 MongoDB中文社区
MongoDB中文社区
多行事务
Mongodb4.0引入了多文档事务的特性,我们来看,4.0中是如何进行一个多文档事务的(js的mongoshell代码)。
mongo进行一个多文档事务,必须和一个session对象绑定。通过 startTransaction/ CRUD / commitTransaction 三段式来进行。
function updateEmployeeInfo(session) {
employeesCollection = session.getDatabase("hr").employees;
eventsCollection = session.getDatabase("reporting").events;
session.startTransaction( { readConcern: { level: "snapshot" }, writeConcern: { w: "majority" } } );
try{
employeesCollection.updateOne( { employee: 3 }, { $set: { status: "Inactive" } } );
eventsCollection.insertOne( { employee: 3, status: { new: "Inactive", old: "Active" } } );
} catch (error) {
print("Caught exception during transaction, aborting.");
session.abortTransaction();
throw error;
}
commitWithRetry(session);
}
可以看到,startTransaction方法并没有返回值,事实上,它只是设置了writeConern/readConcern等参数, 而mongo提供的和session相关的commands列表中,也只有session.CommitTransaction 没有session.StartTransaction。这意味着什么呢?这意味着一个session对象不能并发的进行多个事务,其实一个session对象本身就是一个事务,准确而言,session对象的生命周期等价于mongo底层的writeUnit的生命周期。我在之前一篇文章 【Mongodb事务模型分析】中介绍过,wt本身一直都有多行事务的能力。mongo3.x系列的单行事务,是把索引,数据,oplog的更新放在了一个wt事务里,每一次写/更新操作都是一个事务,而万变不离其宗,4.0中的多行事务,设计了一个session对象给用户,session对象维护了wt层的事务对象。一次session.CommitTransaction 相比于3.x系列,本质差别仅仅在于向wt层提交的数据变多了。
961 void Session::_commitTransaction(stdx::unique_lock lk, OperationContext* opCtx) {
1002 opCtx.getWriteUnitOfWork().commit();
1003 opCtx.setWriteUnitOfWork(nullptr);
1004 committed = true;
}
WT-3181
applyOplog的全局锁(PBWM)
说到这,似乎都说完了,其实不然,mongo4.0发布,wt层也配合做了改造【WT-3181】。我们知道,mongodb 的从节点拉取主节点的oplog进行并发回放,这里会带来一些问题【SERVER-20328】:
oplog的顺序(oplog的ts字段的大小)和oplog的回放顺序(在wt层的提交顺序)是不一致的。这个不一致造成了从节点在回放oplog时必须加全局读锁。防止客户端看到并发写时不一致的数据状态。解决这个问题不一定需要WT-3181,比如我之前【SERVER-20328】提出过,在applyOplog之间对wt生成一个snapshot,将所有从上面的读引流到这个snapshot上,也可以解决这个问题,细节暂且不提,我们看看mongo4.0 是如何借助WT-3181消除从库回放oplog的全局锁的。
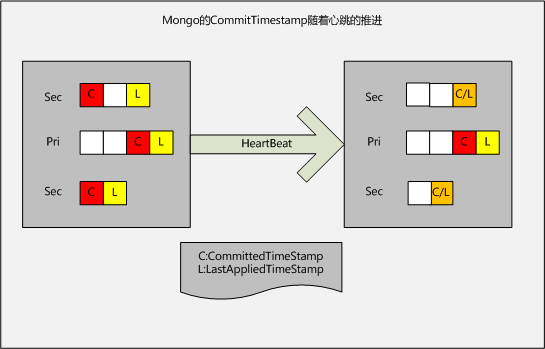
mongo在每应用完一批oplogs之后,会调用setMyLastAppliedOpTimeForward 方法设置local_timestamp为这一批oplog中最后一条的ts。
151 class ApplyBatchFinalizer {
162 void _recordApplied(const OpTime& newOpTime,
163 ReplicationCoordinator::DataConsistency consistency) {
166 _replCoord.setMyLastAppliedOpTimeForward(newOpTime, consistency);
167 }
178 };
而这一条oplog的ts通过WiredTigerSnapshotManager::setLocalSnapshot,利用WT-3181提供的set_timestamp特性与一个wt层的snapshot一一对应,这个snapshot在mongo层叫做localsnapshot。两个localsnapshot之间,是oplog的并行复制过程,如果过早对外可见,用户就有可能读到一个空洞。
而db_raii::AutoGetCollectionForRead方法里,判断allowSecondaryReadsDuringBatchApplication这个服务端参数,如果该参数打开,就会忽略PBWM全局锁,并通过设置kLastApplied将LocalSnapshot最为读的源snapshot。
86 AutoGetCollectionForRead::AutoGetCollectionForRead(OperationContext* opCtx,
87 const NamespaceStringOrUUID& nsOrUUID,
88 AutoGetCollection::ViewMode viewMode,
89 Date_t deadline) {
90 // Don't take the ParallelBatchWriterMode lock when the server parameter is set and our
91 // storage engine supports snapshot reads.
