 MongoDB中文社区
MongoDB中文社区

前言
- MongoDB基于wiredTiger提供的泛化SI的功能,重构了readHistory(readMajority)的能力
- 基于wiredTiger提供的AllCommittedTimestamp API,重构了前缀一致的主从复制(Prefix-Consistent-Replication)
- 引入混合逻辑时钟(HLC),每个节点(Mongos/Mongod)的逻辑时钟维持在接近的值,基于此实现ChangeStream, 结合HLC与CLOCK-SI,实现分布式事务,HLC和泛化SI,CLOCK-SI两篇Paper可以作为理解MongoDB的设计的理论参考(这里并没有说MongoDB是Paper的实现)。
本文尝试对Mongo的复制和分布式事务的原理进行描述,在必要的地方,对实现的正确性进行论证,希望能为MongoDB内核爱好者提供一些参考。
MongoDB副本集事务介绍
- MongoDB 副本集的事务
SI的简介
- SI,即SnapshotIsolation,中文称为快照隔离,是一种mvcc的实现机制,它在1995年的A Critique of ANSI SQL Isolation Levels中被正式提出。因快照时间点的选取上的不同,又分为Conventional Si 和 Generalized SI。
|CSI(Convensional SI)
- CSI 选取当前最新的系统快照作为事务的读取快照
- 就是在事务开始的时候,获得当前db最新的snapshot,作为事务的读取的snapshot,
- snapshot(Ti) = start(Ti)
- 可以减少写事务冲突发生的概率,并且提供读事务读取最新数据的能力
- 一般我们说一个数据库支持SI隔离级别,其实默认是说支持CSI。比如RocksDB支持的SI就是CSI,WiredTiger在3.0版本之前支持的SI也是CSI。
|GSI(Generalized SI)
- GSI选择历史上的数据库快照作为事务的读取快照,因此CSI可以看作GSI的一个特例。
- 在复制集的情况下,考虑 CSI, 对于主节点上的事务,每次事务的开始时间选取的系统 最新的 快照, 但是对于其他从节点来说, 并没有 统一的 “最新的” 快照这个概念。泛化的快照实际上是基于快照观测得到的,对于当前事务来说,我们通过选取合适的 更早时间的快照,可以让 从节点上的事务正确且无延迟的执行。
- 举例如下:
- 例如当前数据库的状态是, S={T1, T2, T3}, 现在要开始执行T4,
- 如果我们知道T4要修改的值,在T3上没有被修改, 那么我们在执行T4的时候, 就可以按照 T2 commit后的snashot进行读取。
- 如何选择更早的时间点,需要满足下面的规则,

- 符号定义
-
Ti: 事务i -
Xi: 被事务i修改过的X变量 -
snapshot(Ti): 事务i的选取的快照时间 -
start(Ti): 事务i的开始时间 -
commit(Ti): 事务i的提交时间 -
abort(Ti): the time when Ti is aborted. -
end(Ti): the time when Ti is committed or aborted.
