 MongoDB中文社区
MongoDB中文社区

杨亚洲老师将于2020年MongoDB中文社区年终大会上分享OPPO万亿级文档数据库MongoDB集群性能优化实践,点击此处查看活动详情。 http://hdxu.cn/RInMN
1. 说明
本文分析网络传输层模块中的最后一个子模块:service_executor服务运行子模块,即线程模型子模块。在阅读该文章前,请提前阅读下<<MongoDB网络传输处理源码实现及性能调优-体验内核性能极致设计>>、<<transport_layer网络传输层模块源码实现二>>、<<transport_layer网络传输层模块源码实现三>>,这样有助于快速理解本文分享的线程模型子模块。
线程模型设计在数据库性能指标中起着非常重要的作用,因此本文将重点分析MongoDB服务层线程模型设计,体验MongoDB如何通过优秀的工作线程模型来达到多种业务场景下的性能极致表现。
service_executor线程模型子模块,在代码实现中,把线程模型分为两种:synchronous线程模式和adaptive线程模型,这两种线程模型中用于任务调度运行的线程统称为worker工作线程。MongoDB启动的时候通过配置参数net.serviceExecutor来确定采用那种线程模式运行mongo实例,配置方式如下:
//synchronous同步线程模式配置,一个链接已给线程 net: serviceExecutor: synchronous //动态线程池模式配置 net: serviceExecutor: adaptive
2. synchronous同步线程模型(一个链接已给线程)设计原理及核心代码实现
Synchronous同步线程模型也就是每接收到一个链接,就创建一个线程专门负责该链接对应所有的客户端请求,也就是该链接的所有访问至始至终由同一个线程负责处理。
2.1 核心代码实现原理
该线程模型核心代码实现由ServiceExecutorSynchronous类负责,该类注意成员变量和重要接口如下:
//同步线程模型对应ServiceExecutorSynchronous类 class ServiceExecutorSynchronous final : public ServiceExecutor { public: //ServiceExecutorSynchronous初始化 explicit ServiceExecutorSynchronous(ServiceContext* ctx); //获取系统CPU个数 Status start() override; //shutdown处理 Status shutdown(Milliseconds timeout) override; //线程管理及任务入队处理 Status schedule(Task task, ScheduleFlags flags) override; //同步线程模型对应mode Mode transportMode() const override { return Mode::kSynchronous; } //获取该模型统计信息 void appendStats(BSONObjBuilder* bob) const override; private: //私有线程队列 static thread_local std::deque<Task> _localWorkQueue; //递归深度 static thread_local int _localRecursionDepth; //空闲线程数,例如某个链接当前没有请求,则该线程阻塞在读操作上面等待数据读到来 static thread_local int64_t _localThreadIdleCounter; //shutdown的时候设置为false,链接没关闭前一直为true AtomicBool _stillRunning{false}; //当前conn线程数,参考ServiceExecutorSynchronous::schedul AtomicWord<size_t> _numRunningWorkerThreads{0}; //cpu个数 size_t _numHardwareCores{0}; };
ServiceExecutorSynchronous类核心成员变量及其功能说明如下:
| 成员变量 | 功能说明 |
|---|---|
| _localWorkQueue | 线程私有队列,避免函数过读递归调用引起堆栈溢出 |
| _localRecursionDepth | 递归深度,默认值8 |
| _localThreadIdleCounter | 用于控制线程执行任务的时候,执行多少次任务后运行一次markThreadIdle,也就是控制线程短暂休息的频度 |
| _stillRunning | 该线程是否可以正常running |
| _numRunningWorkerThreads | 当前worker线程数,也就是客户端链接数 |
| _numHardwareCores | 服务器CPU核心数 |
每个链接对应的线程都有三个私有成员,分别是:线程队列、递归深度、idle频度,这三个线程私有成员的作用如下:
1) _localWorkQueue:线程私有队列,task任务入队及出队执行都是通过该队列完成
2) _localRecursionDepth:任务递归深度控制,避免堆栈溢出
3) _localThreadIdleCounter:当线程运行多少次任务后,需要短暂的休息一会儿,默认运行0xf次task任务就调用markThreadIdle()一次
同步线程模型子模块最核心的代码实现如下:
//ServiceStateMachine::_scheduleNextWithGuard 启动新的conn线程 Status ServiceExecutorSynchronous::schedule(Task task, ScheduleFlags flags) { //如果_stillRunning为false,则直接返回 if (!_stillRunning.load()) { return Status{ErrorCodes::ShutdownInProgress, "Executor is not running"}; } //队列不为空,说明由任务需要运行,同步线程模型只有新连接第一次通过SSM进入该函数的时候为空 //其他情况都不为空 if (!_localWorkQueue.empty()) { //kMayYieldBeforeSchedule标记当返回客户端应答成功后,开始接收下一个新请求,这时候会设置该标记 if (flags & ScheduleFlags::kMayYieldBeforeSchedule) { //也就是如果该链接对应的线程如果连续处理了0xf个请求,则需要休息一会儿 if ((_localThreadIdleCounter++ & 0xf) == 0) { //短暂休息会儿后再处理该链接的下一个用户请求 //实际上是调用TCMalloc MarkThreadTemporarilyIdle实现 markThreadIdle(); } //链接数即线程数超过了CPU个数,则每处理完一个请求,就yield一次 if (_numRunningWorkerThreads.loadRelaxed() > _numHardwareCores) { stdx::this_thread::yield();//线程本次不参与CPU调度,也就是放慢脚步 } } //带kMayRecurse标识,说明即将调度执行的是dealTask //如果递归深度小于synchronousServiceExecutorRecursionLimit,则执行task if ((flags & ScheduleFlags::kMayRecurse) && (_localRecursionDepth < synchronousServiceExecutorRecursionLimit.loadRelaxed())) { ++_localRecursionDepth; //递归深度没有超限,则直接执行task,不用入队 task(); } else { //入队,等待 _localWorkQueue.emplace_back(std::move(task)); } return Status::OK(); } //创建conn线程,线程名conn-xx(实际上是从listener线程继承过来的,这时候的Listener线程是父线程,在 //ServiceStateMachine::start中已通过线程守护ThreadGuard改为conn-xx),执行对应的task Status status = launchServiceWorkerThread([ this, task = std::move(task) ] { //说明来了一个新链接,线程数自增 int ret = _numRunningWorkerThreads.addAndFetch(1); //新链接到来的第一个任务实际上是readTask任务 _localWorkQueue.emplace_back(std::move(task)); while (!_localWorkQueue.empty() && _stillRunning.loadRelaxed()) { //每次任务如果是通过线程私有队列获取运行,则恢复递归深度为初始值1 _localRecursionDepth = 1; //取出该线程拥有的私有队列上的第一个任务运行 _localWorkQueue.front()(); //该任务已经执行完毕,把该任务从队列移除 _localWorkQueue.pop_front(); } //走到这里说明线程异常了或者需要退出,如链接关闭,需要消耗线程 ...... }); return status; }
从上面的代码可以看出,worker工作线程通过localRecursionDepth控制task任务的递归深度,当递归深度超过最大深度synchronousServiceExecutorRecursionLimit值,则把任务到localWorkQueue队列,然后从队列获取task任务执行。
此外,为了达到性能的极致发挥,在每次执行task任务的时候做了如下细节设计,这些细节设计在高压力情况下,可以提升5%的性能提升:
1) 每运行oxf次任务,就通过markThreadIdle()让线程idle休息一会儿
2) 如果线程数大于CPU核数,则每执行一个任务前都让线程yield()一次
2.2该模块函数接口总结大全
synchronous同步线程模型所有接口及其功能说明如下表所示:
| 类名 | 函数接口 | 功能说明 |
|---|---|---|
| ServiceExecutorSynchronous | ServiceExecutorSynchronous(…) | 构造初始化 |
| start() | 获取CPU核数 | |
| shutdown(…) | Shutdown回收处理 | |
| schedule(…) | worker线程创建及task任务调度运行 | |
| appendStats(…) | 获取链接数信息 |
3. Adaptive动态线程模型设计原理及核心代码实现
adaptive动态线程模型,会根据当前系统的访问负载动态的调整线程数,当线程CPU工作比较频繁的时候,控制线程增加工作线程数;当线程CPU比较空闲后,本线程就会自动销毁退出,总体worker工作线程数就会减少。
3.1 动态线程模型核心源码实现
动态线程模型核心代码实现由ServiceExecutorAdaptive负责完成,该类核心成员变量及核心函数接口如下:
class ServiceExecutorAdaptive : public ServiceExecutor { public: //初始化构造 explicit ServiceExecutorAdaptive(...); explicit ServiceExecutorAdaptive(...); ServiceExecutorAdaptive(...) = default; ServiceExecutorAdaptive& operator=(ServiceExecutorAdaptive&&) = default; virtual ~ServiceExecutorAdaptive(); //控制线程及worker线程初始化创建 Status start() final; //shutdown处理 Status shutdown(Milliseconds timeout) final; //任务调度运行 Status schedule(Task task, ScheduleFlags flags) final; //adaptive动态线程模型对应Mode Mode transportMode() const final { return Mode::kAsynchronous; } //统计信息 void appendStats(BSONObjBuilder* bob) const final; //获取runing状态 int threadsRunning() { return _threadsRunning.load(); } //新键一个worker线程 void _startWorkerThread(); //worker工作线程主循环while{}处理 void _workerThreadRoutine(int threadId, ThreadList::iterator it); //control控制线程主循环,主要用于控制什么时候增加线程 void _controllerThreadRoutine(); //判断队列中的任务数和可用线程数大小,避免任务task饥饿 bool _isStarved() const; //asio网络库io上下文 std::shared_ptr<asio::io_context> _ioContext; //早期ASIO中叫io_service //TransportLayerManager::createWithConfig赋值调用 std::unique_ptr<Options> _config; //线程列表及其对应的锁 mutable stdx::mutex _threadsMutex; ThreadList _threads; //控制线程 stdx::thread _controllerThread; //TransportLayerManager::createWithConfig赋值调用 //时间嘀嗒处理 TickSource* const _tickSource; //运行状态 AtomicWord<bool> _isRunning{false}; //kThreadsRunning代表已经执行过task的线程总数,也就是这些线程不是刚刚创建起来的 AtomicWord<int> _threadsRunning{0}; //代表当前刚创建或者正在启动的线程总数,也就是创建起来还没有执行task的线程数 AtomicWord<int> _threadsPending{0}; //当前正在执行task的线程 AtomicWord<int> _threadsInUse{0}; //当前入队还没执行的task数 AtomicWord<int> _tasksQueued{0}; //当前入队还没执行的deferredTask数 AtomicWord<int> _deferredTasksQueued{0}; //TransportLayerManager::createWithConfig赋值调用 //没什么实际作用 TickTimer _lastScheduleTimer; //记录这个退出的线程生命期内执行任务的总时间 AtomicWord<TickSource::Tick> _pastThreadsSpentExecuting{0}; //记录这个退出的线程生命期内运行的总时间(包括等待IO及运行IO任务的时间) AtomicWord<TickSource::Tick> _pastThreadsSpentRunning{0}; //完成线程级的统计 static thread_local ThreadState* _localThreadState; //总的入队任务数 AtomicWord<int64_t> _totalQueued{0}; //总执行的任务数 AtomicWord<int64_t> _totalExecuted{0}; //从任务被调度入队,到真正被执行这段过程的时间,也就是等待被调度的时间 AtomicWord<TickSource::Tick> _totalSpentQueued{0}; //shutdown的时候等待线程消耗的条件变量 stdx::condition_variable _deathCondition; //条件变量,如果发现工作线程压力大,为了避免task饥饿 //通知controler线程,通知见ServiceExecutorAdaptive::schedule,等待见_controllerThreadRoutine stdx::condition_variable _scheduleCondition; };
ServiceExecutorAdaptive类核心成员变量及其功能说明如下:
| 成员名 | 功能说明 | |
|---|---|---|
| _ioContext | ASIO网络库IO调度上下文 | |
| _config | Adaptive相关配置,对应ServerParameterOptions | |
| _threadsMutex | 线程列表锁 | |
| _threads | Worker工作线程列表 | |
| _controllerThread | 控制线程,当woker工作线程负载高,队列中等待执行的task任务过多的时候创建新线程,避免task排队饥饿 | |
| _tickSource | 时间嘀嗒处理 | |
| _isRunning | 运行状态 | |
| _threadsRunning | 代表当前还在运行的worker线程总数 | |
| _threadsPending | 代表还没有执行task的线程数 | |
| _threadsInUse | 当前正在执行task的线程数 | |
| _tasksQueued | 当前入队还没执行的普通task数,也就是等待调度的普通task数(实际上就是dealTask) | |
| _deferredTasksQueued | 当前入队还没执行的deferredTask数,也就是等待调度的deferred task数(实际上就是readTask) | |
| _lastScheduleTimer | 没什么实际作用 | |
| _pastThreadsSpentExecuting | 退出的线程生命期内执行任务的总时间 | |
| _pastThreadsSpentRunning | 退出的线程生命期内运行的总时间(包括等待IO及运行IO任务的时间) | |
| _localThreadState | 完成线程级的统计 | |
| _totalQueued | 总的入队任务数 | |
| _totalExecuted | 总执行的任务数 | |
| _totalSpentQueued | 任务被调度入队,到真正被执行这段过程的时间,也就是等待被调度的时间 | |
| _deathCondition | shutdown的时候等待线程消耗的条件变量 | |
| _scheduleCondition | 条件变量,如果发现工作线程压力大,为了避免task饥饿 | |
从上面的成员变量列表看出,队列、线程这两个大类可以进一步细化为不同的小类,如下:
1) 线程:threadsRunning、threadsPending、threadsInUsed
2) 队列:totalExecuted、tasksQueued、deferredTasksQueued
从上面的ServiceExecutorAdaptive类中的核心接口函数代码实现可以归纳为如下三类:
1) 时间计数相关核心代码实现
2) Worker工作线程创建及任务调度相关核心接口代码实现
3) controler控制线程设计原理及核心代码实现
3.1.1 线程运行时间计算相关核心代码实现
线程运行时间计算核心算法如下:
//线程运行时间统计,包含两种类型时间统计 enum class ThreadTimer { //线程执行task任务的时间+等待数据的时间 Running, //只包含线程执行task任务的时间 Executing }; //线程私有统计信息,记录该线程运行时间,运行时间分为两种: //1. 执行task任务的时间 2. 如果没有客户端请求,线程就会等待,这就是线程等待时间 struct ThreadState { //构造初始化 ThreadState(TickSource* ts) : running(ts), executing(ts) {} //线程一次循环处理的时间,包括IO等待和执行对应网络事件对应task的时间 CumulativeTickTimer running; //线程一次循环处理中执行task任务的时间,也就是真正工作的时间 CumulativeTickTimer executing; //递归深度 int recursionDepth = 0; }; //获取指定which类型的工作线程相关运行时间, //例如Running代表线程总运行时间(等待数据+任务处理) //Executing只包含执行task任务的时间 TickSource::Tick ServiceExecutorAdaptive::_getThreadTimerTotal(ThreadTimer which) const { //获取一个时间嘀嗒tick TickSource::Tick accumulator; //先把已消耗的线程的数据统计出来 switch (which) { //获取生命周期已经结束的线程执行任务的总时间(只包括执行任务的时间) case ThreadTimer::Running: accumulator = _pastThreadsSpentRunning.load(); break; //获取生命周期已经结束的线程整个生命周期时间(包括空闲时间+执行任务时间) case ThreadTimer::Executing: accumulator = _pastThreadsSpentExecuting.load(); break; } //然后再把统计当前正在运行的worker线程的不同类型的统计时间统计出来 stdx::lock_guard<stdx::mutex> lk(_threadsMutex); for (auto& thread : _threads) { switch (which) { //获取当前线程池中所有工作线程执行任务时间 case ThreadTimer::Running: accumulator += thread.running.totalTime(); break; //获取当前线程池中所有工作线程整个生命周期时间(包括空闲时间+执行任务时间) case ThreadTimer::Executing: accumulator += thread.executing.totalTime(); break; } } //返回的时间计算包含了已销毁的线程和当前正在运行的线程的相关统计 return accumulator; }
