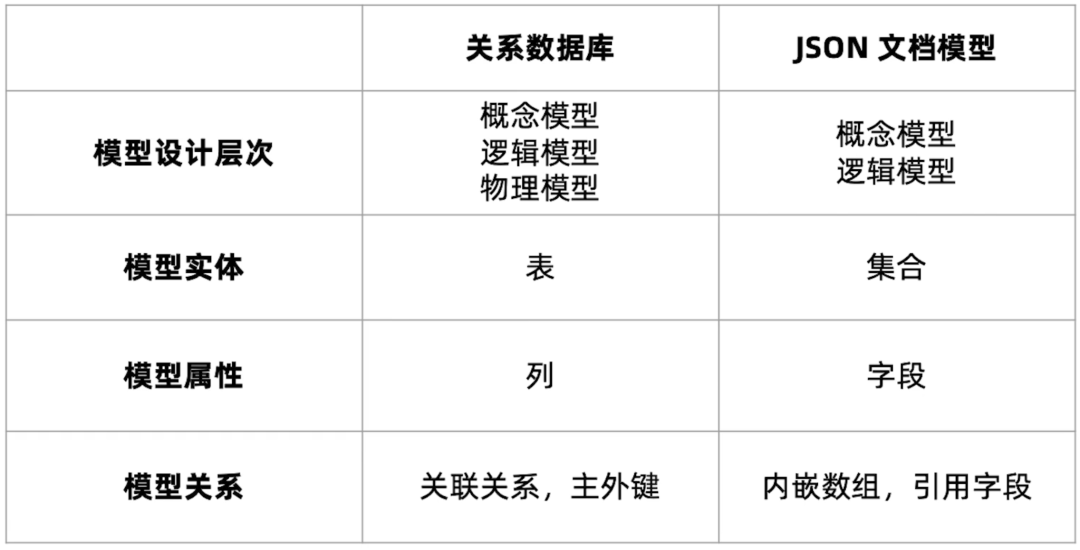
首先从模型设计的层次来看,严格意义上,关系数据库的建模包含从概念到逻辑到物理三层;JSON 文档模型下,物理模型则变为可选项,如果和逻辑模型一致,则可跳过。
从模型实体来看,关系数据库用表来表示模型实体,而 MongoDB 则用集合表示。
从模型属性来看,关系模型中相对简单,是列来实现, 而 JSON 文档通常有用字段方式。
最后也是最大的不同点在模型关系方面,关系数据库建模通常通过主外键、关联关系来表示;而 JSON 文档模型大多使用内嵌数组的方式来表示,偶尔也会用到引用字段。
本篇主要主要介绍了 JSON 文档模型的设计的原则及其和关系模型设计的一些区别点。在此基础上,下一篇开始,我们会给大家介绍有关文档模型构建的具体方法论。




评论前必须登录!
注册