-
-
公式解释
读规则
- G1.1,如果变量X被本事务修改了值且读取到了新的值, 那么 读操作一定在写操作后面;
- G1.2, 如果事务i读取了事务j更新的变量的X, 那么一定不会有事务i更新X的操作,在事务i读取了事务j更新的变量的X这个操作前面;
- G1.3, 事务j的提交时间早于事务i的快照时间;
- G1.4, 对于任意一个会更新变量X的事务k, 那么这个事务k一定满足, 要么事务k的提交时间小于事务j, 要么这个事务k的提交时间大于事务i。
-
写规则
-
- G2, 对于任意已经在提交历史里的两个事务,Ci, Cj, 那么一定可以保证当 事务j的commit时间戳在 事务i的观测时间段内时(snapshot(Ti), commit(Ti)), 那么他们更新的变量交集一定为空。
|PCSI(PREFIX-CONSISTENT SNAPSHOT ISOLATION SI)
-
- GSI 只是定义了一个范围的range,都可以作为SI使用,并没有定义具体应该选择哪个SI。
- PCSI 是为了复制集而设计的。对于一个事务Ti 要开S节点开始运行, 那么 S节点将必须包含这个事务所需要的所有前置事务都必须运行且提交。
- 相比较于GSI, PCSI的读规则,额外增加了 P1.5 规则。



- SI的提交时间戳设置,依据 A Critique of ANSI SQL Isolation Levels 中的描述, 提交时间戳的设置应该是单调递增的。新设置的时间戳,应该大于系统中已经存在的开始时间戳和提交时间戳。
- SI 读取时间戳的设置,必须保证比当前系统中正在运行的事务的最小的提交时间戳还要小, 因为一旦大于当前系统中正在运行事务的最小的提交时间戳,那么这个读事务读取到的数据就是未定义的, 取决于读事务启动的时间,而不是snapshot的时间,这违背了 一致性的要求。举例如下
-
- 当前已经完成的事务是T1,正在运行的事务是T2, 将要运行的读事务是T3, 如果 T3的读时间戳大于T2事务提交时间戳, 并且T2事务正在运行,等到T2事务执行完后。我们观察这个 database,就会发现 他违背了GSI,事务执行顺序如下所示是:
T1 commited and commitTs(1) -> T2 start -> T2 set commitTs(2) -> T3 start -> T3 set snapshotTs(3) -> T3 commit -> pointA -> T2 commit -> pointB
那么可知, T3事务实际读取的值是 T1事务的值。但根据 pointB 点来看 GSI的读规则 1.4 的要求,会发现, 如果T3读到T1的事务的修改,那么必然要求, T3和T1之间没有空洞。但实际上 T2 是落在了 T3和T1之间的, 也就是说, 违反了 GSI 1.4的读规则。
- 所以我们必须规定, SI 读取时间戳的设置,必须保证比当前系统中正在运行的事务的最小的提交时间戳还要小。
- 当前已经完成的事务是T1,正在运行的事务是T2, 将要运行的读事务是T3, 如果 T3的读时间戳大于T2事务提交时间戳, 并且T2事务正在运行,等到T2事务执行完后。我们观察这个 database,就会发现 他违背了GSI,事务执行顺序如下所示是:
MongoDB副本集时间戳应用
MongoDB 4.0的复制也是利用时间戳特性解决了3.x系列MongoDB从节点复制造成从节点性能下降的关键方案。
- MongoDB oplog 乱序问题
- MongoDB主备节点的数据同步并不基于WiredTiger的wal日志来做的。相反,mongodb会将每次操作的数据变更写入到一个叫做oplog的集合里。
- oplog这个集合,虽然名字带有log,但实际上,它是一个MongoDB的表, 对oplog的写入,并不是 append的方式修改的, 而是呈现出一种尾部乱序的方式。
- 对于oplog来说, oplog的读取顺序是按照TS字段来排序的, 跟上层的提交顺序无关。所以存在后开始的事务,在oplog先读取的场景。
- oplog 空洞
- 因为出现了乱序,所以从节点在读取oplog的时候,就会在某些时间点出现空洞。举例如下:
- 时间点1: oplog 顺序为: Ta -> Tb, 此时系统中还有一个事务Tc在运行
- 时间点2: oplog 顺序为: Ta -> Tc -> Tb, 当Tc运行结束后, 因为ts的顺序, 看起来是将Tc插入到了Ta和Tb之间。
- 那么当 从节点 在时间点1 reply 到 Tb的时候, 实际上是漏了 Tc的,这个就是oplog的空洞, 他产生的原因是因为,从节点如果每次读取oplog最新的数据,就有可能会得到一个不连续的数据, 例如 时间点1上 Ta-> Tb. 这就是oplog空洞。
- 在具体复制逻辑中,我们必须想办法来从节点读取到含有空洞的oplog数据。这也是GSI的要求, snapshot的选取不能含有空洞。
- 因为 oplog的Ts是mongo上层给的,我们很容易知道哪些事务有哪些ts, 我们再将这个ts 作为事务的commitTs 放到 oplog存储的事务里, 这样我们读取 oplog的顺序事务的可见性顺序相一致了,在这种情况下,我们就可以 根据 活跃事务列表, 就可以将oplog 分为两个部分,