Worker工作线程启动后的时间可以包含两类:1. 线程运行task任务的时间;2.线程等待客户端请求的时间。一个线程创建起来,如果没有客户端请求,则线程就会等待接收数据。如果有客户端请求,线程就会通过队列获取task任务运行。这两类时间分别代表线程”忙”和“空闲”。
线程总的“忙”状态时间=所有线程运行task任务的时间,包括已经销毁的线程。线程总的“空闲”时间=所有线程等待获取任务执行的时间,也包括已销毁的线程,线程空闲一般是没有客户端请求,或者客户端请求很少。Worker工作线程对应while(){}循环每循环一次都会进行线程私有运行时间ThreadState计数,总的时间统计就是以该线程私有统计信息为基准求和而来。
3.1.2 worker工作线程创建、销毁及task任务处理
worker工作线程在如下情况下创建或者销毁:1. 线程池初始化;2. controler控制线程发现当前线程池中线程比较”忙”,则会动态创建新的工作线程;3. 工作线程在while体中每循环一次都会判断当前线程池是否很”闲”,如果很”闲”则本线程直接销毁退出。
Worker工作线程创建核心源码实现如下:
Status ServiceExecutorAdaptive::start() { invariant(!_isRunning.load()); //running状态 _isRunning.store(true); //控制线程初始化创建,线程回调ServiceExecutorAdaptive::_controllerThreadRoutine _controllerThread = stdx::thread(&ServiceExecutorAdaptive::_controllerThreadRoutine, this); //启动时候默认启用CPU核心数/2个worker线程 for (auto i = 0; i < _config->reservedThreads(); i++) { //创建一个工作线程 _startWorkerThread(); } return Status::OK(); }
worker工作线程默认初始化为CPU/2个,初始工作线程数也可以通过指定的命令行参数来配置:adaptiveServiceExecutorReservedThreads。此外,start()接口默认也会创建一个controler控制线程。
Task任务通过SSM状态机调用ServiceExecutorAdaptive::schedule()接口入队,该函数接口核心代码实现如下:
Status ServiceExecutorAdaptive::schedule(ServiceExecutorAdaptive::Task task, ScheduleFlags flags) { //获取当前时间 auto scheduleTime = _tickSource->getTicks(); //kTasksQueued: 普通tak,也就是dealTask //_deferredTasksQueued: deferred task,也就是readTask //defered task和普通task分开记录 _totalQueued=_deferredTasksQueued+_tasksQueued auto pendingCounterPtr = (flags & kDeferredTask) ? &_deferredTasksQueued : &_tasksQueued; //相应队列 pendingCounterPtr->addAndFetch(1); ...... //这里面的task()执行后-task()执行前的时间才是CPU真正工作的时间 auto wrappedTask = [ this, task = std::move(task), scheduleTime, pendingCounterPtr ] { //worker线程回调会执行该wrappedTask, pendingCounterPtr->subtractAndFetch(1); auto start = _tickSource->getTicks(); //从任务被调度入队,到真正被执行这段过程的时间,也就是等待被调度的时间 //从任务被调度入队,到真正被执行这段过程的时间 _totalSpentQueued.addAndFetch(start - scheduleTime); //recursionDepth=0说明开始进入调度处理,后续有可能是递归执行 if (_localThreadState->recursionDepth++ == 0) { //记录wrappedTask被worker线程调度执行的起始时间 _localThreadState->executing.markRunning(); //当前正在执行wrappedTask的线程加1 _threadsInUse.addAndFetch(1); } //ServiceExecutorAdaptive::_workerThreadRoutine执行wrappedTask后会调用guard这里的func const auto guard = MakeGuard([this, start] { //改函数在task()运行后执行 //每执行一个任务完成,则递归深度自减 if (--_localThreadState->recursionDepth == 0) { //wrappedTask任务被执行消耗的总时间 //_localThreadState->executing.markStopped()代表任务该task执行的时间 _localThreadState->executingCurRun += _localThreadState->executing.markStopped(); //下面的task()执行完后,正在执行task的线程-1 _threadsInUse.subtractAndFetch(1); } //总执行的任务数,task每执行一次增加一次 _totalExecuted.addAndFetch(1); }); //运行任务 task(); }; //kMayRecurse标识的任务,会进行递归调用 dealTask进入调度的时候调由该标识 if ((flags & kMayRecurse) && //递归调用,任务还是由本线程处理 //递归深度还没达到上限,则还是由本线程继续调度执行wrappedTask任务 (_localThreadState->recursionDepth + 1 < _config->recursionLimit())) { //本线程立马直接执行wrappedTask任务,不用入队到boost-asio全局队列等待调度执行 //io_context::dispatch io_context::dispatch _ioContext->dispatch(std::move(wrappedTask)); } else { //入队 io_context::post //task入队到schedule得全局队列,等待工作线程调度 _ioContext->post(std::move(wrappedTask)); } // _lastScheduleTimer.reset(); //总的入队任务数 _totalQueued.addAndFetch(1); //kDeferredTask真正生效在这里 //如果队列中的任务数大于可用线程数,说明worker压力过大,需要创建新的worker线程 if (_isStarved() && !(flags & kDeferredTask)) {//kDeferredTask真正生效在这里 //条件变量,通知controler线程,通知_controllerThreadRoutine控制线程处理 _scheduleCondition.notify_one(); } return Status::OK(); }
