 MongoDB中文社区
MongoDB中文社区
MongoDB 4.0增加了一个能力,在副本处理写操作的同时可以由从节点(secondary)读取数据。为了理解这个的重要性,让我们看看4.0版本之前从节点是如何处理的。
背景
从一开始,MongoDB就是这样设计的:当主节点上有一系列的写入操作时,每个从节点必须以相同的顺序体现出这些操作。如果你在一个文档中更改了字段“A”,然后更改了字段“B”,则不可能看到此文档字段“B”被更改而字段“A”未被更改的状态。你可能会在最终一致性系统内看到这种现象,但在MongoDB中不会。
在从节点上,我们会分批应用写操作,因为按顺序应用这些写操作可能会导致从节点落后于主节点。当批量应用写操作时,我们必须阻塞读操作,使应用程序不会看到以“错误”顺序应用的数据。这就是为什么由从节点读取数据时,必须定期等待副本批量数据的应用。写负载越重,从节点越可能在读取时遇到这种“暂停”现象,从而增加系统延迟。考虑到应用程序经常使用从节点读取来降低查询的延迟(比如当它们使用“nearest”的readPreference时),而这种对应用副本批量数据的等待会阻碍你的这一目的。
除了读操作必须等待副本批量数据写入完成外,写操作也需要一个锁,获取该锁要求所有读操作必须全部完成。这意味着,在存在大量读操作的情况下,副本数据的写入可能会出现滞后——当链式复制(chain replication)被启用时,这个问题会相当复杂。
MongoDB 4.0的目标是什么?
我们的目标是允许在oplog被应用期间进行数据的读取,以减少读取延迟及从节点滞后,同时增加复制集的最大吞吐量。对于具有高写入负载的复制集,不必在应用批量的oplog之间等待数据读取,可以降低延迟并更快地对大多数写入(majority writes)进行确认,从而减少主服务器上的缓存压力,提高总体性能。
我们是如何实现的?
从MongoDB 4.0开始,我们利用了这样一个事实:我们在存储引擎中实现了对时间戳的支持,这允许事务在特定的“集群时间(cluster time)”获得一致的数据视图。有关详细信息,请参阅视频:WiredTiger时间戳。

对从节点的读取操作现在同样可以利用快照,方法是从在应用当前的批量副本数据之前的最新的一致性快照中读取数据。从该快照读取可以确保数据的一致性视图,而且由于应用当前的批量副本数据不会更改这些早期记录,因此我们现在可以不再使用锁,而允许在写入发生的同时进行所有这些对从节点的读取。
区别有多大?
区别非常大!吞吐量的性能改进范围可以从无(如果你没有受到复制锁的影响,说明写负载相对较低)到两倍。
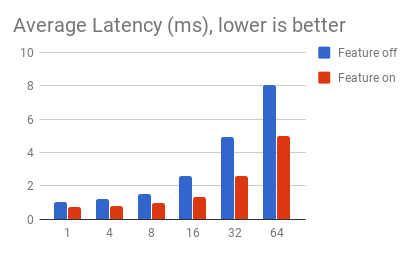
最重要的是,这改善了从节点读取的延迟——对于那些使用readPreference为“nearest”的人来说,因为他们希望减少从应用程序到数据库的延迟——这一特性意味着他们在数据库中的延迟也将显著降低。在测试中我们发现95和99百分位的延迟有显著改善。
| 线程数 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|
| 特性关闭 | 1 | 2 | 3 | 5 |
| 特性开启 | 0 | 1 | 1 | 0 |
95百分位读取延迟 (ms)
你知道这个新特性最好的地方在哪吗?你不需要做任何事情来激活或选择它。4.0版本中的所有对从节点的读取都将来自快照,无需等待副本数据写入完成。
这只是MongoDB 4.0的许多新功能之一。请关注我们博客中关于4.0RC版本的内容以了解更多信息。最后别忘了,你仍然来得及注册MongoDB World大会(译者注:现在是来不及了,这是18年的链接,等19年的吧),在那里你可以与正在构建这些优秀新特性的工程师会面。
本文译自:Scaling Your Replica Set: Non-Blocking Secondary Reads in MongoDB 4.0



评论前必须登录!
注册