- 假设活跃commitTs列表的事务是 {T10, T11, T12}, 活跃事务列表是 {T10, T11, T12, T13, T14}, 那么意味着, 目前有 T10, T11, T12, T13, T14 再运行,并且 T10, T11, T12 已经设置了 commitTs, 又因为 上面讨论的 commitTs 是单调递增的, 那么我们可知, T13, T14 的commitTs 一定大于 maxCommitTs(T10, T11, T12), 而且我们还可知, minCommitTs(T10,T11,T12) 就是全局最小的 commitTs, 而小于这些的 commitTs的事务,因为不在 活跃事务列表里了, 表示已经提交了, 那么我们可以知道, oplog ts 在 全局最小的 commitTs 之前的, 就是都提交了的, oplog 按照 commitTs 排序后,如下所示… Tx | minCommitTs(T10,T11,T12) | …我们可以知道 T9, 或者说小于 minCommitTs(T10,T11,T12) 都是无空洞,因为系统不会再提交小于 minCommitTs(T10,T11,T12) 的事务到oplog里了, 所以从节点可以直接恢复这里的数据。
- 上面说的oplog minCommitTs(T10,T11,T12) 在 mongodb里,就是特殊的timestamp, 这个后文会讲。
- 通过上面的方案,我们可以解决空洞的问题。这个时候,从节点每次恢复数据的时候,将读取的snapshot,设置为上一次恢复的Ts(同样也是无空洞的Ts), 这样的话, 从节点的恢复数据和读取数据也就做到了互不冲突。从而解决了 3.x系列的 从节点同步数据造成节点性能下降的问题。
WiredTiger对GSI的实现
上文中我们介绍了GSI的基本概念,WiredTiger在不使用timestampAPI时,实现了CSI。它的冲突检测算法如下:
Transaction's localView
Transaction -> {
// Global monotonicly increasing id, allocated when transaction starts.
txnId: int
// The local view of the global transaction list.
snapshots: []int
}
Global Transaction List
GTL -> {
// used for allocating one txn's txnId
txnIdAllocator: atomic<int>
// uncommitted transactions
activeTxns: List<Transaction*>
// protect GTL from concurrent visit
rwlock: RwLock
}
Transaction's mvcc prodecure
Begin -> {
With(GTL.rwlock.wlock()) {
txn = Transaction {
txnId: GTL.txnIdAllocator++
snapshots: GTL.activeTxns.copy()
}
GTL.activeTxns.add(txn)
}
// txns are naturalled sorted in this way.
}
Update(key, value)-> {
// get the updatelist of a key from the btree
// pick its header
upd = GetUpdateList(key).header
if (upd.txnId > self.snapshots.back()) {
throw Conflict
}
if (txn.snapshots.find(upd.txnId) {
throw Conflict
}
GetUpdateList(key).insertAtFront({self.txnId, value})
}
Commit -> {
With(GTL.rwlock.wlock()) {
GTL.activeTxns.remove(self)
}
}- 在事务开始时,对将全局未提交的事务id copy 到事务的localView中的snapshots链表中。
- 采用firstUpdateWin的冲突检测策略,在更新记录时如果违背SI,当且仅当:
- 如果key的mvcc链头的txnId 大于localView的snapshots中的最大值,
- 如果key的mvcc链头的txnId在本事务的localView的snapshots
- 上述规则是经典的CSI的实现,在PG中也是类似的做法,正确性证明请见这篇文章
|WiredTiger timestamp 与 GSI
WiredTiger中引入readTimestamp和commitTimestamp,readTimestamp即GSI中的snapshotTimestamp。
Transaction -> {
// Global monotonicly increasing id, allocated when transaction starts.
