 MongoDB中文社区
MongoDB中文社区

文本主要内容将会覆盖以下几块:
- Change Stream基本功能
- 混合逻辑时钟
- Change Stream具体处理流程
- 总结
名词解释:
- oplog:MongoDB增量记录,每次修改操作都会产生一条oplog。
- event:Change Stream中返回的一条记录,表示一次变更。
- mongos:分片集群中的proxy层。
- shard/mongod:本文中2个概念一致,都表示分片集群的单个分片。
- ResumeToken:当前oplog/event的位点,Change Stream根据这个进行断点续传。
- PBRT:Post Batch Resume Token。MongoDB中最新的ResumeToken。
- HLC:Hybrid Logical Clock。混合逻辑时钟。
- Pipeline stage:表示aggregate操作过程中的各个阶段。
- 时钟/时间戳/混合逻辑时钟/HLC:本文中这几个概念一致,都表示时间戳。
1. Change Stream基本功能
-
分析。比如我们需要对MongoDB的数据进行分析,不断拉出用户的更新,推送到下游的分析平台。 -
迁移/同步/备份。比如把A数据库热迁移到B数据库,数据库形态可以是副本集、集群版。 -
推送。比如我们用手机地图查看我们需要等待的公交离我们还有几站,我们希望每次公交位置都自动告知用户,而不是我们自己每次去不断刷新主动拉取。 -
监控。比如有些表是敏感表,我们希望这些表的变更都能告知使用方,防止攻击&误操作。 -
…
在使用watch开始监听整个数据库/db/表以后,一旦有符合条件的变更,Change Stream将会吐出一条event代表一次表更(插入/删除/修改/删除/删表等),下面是一条event的具体字段解析:
{
_id : { // 存储元信息
"_data" : <BinData|hex string> // resumeToken,用于断点续传
},
"operationType" : "<operation>", // 包括:insert, delete, replace, update, drop, rename, dropDatabase, invalidate
"fullDocument" : { <document> }, // 修改后的数据,出现在insert, replace, delete, update. 相当于oplog中的o字段
"ns" : { // db和collection的信息
"db" : "<database>",
"coll" : "<collection"
},
"to" : { // 只在operationType==rename的时候有效,表示改名以后的ns
"db" : "<database>",
"coll" : "<collection"
},
"documentKey" : { "_id" : <value> }, // 相当于o2字段。出现在insert, replace, delete, update。正常只包含_id,对于sharded collection,还包括shard key。
"updateDescription" : { // 只在operationType==update的时候出现,相当于是增量的修改,出现在$set和$uset场景,区别于replace的整个文档替换。
"updatedFields" : { <document> }, // 更新的field的值
"removedFields" : [ "<field>", ... ] // 删除的field列表
}
"clusterTime" : <Timestamp>, // 逻辑时钟,相当于ts字段
"txnNumber" : <NumberLong>, // 相当于oplog里面的txnNumber,只在事务里面出现。事务号在一个事务里面单调递增
"lsid" : { // logic session id,请求所在的session的id。相当于oplog的lsid字段。
"id" : <UUID>,
"uid" : <BinData>
}
}
Change Stream的event本身是从oplog翻译过来的,所以其中的字段跟oplog字段比较类似。可以看到每一条change stream event都包括一个ResumeToken用于断点续传。
2. 混合逻辑时钟(Hybrid Logical Clock,简称HLC)
本小节会介绍MongoDB关于HLC的使用情况,HLC的具体概念大家感兴趣的话可以查看下面几篇论文:
- Lamport逻辑时钟:time clock and the ordering of events in a distributed system
- 混合逻辑时钟:Logical Physical Clocks and Consistent Snapshots in Globally Distributed Databases
- MongoDB中的混合逻辑时钟:Implementation of Cluster-wide Logical Clock and Causal Consistency in MongoDB
{
"ts" : Timestamp(1571389994, 1), // 混合逻辑时钟
"t" : NumberLong(1),
"v" : 2,
"op" : "i",
...
