 MongoDB中文社区
MongoDB中文社区
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似 json 的 bson 格式,因此可以存储比较复杂的数据类型。
MongoDB 最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
什么是 GridFS
GridFS 是 MongoDB 的一个子模块,使用 GridFS 可以基于 MongoDB 来持久存储文件,并且支持分布式应用(文件分布存储和读取)。
GridFS是MongoDB提供的二进制数据存储在数据库中的解决方案,对于 MongoDB 的 BSON 格式的数据(文档)存储有尺寸限制,最大为 16M。但是在实际系统开发中,上传的图片或者文件可能尺寸会很大,此时我们可以借用 GridFS 来管理这些文件。
常用的使用场景
-
如果你的文件系统在一个目录中存储的文件的数量有限,你可以使用 GridFS 存储尽可能多的文件。
-
当你想访问大型文件的部分信息,却不想加载整个文件到内存时,您可以使用 GridFS 存储文件,并读取文件部分信息,而不需要加载整个文件到内存。
-
当你想让你的文件和元数据自动同步并部署在多个系统和设施,你可以使用 GridFS 实现分布式文件存储。
我们的使用场景
我所在的团队负责一个在线设计平台,我们有大量的设计稿文件需要上传到服务器上,即允许设计师在平台上传 PSD / SKETCH 等设计源文件。
一开始我们其实是基于单机开发的模式,默认上传到本地文件存储的形式,但部署的时候发现需要支持分布式部署,而不是只部署一台机器,且时间非常紧迫,因为已经到了 deadline。
分布式部署也就意味着我们之前存在本地的方式不可取,假定我们有两台机器 A B,如果文件落到 A,则我们在 B 无法读取到该文件,就会出现程序异常。
我们迅速调研了相关解决方案,最后看到 MongoDB 可以支持文件存储到数据库,也就是 GridFS,评估接入成本后发现也不高,立即定下了这个方案!
最后大概花了半天时间就实现了 GridFS 上传的相关代码,项目在 deadline 前一刻顺利上线。
GridFS 存储原理
GridFS 使用两个集合(collection)存储文件。一个集合是 chunks, 用于存储文件内容的二进制数据;一个集合是 files,用于存储文件的元数据。
GridFS 会将两个集合放在一个普通的 buket 中,并且这两个集合使用 buket 的名字作为前缀。MongoDB 的 GridFs 默认使用 fs 命名的 buket 存放两个文件集合。因此存储文件的两个集合分别会命名为集合 fs.files ,集合 fs.chunks。
当然也可以定义不同的 buket 名字,甚至在一个数据库中定义多个 bukets,但所有的集合的名字都不得超过 MongoDB 命名空间的限制。
MongoDB 集合的命名包括了数据库名字与集合名字,会将数据库名与集合名通过“.”分隔,而且命名的最大长度不得超过 120bytes。
当把一个文件存储到 GridFS 时,如果文件大于 chunksize (每个 chunk 块大小为 256KB),会先将文件按照 chunk 的大小分割成多个 chunk 块,最终将 chunk 块的信息存储在 fs.chunks 集合的多个文档中。然后将文件信息存储在 fs.files 集合的唯一一份文档中。其中 fs.chunks 集合中多个文档中的 file_id 字段对应 fs.files 集中文档”_id”字段。
读文件时,先根据查询条件在 files 集合中找到对应的文档,同时得到“id”字段,再根据“id”在 chunks 集合中查询所有“files_id”等于“_id”的文档。最后根据“n”字段顺序读取 chunk 的“data”字段数据,还原文件。