txnId: int
// The local view of the global transaction list.
snapshots: []int
read_timestamp: int
commit_timestamp: int
}
相应的冲突检测判断部分,也引入了GSI的规则
- 即本事务的read_timestamp 小于已提交key的commit_timestamp 即认为违背GSI
- 这里默认本事务的commit_timestamp 一定大于key的mvcc链中的最大的commit_timestamp,即对于某个特定的key,该key的commit_timestamp的顺序一定要和物理提交顺序一致,这是由application-level(mongoServer层)保证的,那么Mongo层是如何保证这一点的呢,请继续往下看。
Update(key, value)-> {
// get the updatelist of a key from the btree
// pick its header
upd = GetUpdateList(key).header
if (upd.txnId > self.snapshots.back()) {
throw Conflict
}
if (txn.snapshots.find(upd.txnId) {
throw Conflict
}
if (txn.read_timestamp < upd.commit_timetamp) {
throw Conflict
}
GetUpdateList(key).insertAtFront({self.txnId, value})
}
|前缀一致的复制(PrefixConsistent Replication)
MongoDB从节点拉取主节点的Oplog来实现复制,主节点上的Oplog是并行提交的,因此在Oplog的末尾存在(时间上的)乱序。如果不屏蔽乱序的话,从节点读到的Oplog就会产生空洞。举个例子:
T0: txn1.start(); txn1.setCommitTimestamp(1)
T1: txn2.start(); txn2.setCommitTimestamp(2)
T2: txn3.start(); txn3.setCommitTimestamp(3)
T3: txn3.commit() // local.oplog.rs: [3]
T4: txn1.commit() // local.oplog.rs: [1,3]
T5: txn2.commit() // local.oplog.rs: [1,2,3]
从空间上来讲,oplog的顺序就是事务的commitTimestamp顺序,即[1,2,3]的顺序。但是从时间上来讲,物理提交顺序不可控,尽管三条oplog最终会生成,但是不同时间点看到的oplog,是有空洞的。比如T4时刻的oplog是[1,3],如果从节点此刻去遍历Oplog,就会丢失commitTimetamp=2的记录。
|CommitQueue 与 AllCommitTimestamp的计算
从本质上讲,所谓前缀一致的复制,指的是,如果我读到了某条commitTimestamp = X的数据,就不允许在我读这条数据后,对数据库做出commitTimestamp < X的更改。因此,不难想到我们可以维护一个最大的没有空洞的commitTimestamp,叫做AllCommitTimestamp, 形式化的定义如下, 也就是GSI读规则的第4点,描述了不会出现空洞:

上面我们分析过,事务有commitTimestamp属性。
在wiredTiger中,事务被按照commitTimestamp排序,即
TAILQ_HEAD(__wt_txn_cts_qh, __wt_txn) commit_timestamph;
我们知道,事务开始和设置commitTimestamp不在一个临界区中,因此事务的txnId的顺序和事务的commitTimestamp顺序并不完全一样,这也是为什么wiredTiger除了维护全局的active_transaction_list这个活跃事务链之外,还维护了一个commit_timestamph的队列。active_transaction_list可以看作按照txnId有序的队列,commit_timestamph可以看作按照commitTimestamp有序的队列。commit_timestamph 队列可以用来辅助AllCommitTimestamp的计算。相关伪代码如下:
for (auto v : commit_timestamph) {
if (v.committed || v.rollbacked) {
continue;
}
return v.commit_timestamp - 1;
}
根据上述伪代码,wiredTiger中,从左往右遍历commit_timestamph队列,找到第一个没有提交的事务T,allCommitTimestamp = T.commitTimestamp – 1; 这也很容易理解,T为commitTimestamp最小的未提交事务,那么比它更小的commitTimestamp所属的事务必然都已经提交了。这里有个假设,对commit_timestamph的插入操作必然都是插入到末尾,换句话说,commitTimestamp的分配必然是递增的,这一点是由application-level(mongodb-server层)保证的,那么Mongo层是如何保证这一点的呢,请继续往下看。
MongoDB用来做复制的,读oplog的读事务,它的readTimestamp由AllCommitTimestamp得到,因此能够做到前缀一致的复制。
|遗留问题的解决
上面我们留了两个遗留问题
- Mongo如何做到对于某个特定的key,该key的commit_timestamp的顺序和物理提交顺序一致
- Mongo如何做到对commit_timestamph的插入操作必然都是插入到末尾,换句话说,commitTimestamp的分配必然是递增的
这两个问题,是wiredTiger不做任何保证的,如果违背了,数据就错乱了。MongoDB的同一段代码保证了上述两点,或者说,上述问题其实是一个问题。就是所谓的PBMA策略
1. // the global timestamp allocator
2. GTA -> {
3. lock Lock
4. globalTs int
5. }
6. // the timestamp allocation prodecure
7. Transaction txn
8. txn.Begin()
9. with(GTA.lock) {
10. txn.setCommitTimestamp(globalTs++)
11. }
12. ......