}
HLC的比较是64位一起比较的:
- Timestamp(1000, 2) > Timestamp(1000, 1)
- Timestamp(1001, 1) > Timestamp(1000, 5)
 以上图为例,最开始
以上图为例,最开始{_id:1}位于shard1上面,用户执行了更新操作修改为{_id:1, a:1}。然后,发生了move chunk操作,对应{_id:1}的chunk从shard1上挪到了shard2,然后shard2上执行了更新操作:{_id:1, a:3},最后a的结果是3。但是通常情况下,对于同步工具来说,拉取不同shard是一个并发的过程,以MongoShake举例,假设此时线程1拉取shard1,线程2拉取shard2,由于shard1的cpu/带宽/内存/网络io等多种原因,导致shard2的拉取进度快于shard1了,先拉取ts=102进行回放产生的结果是{_id:1, a:3},然后是ts=100,最后{_id:1}对应的结果就是{_id:1, a:1}。这显然是不符合预期,破坏了因果序,所以MongoShake中,用户如果采用oplog进行拉取,那么对于源端MongoDB是分片集群,必须关闭balancer以规避这种情况。而在Change Stream过程中,mongos本身会对拉取到的event进行排序,从而保证了因果一致性。下面章节会具体介绍内部处理细节。
3. Change Stream具体处理流程
客户端发送的Change Stream命令是基于aggregate框架实现的,只不过添加了一个特殊的$changestream stage:
"pipeline" : [
{
"$changeStream" : {
"fullDocument" : "default",
"startAtOperationTime" : Timestamp(1580867312, 3)
}
}
],
change stream的断点续传是根据ResumeToken来进行的,下面会具体介绍其用途,这里介绍一下ResumeToken的结构:
struct ResumeTokenData {
Timestamp clusterTime; //HLC
int version = 0; // 版本号,4.0.7以前为0,4.0.7增加了PBRT,版本号为1
size_t applyOpsIndex = 0; // applyOps内部的index
Value documentKey; // 包含_id和shardKey
boost::optional<UUID> uuid; //表的uuid
};
由于ResumeToken维持不同的版本字段version,所以在版本升级后,有可能出现不同版本 token 无法识别的问题,所以尽量要让 MongoDB Server 所有组件(各个mongod,config-server、mongos)都保持相同的内核版本。下面以分片集群为例,介绍客户端、mongos、mongod对Change Stream的处理流程,其中mongos又分为消息分发和聚合2个步骤。
-
ResumeAfter。根据指定的token进行断点续传。 -
StartAfter。根据指定的token进行断点续传,与ResumeAfter不同的是,StartAfter支持从invalidate event中进行恢复。例如,监听的collection被删除了就会返回invalidate event。 -
StartAtOperationTime。根据指定的时间戳进行启动/断点续传。 -
FullDocument。正常情况下对于$set/$unset,只返回部分修改的字段,但如果FullDocument设置为updateLookup,则会返回整个更新后的文档。 -
其他配置:batchSize、MaxAwaitTime等。
$changestream的aggreate命令给MongoDB,服务端建立成功后返回cursor给客户端。客户端调用getNext获取下一条event事件,对应driver实现是查看当前缓存队列中是否还有event,有则拉出第一条直接返回给上层,没有则发送getMore命令,然后对于返回的一批event进行缓存用于下次返回。driver缓存数据的同时还会存储PBRT(resumeToken),用于处理网络抖动等连接断开情况下的自动断点续传;同时,上层应用也可以根据这个PBRT进行位点的推进以及断点续传。下面是MongoDB对于aggregate请求和getMore请求的返回的具体消息结构:/**
* Response to a successful aggregate.
*/
{
ok: 1,
cursor: {
ns: String,
id: Int64,
firstBatch: Array<ChangeStreamDocument>, // 返回的batch数据数组
/**
* postBatchResumeToken is returned in MongoDB 4.0.7 and later.
*/
postBatchResumeToken: Document // PBRT
},
operationTime: Timestamp,
$clusterTime: Document,
}
/**
* Response to a successful getMore.
*/
{
ok: 1,
cursor: {
ns: String,
id: Int64,
nextBatch: Array<ChangeStreamDocument> // 返回的batch数据数组
/**
* postBatchResumeToken is returned in MongoDB 4.0.7 and later.