从上面的分析可以看出,schedule()主要完成task任务入队处理。如果带有递归标识kMayRecurse,则通过ioContext->dispatch()接口入队,该接口再ASIO底层实现的时候实际上没有真正把任务添加到全局队列,而是直接当前线程继续处理,这样就实现了递归调用。如果没有携带kMayRecurse递归标识,则task任务通过ioContext->post()需要入队到全局队列。ASIO库的dispatch接口和post接口的具体实现可以参考:
<<MongoDB网络传输处理源码实现及性能调优-体验内核性能极致设计>>
如果任务入队到全局队列,则线程池中的worker线程就会通过全局锁竞争从队列中获取task任务执行,该流程通过如下接口实现:
//创建线程的回掉函数,线程循环主体,从队列获取task任务执行 void ServiceExecutorAdaptive::_workerThreadRoutine( int threadId, ServiceExecutorAdaptive::ThreadList::iterator state) { //设置线程模 _localThreadState = &(*state); { //worker-N线程名 std::string threadName = str::stream() << "worker-" << threadId; setThreadName(threadName); } //该线程第一次执行while中的任务的时候为ture,后面都是false //表示该线程是刚创建起来的,还没有执行任何一个task bool stillPending = true; //线程退出的时候执行以下{},都是一些计数清理 const auto guard = MakeGuard([this, &stillPending, state] { //该worker线程退出前的计数清理、信号通知处理 //...... } while (_isRunning.load()) { ...... //本次循环执行task的时间,不包括网络IO等待时间 state->executingCurRun = 0; try { //通过_ioContext和入队的任务联系起来 asio::io_context::work work(*_ioContext); //记录开始时间,也就是任务执行开始时间 state->running.markRunning(); //执行ServiceExecutorAdaptive::schedule中对应的task //线程第一次运行task任务,最多从队列拿一个任务执行 //runTime.toSystemDuration()指定一次run最多运行多长时间 if (stillPending) { //执行一个任务就会返回 _ioContext->run_one_for(runTime.toSystemDuration()); } else { // Otherwise, just run for the full run period //_ioContext对应的所有任务都执行完或者toSystemDuration超时后才会返回 _ioContext->run_for(runTime.toSystemDuration()); //io_context::run_for } ...... } //该线程第一次执行while中的任务后设置ture,后面都是false if (stillPending) { _threadsPending.subtractAndFetch(1); stillPending = false; //当前线程数比初始线程数多 } else if (_threadsRunning.load() > _config->reservedThreads()) { //代表本次循环该线程真正处理任务的时间与本次循环总时间(总时间包括IO等待和IO任务处理时间) double executingToRunning = state->executingCurRun / static_cast<double>(spentRunning); executingToRunning *= 100; dassert(executingToRunning <= 100); int pctExecuting = static_cast<int>(executingToRunning); //线程很多,超过了指定配置,并且满足这个条件,该worker线程会退出,线程比较空闲,退出 //如果线程真正处理任务执行时间占比小于该值,则说明本线程比较空闲,可以退出。 if (pctExecuting < _config->idlePctThreshold()) { log() << "Thread was only executing tasks " << pctExecuting << "% over the last " << runTime << ". Exiting thread."; break; //退出线程循环,也就是线程自动销毁了 } } } }
线程主循环主要工作内容:1. 从ASIO库的全局队列获取任务执行;2. 判断本线程是否比较”闲”,如果是则直接销毁退出。3. 线程创建起来进行初始线程名设置、线程主循环一些计数处理等。
3.1.3 controller控制线程核心代码实现
控制线程用于判断线程池是线程是否压力很大,是否比较”忙”,如果是则增加线程数来减轻全局队列中task任务积压引起的延迟处理问题。控制线程核心代码实现如下:
//controller控制线程 void ServiceExecutorAdaptive::_controllerThreadRoutine() { //控制线程线程名设置 setThreadName("worker-controller"_sd); ...... //控制线程主循环 while (_isRunning.load()) { //一次while结束的时候执行对应func ,也就是结束的时候计算为起始时间 const auto timerResetGuard = MakeGuard([&sinceLastControlRound] { sinceLastControlRound.reset(); }); //等待工作线程通知,最多等待stuckThreadTimeout _scheduleCondition.wait_for(fakeLk, _config->stuckThreadTimeout().toSystemDuration()); ...... double utilizationPct; { //获取所有线程执行任务的总时间 auto spentExecuting = _getThreadTimerTotal(ThreadTimer::Executing); //获取所有线程整个生命周期时间(包括空闲时间+执行任务时间+创建线程的时间) auto spentRunning = _getThreadTimerTotal(ThreadTimer::Running); //也就是while中执行一次这个过程中spentExecuting差值, //也就是spentExecuting代表while一次循环的Executing time开始值, //lastSpentExecuting代表一次循环对应的结束time值 auto diffExecuting = spentExecuting - lastSpentExecuting; //也就是spentRunning代表while一次循环的running time开始值, //lastSpentRunning代表一次循环对应的结束time值 auto diffRunning = spentRunning - lastSpentRunning; if (spentRunning == 0 || diffRunning == 0) utilizationPct = 0.0; else { lastSpentExecuting = spentExecuting; lastSpentRunning = spentRunning; //一次while循环过程中所有线程执行任务的时间和线程运行总时间的比值 utilizationPct = diffExecuting / static_cast<double>(diffRunning); utilizationPct *= 100; } } //也就是本while()执行一次的时间差值,也就是上次走到这里的时间和本次走到这里的时间差值大于该阀值 //也就是控制线程太久没有判断线程池是否够用了 if (sinceLastControlRound.sinceStart() >= _config->stuckThreadTimeout()) { //use中的线程数=线程池中总的线程数,说明线程池中线程太忙了 if ((_threadsInUse.load() == _threadsRunning.load()) && (sinceLastSchedule >= _config->stuckThreadTimeout())) { log() << "Detected blocked worker threads, " << "starting new reserve threads to unblock service executor"; //一次批量创建这么多线程,如果我们配置adaptiveServiceExecutorReservedThreads非常大 //这里实际上有个问题,则这里会一次性创建非常多的线程,可能反而会成为系统瓶颈 //建议mongodb官方这里最好做一下上限限制 for (int i = 0; i < _config->reservedThreads(); i++) { //创建新的worker工作线程 _startWorkerThread(); } } continue; } //当前的worker线程数 auto threadsRunning = _threadsRunning.load(); //保证线程池中worker线程数最少都要reservedThreads个 if (threadsRunning < _config->reservedThreads()) { //线程池中线程数最少数量不能比最低配置少 while (_threadsRunning.load() < _config->reservedThreads()) { _startWorkerThread(); } } //worker线程非空闲占比小于该阀值,说明压力不大,不需要增加worker线程数 if (utilizationPct < _config->idlePctThreshold()) { continue; } //走到这里,说明整体worker工作压力还是很大的 //我们在这里循环stuckThreadTimeout毫秒,直到我们等待worker线程创建起来并正常运行task //因为如果有正在创建的worker线程,我们等待一小会,最多等待stuckThreadTimeout ms //保证一次while循环时间为stuckThreadTimeout do { stdx::this_thread::sleep_for(_config->maxQueueLatency().toSystemDuration()); } while ((_threadsPending.load() > 0) && (sinceLastControlRound.sinceStart() < _config->stuckThreadTimeout())); //队列中任务数多余可用空闲线程数,说明压力有点大,给线程池增加一个新的线程 if (_isStarved()) { _startWorkerThread(); } } }
MongoDB服务层有个专门的控制线程用于判断线程池中工作线程的压力情况,以此来决定是否在线程池中创建新的工作线程来提升性能。
控制线程每过一定时间循环检查线程池中的线程压力状态,实现原理就是简单的实时记录线程池中的线程当前运行情况,为以下两类计数:总线程数_threadsRunning、
当前正在运行task任务的线程数threadsInUse。如果threadsRunning=_threadsRunning,说明所有工作线程当前都在处理task任务,这时候就会创建新的worker线程来减轻任务因为排队引起的延迟。
3.1.4 adaptive线程模型函数接口大全
前面只分析了核心的几个接口,下表列出了该模块的完整接口功能说明:
| 类名 | 函数接口 | 功能说明 |
|---|---|---|
| 无 | TicksToMicros(…) | ticks转换为以us为单位的值 |
| ServerParameterOptions | reservedThreads() | reservedThreads类初始化构造 |
| workerThreadRunTime() | 从ASIO队列获取任务执行的最大时间 | |
| runTimeJitter() | 如果配置为了0,则任务入队从队列获取任务等待时间则不需要添加一个随机数 | |
| stuckThreadTimeout() | controller控制线程最大睡眠时间 | |
| maxQueueLatency() | worker-control线程等待work pending线程的时间 | |
| idlePctThreshold() | 线程空闲百分百,决定worker线程是否退出及其controller线程启动新的worker线程 | |
| recursionLimit() | 任务递归调用的深度最大值 | |
| ServiceExecutorAdaptive | ServiceExecutorAdaptive(…) | 类构造初始化 |
| ~ServiceExecutorAdaptive() | 析构释放 | |
| start() | 控制线程和工作线程初始化 | |
| shutdown(…) | Shutdown处理 | |
| schedule(…) | 任务入队 | |
| _isStarved() | 判断队列中的任务数和可用线程数大小,避免任务task饥饿 | |
| _controllerThreadRoutine() | 控制线程主循环处理 | |
| _startWorkerThread() | 新增一个worker线程 | |
| _getThreadJitter() | 产生一个随机数,单位ms | |
| _getThreadTimerTotal(…) | 获取指定which类型的工作线程相关运行时间 | |
| _workerThreadRoutine(…) | 工作线程主循环,从队列获得任务执行 | |
| appendStats(…) | 统计信息 |
4. 总结
adaptive动态线程池模型,内核实现的时候会根据当前系统的访问负载动态的调整线程数。当线程CPU工作比较频繁的时候,控制线程增加工作线程数;当线程CPU比较空闲后,本线程就会自动消耗退出。下面一起体验adaptive线程模式下,MongoDB是如何做到性能极致设计的。
4.1 synchronous同步线程模型总结