13. txn.Commit()
PBMA策略的关键要素是
- 事务先开始,再分配提交时间戳
- 分配提交时间戳要保证全局递增(加锁)
PBMA为何能一箭双雕的保证上面两个遗留问题呢,正确性的证明在这里
- 简单的说,对于某个特定的key,如果有两个事务都在修改, 那么根据事务冲突的规则可知, 这两个事务,一定是一个提交后,一个才开始的,满足 commit(Ti) < snapshot(Tj)的关系,对于本事务,也满足 snapshot(Tj) < commit(Tj) 的关系, 那么可知, commit(Ti) 是小于 commit(Tj)的, 即commit 顺序跟物理顺序相一致。
上面介绍了MongoDB副本集系统跟4.0的时间戳的一些实现, 底下我们需要了解一下在MongoDB 4.2 的分布式事务又是如何使用时间戳来实现的。
分布式系统的时钟
分布式系统,各个节点时钟的是不一致:
1,分布式各节点,时钟不一致,会导致分布式事务,无法定序。
2,对于分布式系统,一般都有时钟同步服务来保证各个节点的时间一致性。
3,但是即使存在时钟同步服务,任一时间点的绝对一致是很难达到的。这对于分布式系统来说,是不可依赖的。
4,分布式事务处理,如果不想为节点时间差专门去做逻辑处理,则需要基于一个稳定一致的时钟系统。— 即:逻辑时钟。
MongoDB sharding与时间戳的关系
|HLC与ChangeStream
从3.6之后,MongoDB就引入了HLC的概念,在实现上的体现是,Mongos/Mongod的每次操作都会带ClusterTime,ClusterTime也作为Mongos和Client交互传递的Token。HLC在MongoDB中的体现在以下几点:
- ClusterTime在Client/Mongos/Mongod的所有操作(读/写/命令)之间传递,每个进程收到更大的ClusterTime后就更新本地的ClusterTime。
- Mongod侧,Oplog的分配与物理时间的递增会作为ClusterTime推进的驱动力。
- Mongos/Mongod侧,物理时间的偏斜会作为ClusterTime推进的驱动力。
- ClusterTime传递给Client时是被签名的,以防止被篡改使得Server端的ClusterTime无限制变大。Client本身只传递不推进ClusterTime。
相关代码在 logical_clock.h::advanceClusterTime,mongos和mongod在rpc的处理函数处均有调用。
void processCommandMetadata {
return logicalClock->advanceClusterTime(signedTime.getTime());
}
通过上述HLC的机制,mongos/mongod各个进程之间的物理时钟不需要协调,集群的ClusterTime会随着mongos/mongod/configsvr的每次交互相互接近。如果没有HLC机制,各个shard之间的写操作的OplogTime相互独立,各个shard上的oplogTime没有totalOrder,全局的ChangeStream就无法实现。
|CLOCK-SI与MongoDB 的2PC分布式事务
MongoDB的2PC和CLOCK-SI paper中的算法非常接近(由于官方并未明确说明,因此并不可以说,MongoDB的2PC是对CLOCK-SI paper的实现)。MongoDB的分布式事务流程介绍可以参考这篇文章
CLOCK-SI
-
- 分布式系统中,考虑到多事务并发,对每个单个事务的开始时间是严格要求的,只有在不同节点上的单个事务都在同一个时间戳开始执行,那么多个事务在每个节点上的顺序才是一致的。考虑到分布式系统会有 clock skew (时钟偏斜) 的场景, 我们就需要在其他节点等待时间流逝到这个时间,才可以开始执行, 如下图所示:

- 上图中事务 T1,因为在P1节点是在 t时刻开始的, 所以在事务在 P2节点运行时,也需要等到t时刻才能运行, 如上图所示 P2 节点时间早于P1节点, 那么事务在P2节点,就需要等这个延迟时间。这样会造成事务执行过程中的延迟的增大。
- CLOCK-SI就是为了提出了一个方法,用来解决上面事务执行过程中的延迟问题的,读规则如下
- CLOCK-SI 的读规则提供了一个多分区情况下的一致的snapshot, 主要有两点
- 1> 如何设置事务T的SnapshotTime
- 2> 如何延迟读操作知道每个节点都有一个一致的snapshot
- 第2行,表示我们可以将snapshotTime适当的向前调整,这样,可以减少这个事务在远端节点的等待时间, 远端节点等待操作,见 第 21 和 22 行。
- 第7-9行, 如果查看的oid,发现是事务T’修改的,且T’事务正在提交,并且T’事务的提交时间小于事务T(对事物T可见的话), 那么应该等到T’提交成功后,再读取。
- 因为 commiting 也可能会提交失败, 所以事务T不能直接读取;
- 因为 已经判断了,T’ 对事务T可见,所以事务T不能忽略。
- 综上所述,事务T的读操作只能等待。
- 第 11- 15行, 与上面类似,如果 T’ 已经 prepared,且 T’ 对事务T可见,那么 读操作需要等待到T’成功提交后,再读取。原因与上面描述类似
- 21-22 行, 规定了读请求在每个节点上,都需要等到远端物理时钟到了后,才可执行。
- 分布式系统中,考虑到多事务并发,对每个单个事务的开始时间是严格要求的,只有在不同节点上的单个事务都在同一个时间戳开始执行,那么多个事务在每个节点上的顺序才是一致的。考虑到分布式系统会有 clock skew (时钟偏斜) 的场景, 我们就需要在其他节点等待时间流逝到这个时间,才可以开始执行, 如下图所示:
写规则如下
- 写规则针对事务是单点的,还是跨节点的,又分为 local commit, 和 distributed commit
- 采取两阶段的提交方式
- 先发送 prepare T 请求到所有事务参与节点
- 等待所有事务参与节点返回 T 事务已经被 prepared的结果
- 设置T 状态为 commiting状态
- 选取最大的 prepare timestamps 作为 commit timestamp, 并分配给事务T
- 记录事务T的提交时间和提交决策
- 设置事务T为commited状态
- 将 commit T 发送给所有事务参与节点
- 事务参与节点,一旦收到 prepare T的请求,
- 检查 事务 T 在本节点是否可以被修改
- 记录事务的写操作结果和协调者的id
- 将事务T状态设置为 prepared
- 设置T.prepared 时间为本地时间
- 发送 T 事务已经prepared成功的信息给事务T的协调者
- 事务参与节点, 收到 commit T的消息后
- 记录事务T 的commitTime
- 将事务T 设置为 commited 状态
|MongoDB如何处理读操作读取了处于prepare状态的值
- 可以看出,CLOCK-SI中明确定义了, 当分布式事务处于Prepare 状态时, 如果其他读事务可以看见这个 Prepare, 那么需要等到分布式事务状态变为提交后,才可以继续执行。这对应到 mongodb 4.2 代码中,在wt的 当读事务 碰到了 正在 Prepare的事务,会返回一个 WT_PREPARE_CONFLICT 来表示当前并不是一个合适时机, 我们需要等到这个写事务完成。
- 而上层的MongoDB如果碰到 WT_PREPARE_CONFLICT, 则会等待事务提交后,继续尝试读取,
int ret = wiredTigerPrepareConflictRetry(opCtx, [&] { return c->search(c); });- 所有对底层 cursor的遍历和查询操作,都会被封装到 wiredTigerPrepareConflictRetry 函数中, wiredTigerPrepareConflictRetry 会根据传入的函数对象的执行结果进行retry,