92 if (allowSecondaryReadsDuringBatchApplication.load() &&
93 opCtx.getServiceContext().getStorageEngine().supportsReadConcernSnapshot()) {
94 _shouldNotConflictWithSecondaryBatchApplicationBlock.emplace(opCtx.lockState());
95 }
109 while (auto coll = _autoColl.getCollection()) {
110
111 // During batch application on secondaries, there is a potential to read inconsistent states
112 // that would normally be protected by the PBWM lock. In order to serve secondary reads
113 // during this period, we default to not acquiring the lock (by setting
114 // _shouldNotConflictWithSecondaryBatchApplicationBlock). On primaries, we always read at a
115 // consistent time, so not taking the PBWM lock is not a problem. On secondaries, we have to
116 // guarantee we read at a consistent state, so we must read at the last applied timestamp,
117 // which is set after each complete batch.
118 //
119 // If an attempt to read at the last applied timestamp is unsuccessful because there are
120 // pending catalog changes that occur after the last applied timestamp, we release our locks
121 // and try again with the PBWM lock (by unsetting
122 // _shouldNotConflictWithSecondaryBatchApplicationBlock).
123
124 const NamespaceString& nss = coll.ns();
125
126 bool readAtLastAppliedTimestamp =
127 _shouldReadAtLastAppliedTimestamp(opCtx, nss, readConcernLevel);
128
129 if (readAtLastAppliedTimestamp) {
130 opCtx.recoveryUnit().setTimestampReadSource(RecoveryUnit::ReadSource::kLastApplied);
131 }
结合上面两段代码,我们可以知道,mongodb4.0中,从节点的读是不会和并行回放oplog相互阻塞的,也不用担心会读到不一致的状态。抛开复杂琐碎的实现细节,其原理也很简单,即读最近的一致的snapshot。
stable_checkpoint与rollback
经过上面的一顿分析,感觉不管是从库读snapshot还是多文档事务,WT-3181都不是必要的。我们再来看看这个新特新:mongo基于WT的rollback_to_stable API,实现了更加优雅的rollback功能。在说rollback之前,不得不先说说raft。
我们知道,mongodb自从3.x系列,主从复制就使用raft协议了。
raft的核心概念有两个:状态机与日志应用。所谓的状态机,对应到mongodb的概念里,就是wiredtiger的kvstore。所谓的日志应用,在mongo里就是主从oplog复制。mongo的oplog复制也是使用raft协议。raft里有一个commit-timestamp的概念,不严格来讲,指的是被大多数节点应用到的日志的timestamp。raft算法可以保证commit-timestamp 一定不会被回滚。
mongo里也保证,以 writeConcern:majority的方式写入的数据,一定不会丢失,否则,主从切换后,与新主不一致的oplog,必须要被rollback掉。
这里可以有一个反思:
Q:既然raft可以保证 “commit-timestamp” 一定不会回滚,那么mongodb为何不仅仅应用commit-timestamp之前的oplog到状态机(wiredtiger-kvstore)中呢? 这样可以把”回滚”的动作严格隔离在日志复制层面?
