 MongoDB中文社区
MongoDB中文社区
MongoDB目前核心优势
『灵活模式』+ 『高可用性』 + 『可扩展性』
通过json文档来实现灵活模式
通过复制集来保证高可用
通过Sharded cluster来保证可扩展性
BSON
1.在JSON中,要跳过一个文档进行数据读取,需要对此文档进行扫描才行,需要进行麻烦的数据结构匹配,遍历比较慢
BSON针对JSON的一大改进就是将JSON的每一个元素的长度存在元素的头部,这样你只需要读取到元素长度就能直接seek到指定的点上进行读取了。
2.MongoDB优化:
(1) 由于内存与数据文件的映射
(2) 在更新或者获取Document的某一个字段时,如果需要先读取其前面的所有字段,会导致物理内存由于读操作被加载到不必要的字段上,导致资源的不合理分配。
(3) 而采用BSON只需要读到相应的位置然后跨过无用内容读取需要内容即可。
3. MongoDB=JSON + Indexes
MongoDB支持json格式的文档进行bson优化
和关系型数据库对比

参数参考




架构
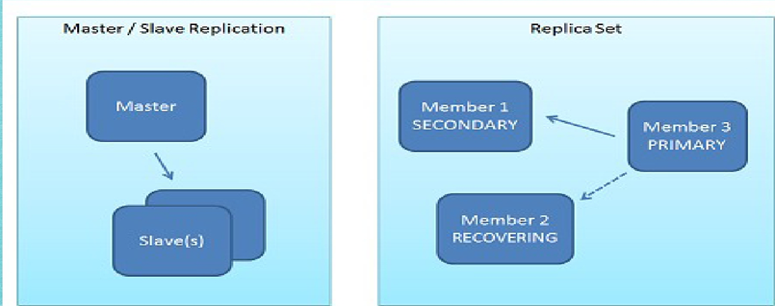
1.复制集和主从
强烈建议使用副本集模式(哪怕是单机副本集)
启用副本集在参数中添加:
sharding:
#configsvr or shardsvr
clusterRole: shardsvr
方便未来使之成为集群环境
2. 集群
(1) 分片适用场景
a. 服务器磁盘不够用
b.单个mongod不能满足日益频繁写请求
c.将大量数据存放于内存中提高性能
比如,如下集合
(2) 集群架构