- 如果返回结果不是 WT_PREPARE_CONFLICT, 那么 wiredTigerPrepareConflictRetry 直接返回,
- 如果返回对象是 wiredTigerPrepareConflictRetry, 那么会下一次有事务提交或者abort时,再次调用函数对象检查一次。
- 更多关于 WT 层修改,参考这篇文章
为什么 commitTs=max{prepareTs}
首先我们需要明确的是,分布式事务哪怕在多个节点运行,最终的 commit timestamp 只能有一个。
因为 commit timestamp 必须大于 prepare timestamp, 所以 commitTs=max{prepareTs} 是一个合理的规定。
如果不认同上面规则, 认为 commit timestamp 可以小于某个节点的 prepare timestamp, 那会违反事务的原子性要求的,
举例如下:
- prepareTs(P1, T1) = commitTs(T1) < snapshotTs(T2) < prepareTs(P2, T1)
那么T2事务在节点1,可以看见T1的修改,但是在节点2, 是看不到 T1修改的, 这就违背了 事务的原子性的要求。
MongoDB rocks 4.0是如何支持时间戳的
主要的接口
- UserKey与InternalKey为了在RocksDB中支持时间戳,通过不同的时间戳表示在数据库中数据的不同版本。在原InternalKey的基础上增加了一个新的内容CommitTimestamp,加上原来的UserKey,LSN和数据的类型三部分内容,共四部分,如下所示。
UserKey + CommitTimestamp(8byte) + LSN + Type
- 接口定义用于控制事务的时间戳,ToTransactionDB提供了两个主要的时间戳相关的接口与之配合,具体如下:
virtual Status SetReadTimeStamp(const RocksTimeStamp& timestamp) = 0;
virtual Status SetCommitTimeStamp(const RocksTimeStamp& timestamp) = 0;
SetReadTimeStamp用于设置事务的读时间戳,同一个事务只能设置一次,在分布式事务的场景下,即使在不同分区上执行的查询也需要使用同一个读时间戳,来保证各分区上看到的数据版本的一致性。
SetCommitTimeStamp用于设置事务的提交时间戳,提交时间戳的基本要求是要大于事务的读时间戳。此外,对于同一个事务来说,可以多次调用,并且设置的提交时间戳可以不同。对于调用该接口之后的更新操作都使用此时间戳作为asif_commit_timestamps,每个asif_commit_timestamps时间戳会作为对应更新操作的InternalKey的CommitTimestamp保存到Memtable中。
主要数据结构
RocksDB数据库同样需要维护下面几个数据结构,用来管理事务RocksDB实例级别的全局时间戳信息。
- uncommitted_keys(未提交事务的UserKey列表)uncommitted_keys是保存未提交事务中发生更新的UserKey的容器,在写事务更新数据时,RocksDB将每个更新操作对应的Key插入到队列中,在事务提交时从队列中删除。当不同的事务并发执行更新操作时,则会通过此队列中保存的UserKey信息进行写冲突检测,如果已存在未提交的写事务更新了某个UserKey,则后执行更新操作的事务,会根据fisrt-update-win策略返回失败。
