 MongoDB中文社区
MongoDB中文社区

导语
腾讯云某线上业务在使用MongoDB过程中,发现在低负载场景下也可能出现写请求阻塞。腾讯CMongo团队结合业务的使用场景,以及MongoDB中“心跳”和“同步源选择”等代码逻辑解决了这个问题。本文分析基于3.2版本-高版本已无类似问题,分享整个问题的分析和解决过程,希望能够对大家使用MongoDB有所帮助。
背景
某线上业务每间隔一段时间,使用 writeConcern:majority 方式向 MongoDB 导入一批数据。但是在整体负载非常低的情况下,发现部分写入请求很大概率会出现超时,预期 100ms 内完成的请求可能耗时超过 1s。
问题分析
单节点慢 VS 主从复制慢
回顾一下 writeConcern:majority 的大致处理流程:
- 用户向主节点写入数据和oplog。由于指定了majority写入方式,主节点会暂时hold住请求,不会立即给用户返回;
- 副本集内的从节点同步oplog并回放;
- 从节点通过 replSetUpdatePosition 内部命令给主节点反馈同步进度;
- 主节点更新副本集 majority 同步进度,并释放之前 hold 住的请求,给用户返回结果。
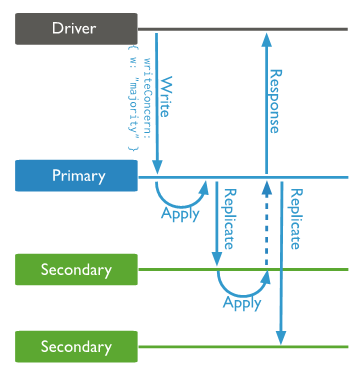
总体来说,有 2 种出现问题的可能性:单机写数据慢或者主从复制慢。初步来看,从慢日志分析可以很确定不是单机写入慢,通过 rs.printSlaveReplicationInfo 命令观察主从延迟“似乎”差距也不大。
进一步特征挖掘
仔细梳理从节点的日志,发现在超时期间 2 个从节点都有打印尝试切换同步源的日志:

如下图所示,是否“切换同步源”影响了主从同步,从而导致 majority 写入超时?