*/
postBatchResumeToken: Document // PBRT
},
operationTime: Timestamp,
$clusterTime: Document,
}
$changestream aggregate分发到所有的shard。目前mongos做法,无论shard上是否有对应客户端指定的db/collection,都会进行分发。这个是为了后续用户发起shardCollection,movePrimaryShard等操作的考虑。这个构建的mongod的$changestream aggregate命令跟mongos本身收到的基本一样,但是额外添加了几个选项方便mongod逻辑处理,例如:{fromMongos: true, needsMerge: true, mergeByPBRT: true}等。这样,mongos上就构建了到各个shard的cursor。接着,根据这些mongod对应的cursor构建mergePipeline,处理各个shard返回change stream event的合并逻辑。构建mergePipeline的过程,主要就是串行添加各个stage的过程(3.4将会详细介绍各个stage的功能):-
DocumentSourceMergeCursors。合并各个shard返回的cursor。 -
DocumentSourceUpdateOnAddShard。处理新增shard的情况。 -
DocumentSourceCloseCursor。处理invalidate事件。 -
DocumentSourceLookupChangePostImage。如果是event类型是update,且设置了FullDocument=updateLoopup,则会执行额外的query。
shard收到mongos发送的$changestream aggregate请求后,构建shardPipeline,同样也包括多个stage:
DocumentSourceOplogMatch。根据指定的filter构建oplog cursor,匹配对应的oplog。DocumentSourceChangeStreamTransform。将对应的oplog翻译成change stream event。DocumentSourceCheckInvalidate。判断是否需要返回invalidate断开change stream cursor。DocumentSourceShardCheckResumability。根据指定的ResumeToken判断是否可以恢复,以及跳过某些event。
下面依次介绍各个stage做的工作:
构建oplog query cursor,其filter比较复杂,总结来说,就是过滤moveChunk,noop oplog等无关oplog,找到当前change stream所关注的oplog。下面就是具体匹配的filter:
$and:[
{"ts": {$gte: startFrom}}, // 如果指定了resumeAfter则从这个startFrom开始,否则是$gtlastAppliedTs
{$or:
[
// opMatch
{
"ns": inputNamespace,
$or: [
{"op": {$ne: "n"}}, // 不为noop, 表示是普通的CRUD操作
{"op": "n", "o2.type": "migrateChunkToNewShard"}, // chunk mirgrate到新的shard上
],
} ,
// commandMatch,DDL:
{
"op": "c",
$or: [
// commandsOnTargetDb
$and: [
{"ns": inputDb.$cmd}, //如果不是指定全局则用这个,否则是正则匹配所有除local, admin, config之外的db
$or: [
{o.drop: kRegexAllCollections}, // kRegexAllCollections表示匹配所有的collection,
{o.dropDatabase: {$exist: true}}, //drop database操作
{o.renameCollection: inputNamespace},
]
]
// renameDropTarget
{o.to: inputNamespace},
]
}
// applyOps事务
{
"op": "c",
"lsid": {$exists: true},
"txnNumber": {$exists: true},
"o.applyOps.ns": inputNamespace,
}
]
},
{"fromMigrate": {$ne: true}}
]