Sync线程模型也就是一个链接一个线程,实现比较简单。该线程模型,listener线程每接收到一个链接就会创建一个线程,该链接上的所有数据读写及内部请求处理流程将一直由本线程负责,整个线程的生命周期就是这个链接的生命周期。
4.2 adaptive线程模型worker线程运行时间相关的几个统计
3.6状态机调度模块中提到,一个完整的客户端请求处理可以转换为2个任务:通过asio库接收一个完整mongodb报文、接收到报文后的后续所有处理(含报文解析、认证、引擎层处理、发送数据给客户端等)。假设这两个任务对应的任务名、运行时间分别如下表所示:
| 任务名 | 功能 | 运行时间 |
|---|---|---|
| readTask | 调用底层asio库接收一个完整MongoDB报文 | T1 |
| dealTask | 接收到报文后的后续所有处理(含报文解析、引擎层处理、发送数据给客户端等) | T2 |
客户端一次完整请求过程中,MongoDB内部处理过程=task1 + task2,整个请求过程中MongoDB内部消耗的时间T1+T2。
实际上如果fd上没有数据请求,则工作线程就会等待数据,等待数据的过程就相当于空闲时间,我们把这个时间定义为T3。于是一个工作线程总运行时间=内部任务处理时间+空闲等待时间,也就是线程总时间=T1+T2+T3,只是T3是无用等待时间。
- 单个工作线程如何判断自己处于”空闲”状态
步骤2中提到,线程运行总时间=T1 + T2 +T3,其中T3是无用等待时间。如果T3的无用等待时间占比很大,则说明线程比较空闲。
Mongodb工作线程每次运行完一次task任务后,都会判断本线程的有效运行时间占比,有效运行时间占比=(T1+T2)/(T1+T2+T3),如果有效运行时间占比小于某个阀值,则该线程自动退出销毁,该阀值由adaptiveServiceExecutorIdlePctThreshold参数指定。该参数在线调整方式:
db.adminCommand( { setParameter: 1, adaptiveServiceExecutorIdlePctThreshold: 50} )
- 如何判断线程池中工作线程“太忙”
MongoDB服务层有个专门的控制线程用于判断线程池中工作线程的压力情况,以此来决定是否在线程池中创建新的工作线程来提升性能。
控制线程每过一定时间循环检查线程池中的线程压力状态,实现原理就是简单的实时记录线程池中的线程当前运行情况,为以下两类计数:总线程数_threadsRunning、
当前正在运行task任务的线程数threadsInUse。如果threadsRunning=threadsRunning,说明所有工作线程当前都在处理task任务,这时候已经没有多余线程去asio库中的全局任务队列op_queue中取任务执行了,这时候队列中的任务就不会得到及时的执行,就会成为响应客户端请求的瓶颈点。
- 如何判断线程池中所有线程比较“空闲”
control控制线程会在收集线程池中所有工作线程的有效运行时间占比,如果占比小于指定配置的阀值,则代表整个线程池空闲。
前面已经说明一个线程的有效时间占比为:(T1+T2)/(T1+T2+T3),那么所有线程池中的线程总的有效时间占比计算方式如下:
所有线程的总有效时间TT1 = (线程池中工作线程1的有效时间T1+T2) + (线程池中工作线程2的有效时间T1+T2) + ….. + (线程池中工作线程n的有效时间T1+T2)
所有线程总运行时间TT2 = (线程池中工作线程1的有效时间T1+T2+T3) + (线程池中工作线程2的有效时间T1+T2+T3) + ….. + (线程池中工作线程n的有效时间T1+T2+T3)
线程池中所有线程的总有效工作时间占比 = TT1/TT2
- contro控制线程如何动态增加线程池中线程数
Mongodb在启动初始化的时候,会创建一个线程名为”worker-controller”的控制线程,该线程主要工作就是判断线程池中是否有充足的工作线程来处理asio库中全局队列op_queue_中的task任务,如果发现线程池比较忙,没有足够的线程来处理队列中的任务,则在线程池中动态增加线程来避免task任务在队列上排队等待。
control控制线程循环主体主要压力判断控制流程如下:
while {
#等待工作线程唤醒条件变量,最长等待stuckThreadTimeout
_scheduleCondition.wait_for(stuckThreadTimeout)
……
#获取线程池中所有线程最近一次运行任务的总有效时间TT1
Executing = _getThreadTimerTotal(ThreadTimer::Executing);
#获取线程池中所有线程最近一次运行任务的总运行时间TT2
Running = _getThreadTimerTotal(ThreadTimer::Running);
#线程池中所有线程的总有效工作时间占比 = TT1/TT2
utilizationPct = Executing / Running;
……
#代表control线程太久没有进行线程池压力检查了
if(本次循环到该行代码的时间 > stuckThreadTimeout阀值) {
#说明太久没做压力检查,造成工作线程不够用了
if(_threadsInUse == _threadsRunning) {
#批量创建一批工作线程
for(; i < reservedThreads; i++)
#创建工作线程
_startWorkerThread();
}
#control线程继续下一次循环压力检查
continue;
}
……
#如果当前线程池中总线程数小于最小线程数配置
#则创建一批线程,保证最少工作线程数达到要求
if (threadsRunning < reservedThreads) {
while (_threadsRunning < reservedThreads) {
_startWorkerThread();
}
}
……
#检查上一次循环到本次循环这段时间范围内线程池中线程的工作压力
#如果压力不大,则说明无需增加工作线程数,则继续下一次循环
if (utilizationPct < idlePctThreshold) {
continue;
}
……
#如果发现已经有线程创建起来了,但是这些线程还没有运行任务
#这说明当前可用线程数可能足够了,我们休息sleep_for会儿在判断一下
#该循环最多持续stuckThreadTimeout时间
do {
stdx::this_thread::sleep_for();
} while ((_threadsPending.load() > 0) &&
(sinceLastControlRound.sinceStart() < stuckThreadTimeout)
#如果tasksQueued队列中的任务数大于工作线程数,说明任务在排队了
#该扩容线程池中线程了
if (_isStarved()) {
_startWorkerThread();
}
}
- 实时serviceExecutorTaskStats线程模型统计信息
本文分析的mongodb版本为3.6.1,其network.serviceExecutorTaskStats网络线程模型相关统计通过db.serverStatus().network.serviceExecutorTaskStats可以查看,如下图所示:

上图的几个信息功能可以分类为三大类,说明如下:
| 大类类名 | 字段名 | 功能 |
|---|---|---|
| 无 | executor | Adaptive,说明是动态线程池模式 |
| 线程统计 | threadsInUse | 当前正在运行task任务的线程数 |
| threadsRunning | 当前运行的线程数 | |