存储过程如图下所示:
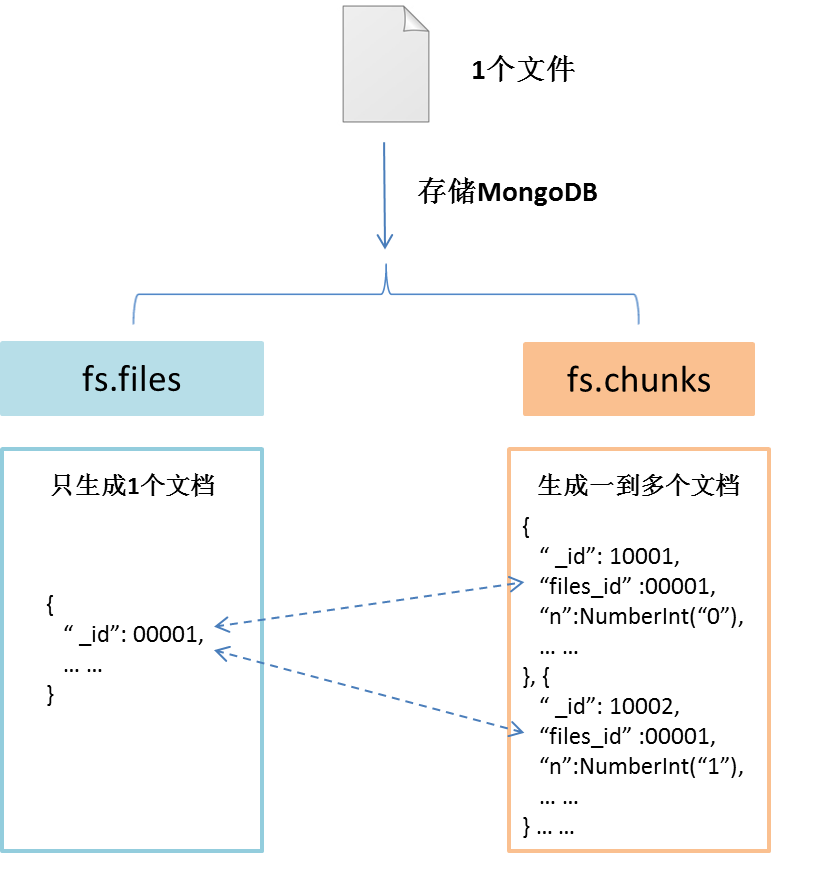
fs.files 集合存储文件的元数据,以类 json 格式文档形式存储。每在 GridFS 存储一个文件,则会在 fs.files 集合中对应生成一个文档。
fs.files 集合中文档的存储内容如下:
{ "_id": <ObjectId>, // 文档 ID,唯一标识 "chunkSize": <num>, // chunk 大小 256kb "uploadDate": <timetamp>, //文件上传时间 "length": <num>, // 文件长度 "md5": <string>, // 文件 md5 值 "filename": <string>, // 文件名 "contentType": <string>,// 文件的?MIME类型 "metadata": <dataObject>// 文件自定义信息 }
fs.chunks 集合存储文件文件内容的二进制数据,以类 json 格式文档形式存储。每在 GridFS 存储一个文件,GridFS 就会将文件内容按照 chunksize 大小(chunk 容量为 256k)分成多个文件块,然后将文件块按照类 json 格式存在.chunks 集合中,每个文件块对应 fs.chunk 集合中一个文档。一个存储文件会对应一到多个 chunk 文档。
fs.chunks 集合中文档的存储内容如下:
{ "_id": <ObjectId>, // 文档 ID,唯一标识 "files_id": <ObjectId>, // 对应 fs.files 文档的 ID "n": <num>, // 序号,标识文件的第几个 chunk "data": <binary> // 文件二级制数据 }
为了提高检索速度 MongoDB 为 GridFS 的两个集合建立了索引。fs.files 集合使用是“filename”与“uploadDate” 字段作为唯一、复合索引。fs.chunk 集合使用的是“files_id”与“n”字段作为唯一、复合索引。
如何使用 GridFS
-
shell 命令之 mongofiles
MongoDB 提供 mongofiles 工具,可以使用命令行来操作 GridFS。有四个主要命令:
Put
#mongofiles -h -u -p --db files put /conn.log connected to: 127.0.0.1 added file: { _id: ObjectId('530cf1009710ca8fd47d7d5d'), filename: "./conn.log", chunkSize: 262144, uploadDate: new Date(1393357057021), md5: "6515e95f8bb161f6435b130a0e587ccd", length: 1644981 }
Get
\#mongofiles -h -u -p --db files get /conn.log connected to: 127.0.0.1 done write to: ./conn.log
List
\# mongofiles -h -u -p list connected to: 127.0.0.1 /conn.log 1644981
Delete
[root@ip-10-198-25-43 tmp]# mongofiles -h -u -p --db files delete /conn.log connected to: 127.0.0.1
done!