{fromMigrate: true})是直接过滤的,因为move chunk oplog本身只是表示挪动过程的目的端插入和源端删除操作,对于Change Stream本身来说没有实际意义,因为数据本身没有发生变更,只是位置上的变化。oplog的时钟是HLC的,从shard1挪到了shard2,则shard1和shard2的时钟都会推进,且具有因果序,所以shard1上move chunk之前的oplog时钟肯定是小于shard2上move chunk之后的oplog。从而直接对这些oplog排序即可保证因果一致性。applyTransformation将oplog翻译成对应的change stream event,这一步也是比较消耗资源,需要经历bson序列化/解序列化操作,而又因为整个pipeline本身就是单线程串行处理的过程,所以如果源端用户写入非常大,这一步可能会成为性能瓶颈。未来MongoDB可能会对这个stage进行优化,优化的方向可能:-
多线程保序解析 -
整个pipeline多线程化,每个线程处理部分数据 -
合并 DocumentSourceChangeStreamTransform和DocumentSourceOplogMatch以减少反复序列化/解序列化的开销。
判断是否返回invalidate,以下情况需要返回invalid:
- 如果是collection watch,则dropCollection,renameCollection,dropDatabase都会触发invalid。
- 如果是db watch,则dropDatabase会触发invalid。
将invalid change stream event返回,返回之前,会进行状态的本地存储,这样下次用户在当前cursor继续getNext将会继续返回该invalid change stream event。
-
kCheckNextDoc。表示mongod拉到的event比较老,需要skip一部分才能得到client token所需要的event。 -
kFoundToken。表示mongod拉到的event恰好是mongos/客户端需要的。所以直接返回即可。 -
kSurpassedToken。表示mongod拉到的event大于mongos/客户端需要的,也就是说,一部分数据已经丢了。此时,就需要返回错误了。
DocumentSourceOplogMatch中,oplog中过滤指定位点信息的只有时间戳:{"ts": {$gte: startFrom}},而没有其他更为具体的信息,比如事务applyOps中的txnOpIndex,表示事务内的偏移。举个例子,某事务包含3条语句:insert a = 1; insert a= 2; insert a = 3,返回第二条数据后cursor断开了,重连后根据时间戳恢复,如果是单机事务采用applyOps,那么时间戳都是一致的,断点续传后第一条返回是insert a=1,而客户端需要的是第三条a=3。所以需要skip前面2条。此外,还有一些情况需要处理,比如用户shardCollection,或者4.4中refine了shardKey,那么客户端携带的resumeToken跟event返回的token中documentKey是不一致的,需要一些特殊处理。mergePipeline分拆各个stage处理聚合。
这一步是用于合并各个shard返回的cursor。下面显示的mergeCursors的对于2个shard示例:
{
$mergeCursors: {
lsid: {
id: BinData(4, "DFFB25F3B9444D0CA4F790FADC73E965"),
uid: BinData(0,"E3B0C44298FC1C149AFBF4C8996FB92427AE41E4649B934CA495991B7852B855")
},
sort: {_id._data: 1}, // _id._data就是ResumeToken
compareWholeSortKey: false,
remotes: [
{
shardId: "shard1",
hostAndPort: "xx.xx.xx.xx:33001",
cursorResponse: {
cursor: {
id: 7258869757099183534,
ns: "zz.$cmd.aggregate",
firstBatch: [],
postBatchResumeToken: {
_data: "825F1BF44A000000032B0229296E04"
}
},
$_internalLatestOplogTimestamp: Timestamp(1595667530, 3),
ok: 1
}
},
{
shardId: "shard2",
hostAndPort: "xx.xx.xx.xx:33004",
cursorResponse: {
cursor: {
id: 6627263387104649979,
ns: "zz.$cmd.aggregate",
firstBatch: [],
postBatchResumeToken: {
_data: "825F1BF44A000000032B0229296E04"
}
},
$_internalLatestOplogTimestamp: Timestamp(1595667530, 3),
ok: 1
}
}
],
tailableMode: "tailableAndAwaitData",
nss: "zz.$cmd.aggregate",
allowPartialResults: false