Mongodb不适用场景
高度事务性系统,比如银行系统。传统的关系型数据库眼下还是更适用于大量原子性复杂事务的应用程序;
商业智能应用,针对特定问题BI,产生高度优化的查询方式,对于此类应用,数据仓库可能是更合适的选择;
复杂的跨表级联查询(多表join)。
MongoDB适用场景
非事务并且关联性集合不强的基本都可以使用
·MongoDB4.0+支持了事务
·MongoDB4.2版本支持集群事务
GridFS–文件存储:小文件和图片等
设计规范重点
I.复制集的读写设置
Read Preference
默认情况下,复制集的所有读请求都发到Primary,Driver可通过设置Read Preference来将读请求路由到其他的节点。
·primary: 默认规则,所有读请求发到Primary
· primaryPreferred: Primary优先,如果Primary不可达,请求Secondary
·secondary: 所有的读请求都发到secondary
·secondaryPreferred:Secondary优先,当所有Secondary不可达时,请求Primary
· nearest:读请求发送到最近的可达节点上(通过ping探测得出最近的节点)
II. 统计分组函数优化
- 线上正式环境
集合: props里有6000多万条数据
目表:统计查询
了解到他们的业务是昨天上线的,这个查询是处理一些错误的数据
统计语句是:db.props.aggregate([{$group:{_id:”$extra.uc_event.batchId”,count:{$sum:1}}},{$match:{count:{$gt:1}}}])
2.分析该语句可能出现的问题
做统计分析,查询超过了mongodb限制的16M大小;
mongo内存限制。 aggregate函数 使用$group时,数据大小必须小于16945KB
该查询是全表扫描,然后进行分组排序操作
执行如下查询:
shard1:SECONDARY> db.props.aggregate([{$group:{_id:"$extra.uc_event.batchId",count:{$sum:1}}},{$match:{count:{$gt:1}}}])
assert: command failed: {
"ok" : 0,
"errmsg" : "Exceeded memory limit for $group, but didn't allow external sort.
Pass allowDiskUse:true to opt in.",
"code" : 16945
} : aggregate failed
_getErrorWithCode@src/mongo/shell/utils.js:23:13
3.解决方法
添加设置:allowDiskUse:true
再次统计:
db.props.aggregate([{$group:{_id:"$extra.uc_event.batchId",count:{$sum:1}}},{$match:{count:{$gt:1}}}],{ allowDiskUse: true })
{ "_id" : null, "count" : 34655920 }
{ "_id" : "00028c13-1fce-487f-8c57-753a39dea94e", "count" : 2 }
{ "_id" : "000d4d9f-943b-47c1-9abd-0d17e9a66395", "count" : 2 }
{ "_id" : "000df209-8917-4949-948d-296bf0664b19", "count" : 2 }
{ "_id" : "000e1931-da1a-43e2-92f2-12e813c93058", "count" : 3 }
……
4.优化建议
统计batchId大于1的数据
数据集合有6300万,总大小6G
查询超过了mongodb限制的16M大小
执行3分钟左右
故可以限制扫描的行数,只扫描昨天到现在的数据即可(从业务上线到目前的错误数据),
(1)查询:添加时间限制
(2)查询使用allowDiskUse:true方法
(3)在secondary库执行统计分析
III. Mongodb的创建索引
需要和DBA沟通
在后台创建索引—不影响业务正常的DML操作
db.works.createIndex({plan:1,trgpoints:1,cOrder:1,sValue:1},{background:true})
IV. 删除字段、修改字段值等不清楚的和DBA沟通
V. 库名全部小写,禁止使用任何_以外的特殊字符,比如我们线上lp-pmm数据库
VI.集合名全部小写,禁止使用任何_以外的特殊字符
VII.如果评估单集合数据量较大,比如8亿以上的集合,可以将一个大集合拆分为多个小集合,即mongodb的分库分表-sharding;
VIII.MongoDB的集合拥有“自动清理过期数据”的功能
需在该集合中文档的时间字段增加一个TTL索引即可实现该功能
但需要注意的是该字段的类型则必须是mongoDate()
一定要结合实际业务设计是否需要
IX.文档设计
文档中的key禁止使用任何_以外的特殊字符
禁止使用_id,如:向_id中写入自定义内容
X. 查询中的某些 $ 操作符可能会导致性能低下
$exist:因为松散的文档结构导致查询必须遍历每一个文档
$ne:如果当取反的值为大多数,则会扫描整个索引
$not:可能会导致查询优化器不知道应当使用哪个索引,所以会经常退化为全表扫描
$nin:全表扫描
$or:有多少个条件就会查询多少次,最后合并结果集,所以尽可能的使用 $in
XI. 不要一次取出太多的数据进行排序
MongoDB 目前支持对32MB以内的结果集进行排序
如果需要排序,那么请尽量限制结果集中的数据量
特别注意