| threadsPending | 当前创建起来,但是还没有执行过task任务的线程数 | |
| 队列统计 | totalExecuted | 线程池运行成功的任务总数 |
| tasksQueued | 入队到全局队列的任务数 | |
| deferredTasksQueued | 等待接收网络IO数据来读取一个完整mongodb报文的任务数 | |
| 时间统计 | totalTimeRunningMicros | 所有工作线程运行总时间(含等待网络IO的时间T1 + 读一个MongoDB报文任务的时间T2 + 一个请求后续处理的时间T3) |
| totalTimeExecutingMicros | 也就是T2+T3,MongoDB内部响应一个完整MongoDB耗费的时间 | |
| totalTimeQueuedMicros | 线程池中所有线程从创建到被用来执行第一个任务的等待时间 |
上表中各个字段的都有各自的意义,我们需要注意这些参数的以下情况:
threadsRunning - threadsInUse的差值越大说明线程池中线程比较空闲,差值越小说明压力越大 threadsPending越大,表示线程池越空闲 tasksQueued - totalExecuted的差值越大说明任务队列上等待执行的任务越多,说明任务积压现象越明显 deferredTasksQueued越大说明工作线程比较空闲,在等待客户端数据到来 totalTimeRunningMicros - totalTimeExecutingMicros差值越大说明越空闲
上面三个大类中的总体反映趋势都是一样的,任何一个差值越大就说明越空闲。
在后续mongodb最新版本中,去掉了部分重复统计的字段,同时也增加了以下字段,如下图所示:

新版本增加的几个统计项实际上和3.6.1大同小异,只是把状态机任务按照不通类型进行了更加详细的统计。新版本中,更重要的一个功能就是control线程在发现线程池压力过大的时候创建新线程的触发情况也进行了统计,这样我们就可以更加直观的查看动态创建的线程是因为什么原因创建的。
- MongoDB-3.6早期版本control线程动态调整动态增加线程缺陷1例
从步骤6中可以看出,control控制线程创建工作线程的第一个条件为:如果该线程超过stuckThreadTimeout阀值都没有做线程压力控制检查,并且线程池中线程数全部在处理任务队列中的任务,这种情况control线程一次性会创建reservedThreads个线程。reservedThreads由adaptiveServiceExecutorReservedThreads配置,如果没有配置,则采用初始值CPU/2。
那么问题来了,如果我提前通过命令行配置了这个值,并且这个值配置的非常大,例如一百万,这里岂不是要创建一百万个线程,这样会造成操作系统负载升高,更容易引起耗尽系统pid信息,这会引起严重的系统级问题。
不过,不用担心,最新版本的mongodb代码,内核代码已经做了限制,这种情况下创建的线程数变为了1,也就是这种情况只创建一个线程。
4.3 adaptive线程模型实时参数调优
动态线程模设计的时候,MongoDB设计者考虑到了不通应用场景的情况,因此在核心关键点增加了实时在线参数调整设置,主要包含如下7种参数,如下表所示:
| 参数名 | 作用 |
|---|---|
| adaptiveServiceExecutorReservedThreads | 默认线程池最少线程数 |
| adaptiveServiceExecutorRunTimeMillis | 工作线程从全局队列中获取任务执行,如果队列中没有任务则需要等待,该配置就是限制等待时间的最大值 |
| adaptiveServiceExecutorRunTimeJitterMillis | 如果配置为0,则任务入队从队列获取任务等待时间则不需要添加一个随机数 |
| adaptiveServiceExecutorStuckThreadTimeoutMillis | 保证control线程一次while循环操作(循环体里面判断是否需要增加线程池中线程,如果发现线程池压力大,则增加线程)的时间为该配置的值 |
| adaptiveServiceExecutorMaxQueueLatencyMicros | 如果control线程一次循环的时间不到adaptiveServiceExecutorStuckThreadTimeoutMillis,则do {} while(),直到保证本次while循环达到需要的时间值。{}中就是简单的sleep,sleep的值就是本配置项的值。 |
| adaptiveServiceExecutorIdlePctThreshold | 单个线程循环从全局队列获取task任务执行,同时在每次循环中会判断该本工作线程的有效运行时间占比,如果占比小于该配置值,则本线程自动退出销毁。 |
| adaptiveServiceExecutorRecursionLimit | 由于adaptive采用异步IO操作,因此可能存在线程同时处理多个请求的情况,这时候我们就需要限制这个递归深度,如果深度过大,容易引起部分请求慢的情况。 |
命令行实时参数调整方法如下,以adaptiveServiceExecutorReservedThreads为例,其他参数调整方法类似:db.adminCommand( { setParameter: 1, adaptiveServiceExecutorReservedThreads: xx} )
MongoDB服务层的adaptive动态线程模型设计代码实现非常优秀,有很多实现细节针对不同应用场景做了极致优化。
4.4 不同线程模型性能多场景PK
详见:<<MongoDB网络传输处理源码实现及性能调优-体验内核性能极致设计>>
4.5 Asio网络库全局队列锁优化,性能进一步提升
通过<<MongoDB网络传输处理源码实现及性能调优-体验内核性能极致设计>>一文中的ASIO库实现和adaptive动态线程模型实现,可以看出为了获取全局任务队列上的任务,需要进行全局锁竞争,这实际上是整个线程池从队列获取任务运行最大的一个瓶颈。
优化思路:我们可以通过优化队列和锁来提升整体性能,当前的队列只有一个,我们可以把单个队列调整为多个队列,每个队列一把锁,任务入队的时候通过把链接session散列到多个队列,通过该优化,锁竞争及排队将会得到极大的改善。
优化前队列架构:
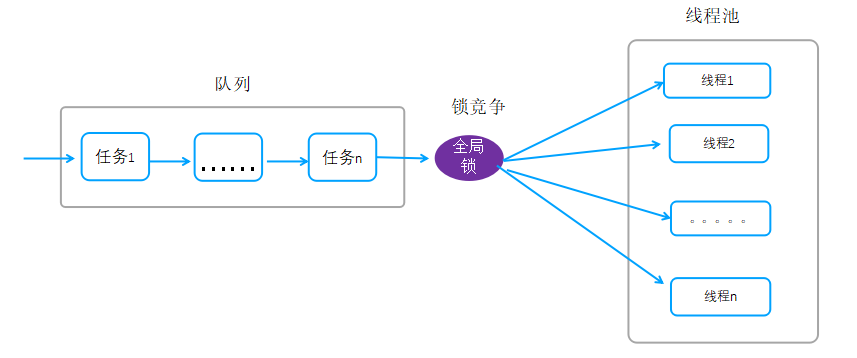
优化后队列架构:
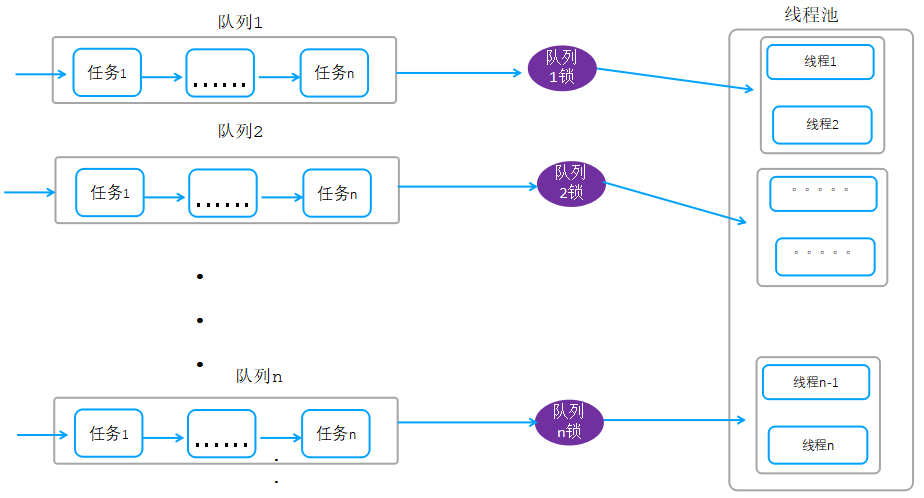
如上图,把一个全局队列拆分为多个队列,任务入队的时候把session按照hash散列到各自的队列,工作线程获取任务的时候,同理通过hash的方式去对应的队列获取任务,通过这种方式减少锁竞争,同时提升整体性能。
由于篇幅原有,本文只分析了主要核心接口源码实现,更多接口的源码实现可以参考如下地址,详见:MongoDB adaptive动态线程模型源码详细分析
更多文章:
常用高并发网络线程模型设计及MongoDB线程模型优化实践
MongoDB网络传输处理源码实现及性能调优-体验内核性能极致设计
OPPO百万级高并发MongoDB集群性能数十倍提升优化实践
MongoDB网络传输层模块源码实现二
MongoDB网络传输层模块源码实现三
作者:杨亚洲
前滴滴出行技术专家,现任OPPO文档数据库MongoDB负责人,负责oppo千万级峰值TPS/十万亿级数据量文档数据库MongoDB内核研发及运维工作,一直专注于分布式缓存、高性能服务端、数据库、中间件等相关研发。Github账号地址:





2020年MongoDB中文社区年终大会,一起重新认识MongoDB!
(2021-1-8 上海线下)



评论前必须登录!
注册