}
}
sort: {_id._data: 1}),这里的_id._data就是ResumeToken。ResumeToken的排序就是根据内部字段ts+documentKey+uuid等多个维度进行排序。合并各个cursor的过程就是一个队列多路归并+小顶堆排序的流程:
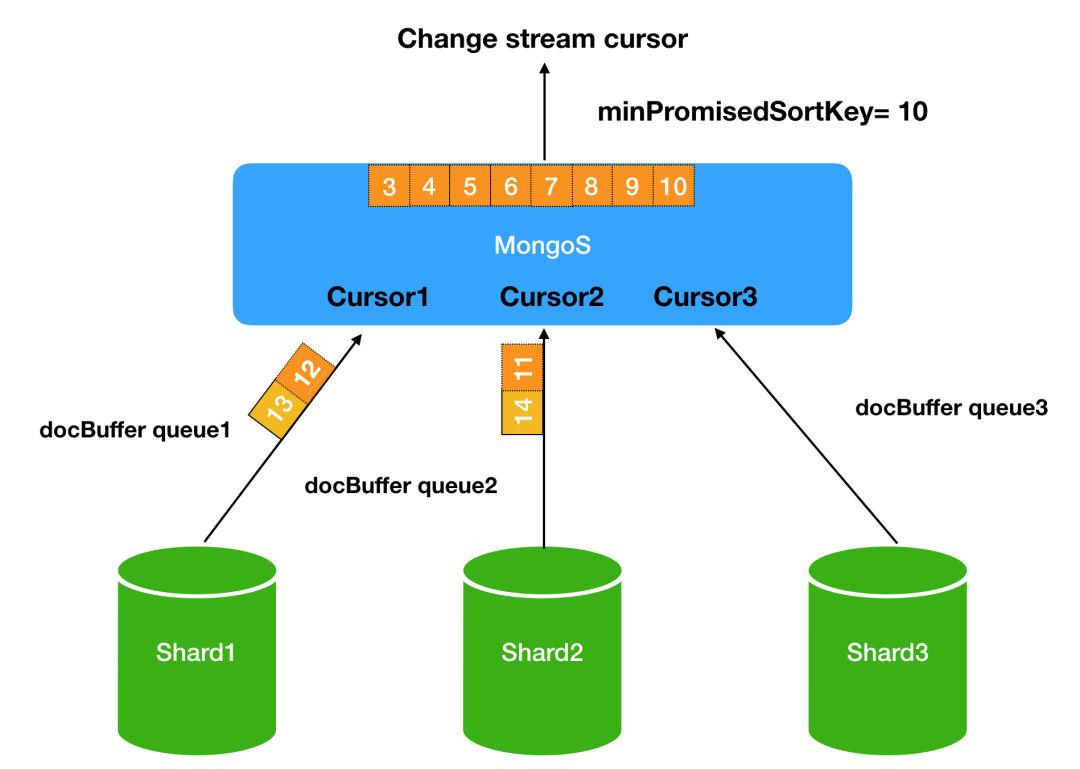
 mongos上针对每个cursor都维持了一个docBuffer queue存放拉取的change stream event,通过比较函数,每次将会找所有docBuffer queue中队列头部ResumeToken最小的event,比如上图3个队列,队列头部最小的是队列3。然后跟minPromisedSortKey进行比较,如果小于minPromisedSortKey则返回给客户端,否则将会循环等待minPromisedSortKey的推进。那么minPromisedSortKey又是什么?推进规则又是如何?这里需要先介绍一下Post Batch Resume Token(简称PBRT)。其是4.0.7推出的,标识当前MongoDB内部最大的oplog的时间戳。也就是说,如果后面MongoDB一旦产生新的oplog,则时间戳肯定大于PBRT。对于mongos来说,每个mongod的cursor getMore请求都会返回PBRT,所以这个相当于是mongod给mongos的一个承诺,承诺以后不会返回时间戳小于PBRT的event。根据这个,Change Stream实现了排序等待的策略。此外,PBRT对于应用层还有另外一个作用:可以不断推进同步的位点,举个例子,我启动一个Change Stream监听A表,但是A表自从10:00以后没有写入,全部都是其余表的写入,那么同步的位点一直停留在10:00。18:00的时候网络断开了,我根据10:00进行恢复,但是由于我的磁盘比较小,oplog只能保留5个小时,也就是说,此时最老的oplog时间戳是13:00,那么就无法恢复了。为了防止这种无法恢复,或者即使恢复也需要大面积扫描的操作(从10:00扫描oplog到18:00),PBRT的作用就体现出来了,客户端只需要不断缓存PBRT,即使A表一直没数据,位点也被不断推进到18:00,从而解决这种oplog丢失和大面积扫描的操作。回答之前的问题,minPromisedSortKey是什么?minPromisedSortKey就是所有shard中最小的PBRT:
mongos上针对每个cursor都维持了一个docBuffer queue存放拉取的change stream event,通过比较函数,每次将会找所有docBuffer queue中队列头部ResumeToken最小的event,比如上图3个队列,队列头部最小的是队列3。然后跟minPromisedSortKey进行比较,如果小于minPromisedSortKey则返回给客户端,否则将会循环等待minPromisedSortKey的推进。那么minPromisedSortKey又是什么?推进规则又是如何?这里需要先介绍一下Post Batch Resume Token(简称PBRT)。其是4.0.7推出的,标识当前MongoDB内部最大的oplog的时间戳。也就是说,如果后面MongoDB一旦产生新的oplog,则时间戳肯定大于PBRT。对于mongos来说,每个mongod的cursor getMore请求都会返回PBRT,所以这个相当于是mongod给mongos的一个承诺,承诺以后不会返回时间戳小于PBRT的event。根据这个,Change Stream实现了排序等待的策略。此外,PBRT对于应用层还有另外一个作用:可以不断推进同步的位点,举个例子,我启动一个Change Stream监听A表,但是A表自从10:00以后没有写入,全部都是其余表的写入,那么同步的位点一直停留在10:00。18:00的时候网络断开了,我根据10:00进行恢复,但是由于我的磁盘比较小,oplog只能保留5个小时,也就是说,此时最老的oplog时间戳是13:00,那么就无法恢复了。为了防止这种无法恢复,或者即使恢复也需要大面积扫描的操作(从10:00扫描oplog到18:00),PBRT的作用就体现出来了,客户端只需要不断缓存PBRT,即使A表一直没数据,位点也被不断推进到18:00,从而解决这种oplog丢失和大面积扫描的操作。回答之前的问题,minPromisedSortKey是什么?minPromisedSortKey就是所有shard中最小的PBRT:min{PBRT(mongd1), PBRT(mongod2), ...}。关于mongos合并mongod数据的过程,下面给出了归纳的伪代码流程:while (no_data() || data_from_heap_not_less_than_minPromisedSortKey()) { // 如果没有数据,或者堆顶元素大于等于minSortKey,则会一直循环
send_getMore_to_each_shard() // 发送getMore到每个shard
advance_minPromisedSortKey() // 根据返回的PBRT推进minPromisedSortKey