同步源选择逻辑
用户使用的 MongoDB 版本是 3.2,判断是否切换同步源的逻辑参考代码链接,通过下图公式总结一下判断规则:
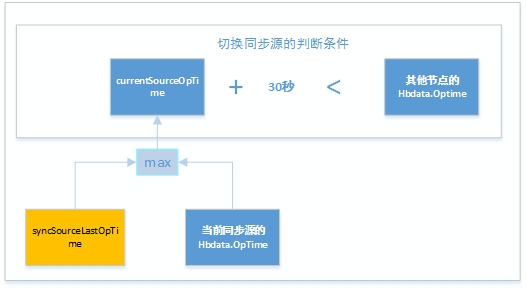
通俗来说:如果看到一个其他节点的 OpTime 比当前同步源的Optime要新 30 秒以上,自己会尝试切换新同步源。如何得知当前同步源的OpTime?一部分来源于心跳交互携带的信息;另外一部分来自于每次拉取oplog中携带的元数据信息otherfields.meta._lastOpVisible。
oplog元数据中的 lastOpVisible = std::max(lastOpTimeFromClient, lastReadableOpTime);第一个值:lastOpTimeFromClient依赖于ReplicationCoordinatorImpl::slaveInfo,依赖于MongoDB比较老旧的master/slave架构,然而严格意义上的master/slave架构有很多缺陷现在已经不推荐使用了,现在流行的是replicaset副本集架构,所以这个值无效。第二个值:lastReadableOpTime依赖于_currentCommittedSnapshot。要使这个值生效,需要打开readMajority开关。3.2默认是关闭的,所以这个值无效。
综合上面的分析,当前同步源的 OpTime 完全依赖心跳来获取。心跳信息是否可能存在误差,导致误判呢?
心跳如何导致写请求卡住
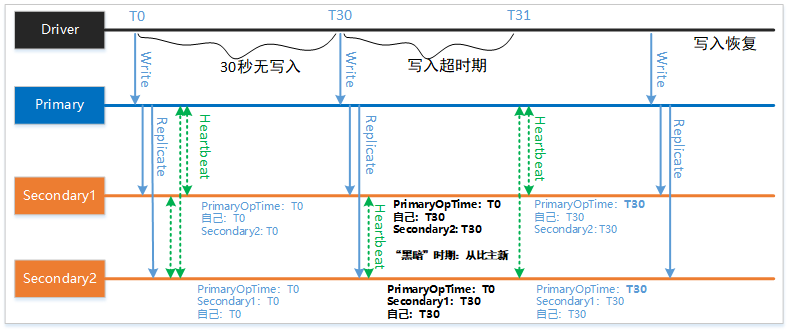
MongoDB 定期(默认2秒)交互一次心跳。考虑下面的情形:
- T0时刻,用户向副本集写入一条数据,并同步到所有节点。此时主从节点的OpTime都是T0;
- 30秒无任何数据写入。再此期间进行了多轮心跳交互,所有节点的OpTime保持T0;
- T30时刻,用户向副本集写入一条数据,并同步到所有节点。两个从节点进行了心跳交互,但是还没有和主节点进行心跳交互;
- 在T30之后短暂的时间内,从节点会产生选主误判。以 Secondary1 节点为例,它看到的 Secondary2 节点的Optime是 T30,但是主节点的 OpTime 是 T0(因为还没有进行心跳交互),触发了切换同步源逻辑。Secondary2 节点同理;
- 在切换同步源期间,从节点没有到主上同步新数据。所以新到达主节点的 majority 写入请求会被hold住,触发客户端超时;
- 副本集触发了新一轮心跳,回归正常。
解决方法
综合上面的分析,可以想到一些简单的办法来规避这个问题。比如将心跳周期从 2 秒改到更短;将落后 30 秒切同步源的条件改到更长;或者强制绑定同步关系,关闭链式复制等。
但是这些方法都不能从根本上解决问题。所以能否找到更精确反映同步源OpTime的方法是解决问题的关键。
有一个方法是:使用从同步源拉取的 oplog 中最新的 OpTime进行判断。但是单纯使用 oplog 中的 OpTime 进行判断也有缺陷,比如考虑如下 2 种情形:
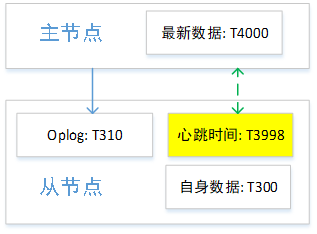
1. 主从延迟比较大如下图所示,此时从节点从心跳信息看到的主节点OpTime是T3998,但是拉取的 oplog 中 OpTime 是T310,比较旧。此时心跳时间更能准确反映主节点的 OpTime。
2. 主从延迟很小如下图所示,此时从节点拉取的 oplog 中有最新的OpTime T4000,相比于心跳时间更能准确反映主节点的 OpTime。

所以比较合理的计算方式是 max(心跳时间,oplog 中的 OpTime 时间)。
基于上面的分析,我们对“切换同步源”的判断逻辑进行了一些补充,最终消除了超时毛刺的问题。如下图所示:

总结
本文结合对 majority 写入流程进行了介绍,并通过分析心跳带来的不确定性和切换同步源逻辑的缺陷,解决了业务的超时毛刺问题。本文的分析基于MongoDB 3.2版本,高版本的 MongoDB 已经没有了类似的问题。但是希望通过这个问题的分析,能够带给大家一些启发,方便大家更好的使用MongoDB。
作者:彭振翼,腾讯CMongo团队高级工程师,主要参与腾讯MongoDB内核以及运营系统的开发和维护工作。

即将进行,我们将一起重新认识MongoDB
MongoDB,More than Document Database.

扫描上方二维码,
添加小芒果微信并回复“年会”
进行大会动态信息订阅



good job~