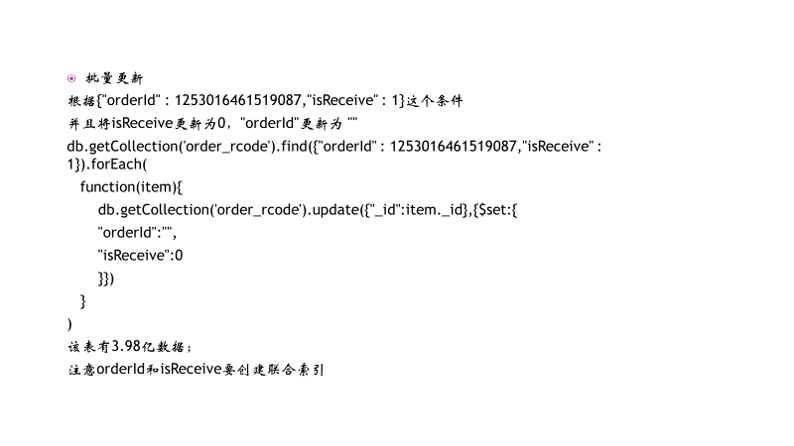

案例 mongodb-创建索引
引发的血泪案例
业务描述
需要在mongodb的集合timeline创建一个TTL索引[31.5天后过期]
ttl索引
shard1:PRIMARY> db.timeline.count()
482594935
业务定于的时间
(1)每天上午没有课,能进行创建和删除
(2)DBA建议在晚上12点后操作(业务没有采纳)
(3)最终定于2018/5/19上午10点开始创建TTL索引
10点开始创建索引正在主库执行
命令如下:db. timeline.createIndex({“created”: 1},{ name: “idx_infos_created”,expireAfterSeconds: 2721600},{background:true})
大约执行50%左右,业务要求停止创建索引,停止后,mongoDB索引会有重建功能,需要特殊处理
说明:即使使用这种方式创建索引成功,会没有”background” : true
创建后的索引查看db.infos.getIndexes()
停止创建索引操作
(1)在每个secondary节点操作(2个secondary节点操作)
mongod -f cumm.conf –shutdown停止
mongod -f cumm.conf –noIndexBuildRetry 不重建索引
时间大概30s左右完成
(2)在primary操作
kill创建索引线程
将primary shutdown
然后有一个secondary节点自动接管primary
大概两个操作能控制在1分钟内(即影响业务时间)
tips:
这样操作能有效避免发生重大业务问题
灾难再现
(1)上面几个步骤做完之后,业务会正常DML和查询等操作
(2)但是业务的程序有一个特点
a.java回放程序启动判断有没有索引,没有会自动重建
b.并且重建索引在是前台运行,阻塞所有查询和DML操作
建议
(1)严格按照DBA给予规定的时间执行DDL
(2)应用配置使用副本集模式
(3)程序去掉自动检测索引是否存在而后进行重建 DDL操作不能再程序有
(4)我们这边会针对性的进行培训,有效避免这样的事情
tips:
从这次故障中,梳理出了程序的配置弊端,有利于今后程序配置的良好性和正确性
· 正确的做法
db. timeline.createIndex({“created”: 1},{ name: “idx_infos_created”,expireAfterSeconds: 2721600,background:true}) #31.5天后过期
rsvk:PRIMARY> db.infos.count()
31028907—数据量少了1千多万
MongoDB创建索引,只有两个大括号{},否则就会有问题。
安全!安全!安全!
在参数文件中添加
security:
keyFile: /data/keyfile/key_file
并且key_file是600权限,否则启动失败
key_fike是一串字符
建议单库单用户
例如: 创建educat数据库,并且创建访问educat数据库的用户educa
use educat
db.createUser(
{
user:" educa",
pwd:“Hgq06#eR2wBg7e",
roles:[
{role:" readWrite",db:" educat"}
]
}
)
综述
综合上述案例和规范总结如下:
线上业务一般不使用MapReduce(我们会在隐藏的secondary节点进行操作),使用aggreage进行处理;
线上业务禁用不带条件的update、remove或者find语句
其中update语句一定使用$set
aggregate的第一层一定要使用$match,$group的成熟需不大于2层
db.book_rounds.aggregate([{$match: {‘createdTime’: {‘$gte’: new Date(‘2019-01-17’), ‘$lt’: new Date(‘2019-01-18’)}}},{$group:{_id:{userId:”$userId”},num_tutorial : {$sum : 1}}}],{ allowDiskUse: true })
之前该业务没有使用$match,数据量、并发小是可以的,后面直接导致业务接口超时;
查询只返回的字段
文档设计–内嵌文档最多内嵌一层
使用必要的用户验证登录



评论前必须登录!
注册