- committed_keys(已提交事务的UserKeyKey列表)committed_keys是保存已提交的UserKey信息的容器。在事务提交后,Key信息从uncommitted_keys队列中清除,插入到此队列中。为了进行写冲突检测维护一个uncommitted_keys队列是显而易见的,但是为什么要维护一个committed_keys队列呢?这里通过一个简单的例子进行说明这个队列的必要性。例子:针对同一个Key的两个更新事务,事务A开始时间(也就是ReadTs)为t1,更新操作Put1(A)执行时间为t3,提交时间戳为t5。那么,事务B开始时间(也就是ReadTs)为t2。对于场景1,存在更新操作Put2(B)发生在t4,则通过uncommitted_keys则可以发现存在冲突,事务B返回失败。
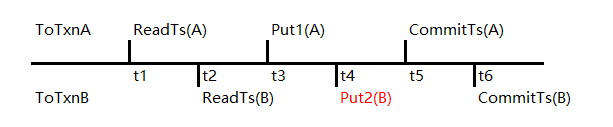
- 对于场景2,存在操作Put2(B)发生在t6,这个场景刚好对应GSI中提交规则中snapshot(Ti) < commit(Tj) < commit(Ti)描述的场景,此时,事务B需要返回写冲突失败。如果在t6这个时间点,如果没有事务A的相关信息,那么则无法判断事务B是否应该成功提交还是失败。

- read_q(读时间戳队列)前面对于committed_keys只描述了插入的规则,但是这个队列什么时候进行清理呢?会不会不断变大?答案是“不会”。从上面的例子可知,事务B只关心CommitTs比ReadTs(B)大的事务,那么,我们就可以根据这一点,制定committed_keys队列的清理规则。数据库要维护一个读时间戳队列read_q,通过它找到最小的未提交事务的ReadTs,CommitTs小于此时间戳的事务,都可以从committed_keys中清理掉,从而解决此问题。
- oldest_ts(最早可见时间戳)上面对于committed_keys的清理机制其实会有一个漏洞,就是如果事务A的信息在清理之后,如果存在一个新事务设置的ReadTs比事务A的CommitTs要早的化,则又会出现违背GSI提交规则的情况。为了解决这个问题,这里增加一个“最早的可见时间戳”oldest_ts,在调用SetReadTimeStamp接口设置ReadTs时,如果设置的时间戳小于oldest_ts,则返回失败。那么committed_keys队列清理的机制则修改为清理掉min(oldest_ts,read_q.begin().ts)之前的所有已提交事务的信息。“最早可见时间戳”的值由Mongo层进行设置,更新oldest_ts时,如果oldest_ts大于read_q.begin().ts,则取自动获取中read_q较小的为提交的ReadTs作为oldest_ts。通过增加上面几个接口和数据结构,使用RocksDB具备了基本的支持 基于时间戳事务的能力。
基本操作流程
由于引入了时间戳后,关系到数据可见性,数据清理的流程,都会涉及到对应代码逻辑的调整,在下面几个关键步骤中需要把InternalKey中的Timestamp取出进行逻辑判断。
- 写操作每个写事务开始后,首先要设置ReadTs,然后通过接口TOTransaction::Put接口进行更新操作,在执行时通过对uncommitted_keys和committed_keys的检索,进行写冲突判断。如果无写冲突,则缓存在事务的writebatch中,在事务提交时,通过DBImpl::WriteImpl把每个更新操作的UserKey进行重写,在其中增加CommitTs作为InternalKey保存到Memtable中。
- 读操作对于事务中包含更新操作的读事务,需要先从WriteBatch中write_batch_.GetFromBatchAndDB读最新数据,如果WriteBatch中无数据,则继续从Memtable和SST中继续查询,对于UserKey相同的数据,需要进行时间戳比对,当InternalKey中的时间戳大于ReadTs时,则继续遍历该UserKey的更早版本的数据,直到找到或者结束。
- Compaction操作在Compaction的过程中,旧版本数据的清洗过滤:对于哪些key的数据需要保留,哪些数据需要清除的判断逻辑中,增加了对时间戳因素的处理,需要保证大于oldest_ts的数据不会被清理。
作者:华为云dds内核组



评论前必须登录!
注册