}
return ready_batch() // 返回一批符合条件的batch
这个stage用于有新增shard的时候,构建新的cursor到这个shard。判断的方式是发现返回的event的operationType==kNewShardDetected。这个operationType是在DocumentSourceChangeStreamTransform里面转换的:
{
"ns": inputNamespace,
$or: [
{"op": {$ne: "n"}}, // 不为noop, 表示是普通的CRUD操作
{"op": "n", "o2.type": "migrateChunkToNewShard"}, // chunk mirgrate到新的shard上
],
}
在DocumentSourceOplogMatch的时候会返回op=n,但是o2.type=migrateChunkToNewShard以表示产生了新的shard并且发生了move chunk的操作。DocumentSourceChangeStreamTransform发现有op=n的时候,就返回operationType=kNewShardDetected。
当发送invalidate事件后,则标记_shouldCloseCursor,下次再调用getNext会抛出异常,mongos上层捕获后close掉cursor。
{``fullDocument: updateLookup},则对于event的operation类型是update还会进行一次find查找(普通update操作对应的operation是replace,只有$set/$unsert对应的才是update)。如果是位于mongos,则会设置readConcern=majority,并且配置afterClusterTime时间戳为返回的event中的resumeToken中的clusterTime,为什么副本集上就没有afterClusterTime参数?因为这一步对于副本集,读到的肯定是更新以后的,因为change stream本身吐出来的节点跟当前query的节点一致。最后,调用lookupSingleDocument发送find命令进行查找。注意,这里只能够保证最终一致性。如果用户频繁更新可能会发生丢失,例如:用户更新{_id:1, a:1}为{_id:1, a:2},然后又更新为{_id:1, a:3}。则可能2个change event返回的更新后的值都是{_id:1, a:3}。这个跟DynamoDB的Stremas中吐出的event包含真实的修改后数据NewImage和修改前数据OldImage不同,MongoDB只能做到吐出修改后的数据NewImage,而这个NewImage是通过一次额外的query实现的,所以只能保证最终一致性。这个机制产生的另外一个问题就是性能问题,由于update需要进行额外的find,那么返回event的延迟就会增大。4. 总结
dropCollection、dropDatabase、renameCollection。后面MongoDB官方也会继续优化此类功能。从使用来说,Change Stream使用的门槛比较低,不像oplog拉取需要自己处理复杂的对接和断点续传。从性能来说,Change Stream跟单纯的oplog拉取还是有一定的差距,瓶颈主要位于mongod上的翻译:DocumentSourceChangeStreamTransform;此外,由于mongos对于不同shard的event有聚合“等待”的逻辑,所以实时性上来说不如oplog直接拉取,但总体来说,这个实时性是可以接受的。总的来说,使用Change Stream的优点大于缺点,而且后面MongoDB官方还会不断进行优化,推荐大家使用。最后,MongoShake对接了Change Stream,支持同步到MongoDB,以及Kafka在内的多种通道,方便大家进行迁移、同步、分析等多场景,欢迎使用!参考:
https://lamport.azurewebsites.net/pubs/time-clocks.pdf
https://cse.buffalo.edu/tech-reports/2014-04.pdf
https://dl.acm.org/doi/pdf/10.1145/3299869.3314049
https://github.com/alibaba/MongoShake
作者介绍
陈星(花名烛昭),阿里云数据库NoSQL团队技术专家,MongoShake/NimoShake/RedisShake作者,当前主要参与阿里云MongoDB的内核以及相关MongoDB产品开发和维护工作。致力于为用户提供更好的云服务以及开源生态产品。




MongoDB中文手册翻译正在进行中,欢迎更多朋友在自己的空闲时间学习并进行文档翻译,您的翻译将由社区专家进行审阅,并拥有署名权更新到中文用户手册和发布到社区微信内容平台。点击下方图片即可领取翻译任务——

更多问题可以添加社区助理小芒果微信(mongoingcom)咨询,进入社区微信交流群请备注“mongo”。



评论前必须登录!
注册