-
使用 MongoDB 提供的 API
MongoDB 支持多种编程语言驱动,比如 c、java、C#、nodeJs 等。因此可以使用这些语言 MongoDB 驱动 API 操作,扩展 GridFS。
以下是一个 nodejs 版本的代码:
const mongoose = require('mongoose') const fs = require('fs') const Promise = require('bluebird') const { isString } = require('lodash') const ObjectId = mongoose.Types.ObjectId let bucket let db function init (_db) { db = _db bucket = new mongoose.mongo.GridFSBucket(db) } async function uploadFiles (files, options) { return Promise.map(files, file => // eslint-disable-line uploadFile(file.path, file.key, options), { concurrency: 3 }) } async function uploadFile (filePath, fileName, options) { return new Promise((resolve, reject) => { let openUploadStream = bucket.openUploadStream(fileName) fs.createReadStream(filePath) .pipe(openUploadStream) .on('error', function (error) { • if (options && options.deleteIfError) { • deleteFileById(openUploadStream.id) • fs.unlink(filePath) • } • reject(error) }) .on('finish', function (result) { • resolve(result) }) }) } function findFileById (id) { return new Promise((resolve, reject) => { if (isString(id)) { id = ObjectId(id) } db.collection('fs.files').findOne({ _id: id }, function (err, result) { if (err) return reject(err) resolve(result) }) }) } function deleteFileById (id) { return new Promise((resolve, reject) => { if (isString(id)) { id = ObjectId(id) } bucket.delete(id, function (err) { resolve(!err) }) }) } function getStreamById (id) { if (isString(id)) { id = ObjectId(id) } return bucket.openDownloadStream(id) } module.exports = { init, uploadFiles, uploadFile, findFileById, deleteFileById, getStreamById, }
磁盘空间优化
MongoDB 不会释放已经占用的硬盘空间。即使删除 db 中的集合 ,MongoDB 也不会释放磁盘空间。同样,如果使用 GridFS 存储文件,从 GridFS 存储中删除无用的垃圾文件,MongoDB 依然不会释放磁盘空间的。这会造成磁盘一直在消耗,而无法回收利用的问题。
那怎样才能释放磁盘空间呢?
-
可以通过修复数据库来回收磁盘空间,即在 mongo shell 中运行 db.repairDatabase() 命令或者 db.runCommand({ repairDatabase: 1 }) 命令。(此命令执行比较慢)。 使用通过修复数据库方法回收磁盘时需要注意,待修复磁盘的剩余空间必须大于等于存储数据集占用空间加上 2G,否则无法完成修复。因此使用 GridFS 大量存储文件必须提前考虑设计磁盘回收方案,以解决 MongoDB 磁盘回收问题。
-
使用 dump & restore 方式,即先删除 MongoDB 数据库中需要清除的数据,然后使用 mongodump 备份数据库。备份完成后,删除 MongoDB 的数据库,使用 Mongorestore 工具恢复备份数据到数据库。
当使用 db.repairDatabase() 命令没有足够的磁盘剩余空间时,可以采用 dump & restore 方式回收磁盘资源。如果 MongoDB 是副本集模式,dump & restore 方式可以做到对外持续服务,在不影响 MongoDB 正常使用下回收磁盘资源。
MongoDB 使用副本集, 实践使用 dump & restore 方式,回收磁盘资源。70G 的数据在 2 小时之内完成数据清理及磁盘回收,并且整个过程不影响 MongoDB 对外服务,同时可以保证处理过程中数据库增量数据的完整。
注意
GridFs 并非银弹,它还是有一些局限性:
-
存储规模,如果你的存储量是不断增加的,或者你预估的规模是比较大的话,还是建议存储到文件服务器上。
-
原子更新,GridFs 没有提供对文件的原子更新方式。



评论前必须登录!
注册