A:commit-timestamp的推进需要通过节点之间的网络心跳来完成,延迟不一定可接受。mongo提供了更灵活的writeConcern,可以让用户读到未被(raft)commit的写。
说完raft,我们再说说3.x系列的rollback是怎么做的。
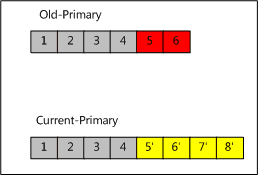
从复制源不断同步新oplog的过程。该过程一般会出现这两种问题:
- 复制源写入过快(或者相对的,本地写入速度过慢),复制源的oplog覆盖了 本地用于同步源oplog而维持在源的游标。
- 本节点在宕机之前是Primary,在重启后本地oplog有和当前Primary不一致的Oplog。
这两种情况分别如下图所示:

3.x 系列处理rollback的方法,以3.2.10为例,如下:
这两种情况在bgsync.cpp:_produce函数中,虽然这两种情况很不一样,但是最终都会进入 bgsync.cpp:_rollback函数处理,
对于第二种情况,处理过程在rs_rollback.cpp中,具体步骤为:
1. 维持本地与远程的两个反向游标,以线性的时间复杂度找到LCA(最近公共祖先,上图中为Record4)
该过程与经典的两个有序链表找公共节点的过程类似,具体实现在roll_back_local_operations.cpp:syncRollBackLocalOperations中,读者可以自行思考这一过程如何以线性时间复杂度实现。
2. 针对本地每个冲突的oplog,枚举该oplog的类型,推断出回滚该oplog需要的逆操作并记录,如下:
2.1: create_table --- drop_table
2.2: drop_table --- 重新同步该表
2.3: drop_index --- 重新同步并构建索引
2.4: drop_db --- 放弃rollback,改由用户手工init_resync
2.5: apply_ops --- 针对apply_ops 中的每一条子oplog,递归执行 2)这一过程
2.6: create_index --- drop_index
2.7: 普通文档的CUD操作 --- 从Primary重新读取真实值并替换。相关函数为:rs_rollback.cpp:refetch
3. 针对2)中分析出的每条oplog的处理方式,执行处理,相关函数为 rs_rollback.cpp:syncFixUp,此处操作主要是对步骤2)的实践,实际处理过程相当繁琐。
4. truncate掉本地冲突的oplog。
最简单的普通文档的CUD操作的rollback,都需要从其他节点同步最新数据进行覆盖。
rollback_to_stable
随着复制的推进,每个节点虽有延时,但是(raft的)commit-timestamp时间点必然是单调的。由raft协议的保证,commit-timestamp之前的日志必然不会被回滚。因此mongo的每个节点(通过setMyLastAppliedOpTimeForward方法)确定一个oplog的ts成为commit-timestamp之后,会通过wt的api set_timestamp设置该ts为最新的stable-timestamp ,mongodb主从切换后,首先通过wt的api rollback_to_stable恢复到最近的被(raft)提交的snapshot,rollback的动作就完成了。毫无疑问,这样做更干净优雅。
oldest-timestamp
除了stable-timestamp之外,wt-3181 还提供了oldest-timestamp这一概念。oplog的ts和wt的snapshot一一对应,看上去非常美好,但是无数的前车之鉴的事实告诉我们,任何mvcc的实现中,维护的版本过多,都是有代价的。wt的官方文档中,建议用户通过设置oldest_timestamp对不需要的版本进行清理。小于oldest-timestamp的时间戳的数据会被wt清理。mongo4.0中,也有利用该机制进行版本清理。
commit as-of timestamp
最后,wt-3181提供了”commit as of some timestamp”的功能【Application-specified Transaction Timestamps
】,在mongo4.0中尚未看到有用,直觉上,这个功能会在mongo4.2的分布式事务中,协调分布式事务的时钟上派上用场。这个功能是干什么的呢?
举个例子:以同样支持snapshotIsolation的rocksdb为例,对db的并发写入,每一条记录,在数据库中会有一个唯一的seqid与该记录对应,作为此次写入的版本。这个seqid是数据库分配的(rocksdb最近推出的write_unprepared_transaction打破了这个规则,暂且不提),虽然实现上各有差别,但是一般都保证先提交的事务中包含的记录的seqid 比后提交的事务中包含的记录的seqid小。简而言之,seqid随着commit的wallclock 单调。而wt-3181的“commit as of some timestamp”则提供了另一种可能:用户虽然在wall-clock为18:00的时间提交了事务,但是可以强行设置事务的 commit_timestamp 属性为17:00,对于事务的snapshot-read而言,seqid 的递增是不会出现幻读的一个保证,而wt-3181打破了这一保证,实在值得更深入的研究与实验。



评论前必须登录!
注册