 MongoDB中文社区
MongoDB中文社区
前言:本文为2020年MongoDB应用案例与解决方案征集活动最佳创新案例:MongoDB在圆通速递的应用,作者徐靖。
最近双11当天临近下班时间点,出现应用定时JOB跑批任务卡死,导致数据没有及时计算出来,影响一次报表数据展示,这个功能跑了几个月基本上没有异常,双11业务增长几倍,数据量稍微有点大。主要包括如下内容:
- MongoDB集群架构以及读写策略
- 应用批处理异常时应用与数据库表现
- 数据库问题分析
- 如何规避与解决这个问题
MongoDB集群架构以及读写分离策略
【集群架构】
MongoDB集群是基于3.6版本,其中底层是三个副本集的PSS架构+三成员的config+3个mongos组成.副本集都是设置tag,用于跑批程序到指定从节点计算数据,降低对主库的影响。其中一个副本集的当前配置如下:

【读写分离策略】
应用端15分钟多线程聚合一次数据,每次按照部门聚合,但是分片规则是基于单号hashed来做,每次40个线程同时跑(几千部门,数据分布不均衡),执行时间几十秒可以运算完成,但cpu瞬间能够达到60%-80%波动。为了降低对主库影响,读写分离策略经过三次变化:
第一阶段, 直接主库运行,但对主库有性能问题
第二阶段,采readPreference=secondaryPreferred&maxStalenessSeconds=120参数,但MongoDB会将聚合任务下发到备库进行执行任务(下发到任一满足条件从库,而不是所有从库,由于多线程执行,所以会出现下发所有从库执行),由于存在从库与主库共用机器的情况,cpu负载还是很高,对主库性能影响降低。
第三阶段,为了解决这个,双11扩容3个物理机器,每个机器跑独立实例,同时对副本集配置tag,将聚合任务分发特定tag实例,从而解决主库cpu高问题,同时能够控制聚合任务分发。MongoDB对外URL连接串如下:
mongodb://username:password@mongodb1.db.com:31051,mongodb2.db.com:31051,mongodb3.db.com:31051/exp?readPreference=secondaryPreferred&maxStalenessSeconds=120&readPreferenceTags=usagef:reportfirst&readPreferenceTags=usages:reportsecond&readPreferenceTags=&retryWrites=true
应用批处理异常时应用与数据库表现
根据研发反馈,11.11 17.11 跑批程序卡死(提前几分钟跑,其实是慢并没有真的卡死),于是手动kill应用程序,大约几分钟后,程序跑批成功,但是17.15跑批结果是丢失,主要在客户端用于生成曲线图,相当于少一个坐标点数据(影响不是非常大,但毕竟出现小异常)
【数据库端表现】
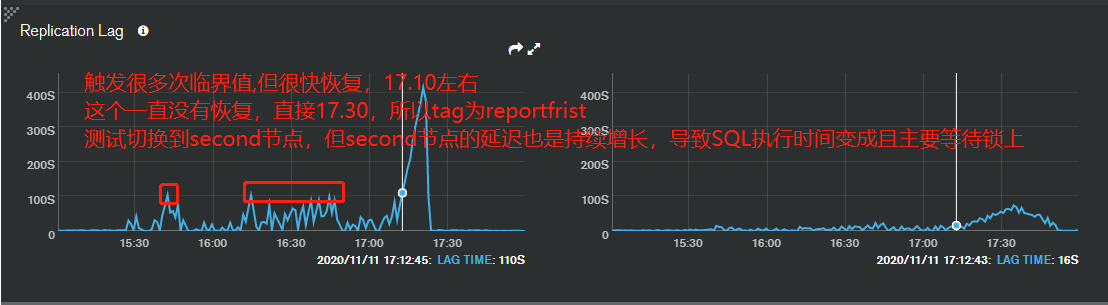
☐ 数据库主从延迟(副本集中2个从库都有延迟,其中有1个延迟在120s,另外一个超过)
【异常分片监控信息】


☐ mongod实例日志
备注:根据监控来看,tags等于reportfrist节点,在17.10延迟超过120s,所以跑批程序根据配置tag以及延迟时间120s自动切换reportsecond节点,但reportsecond也存在延迟,至少有20s到60s之间,出现应用跑批卡死了,查看SQL执行时间来看,正常执行100ms左右,变成24s,还有更慢的SQL,甚至超过几分钟的。所以应用端表现是卡死,因为后端执行慢。但SQL主要耗时在global锁等待上,而不是正在MongoDB执行时间上,这个是最主要原因(先分析表面的东西),从表现来看,就是延迟导致执行变慢.,17点之前正常的。存在如下问题:
1、SQL执行被阻塞
【图一是tag等于frist节点日志】

【图二是tag等于second节点日志因为切换到这个节点】

2、备库拉起oplog日志一直失败且一直尝试切换数据源
【如下是tag等frist节点日志,一直拉取oplogs超时,因为second节点压力大,进行跑批操作,没有响应备库拉取oplog】

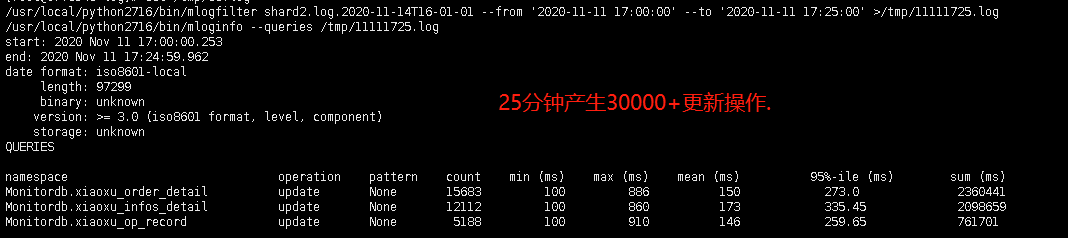
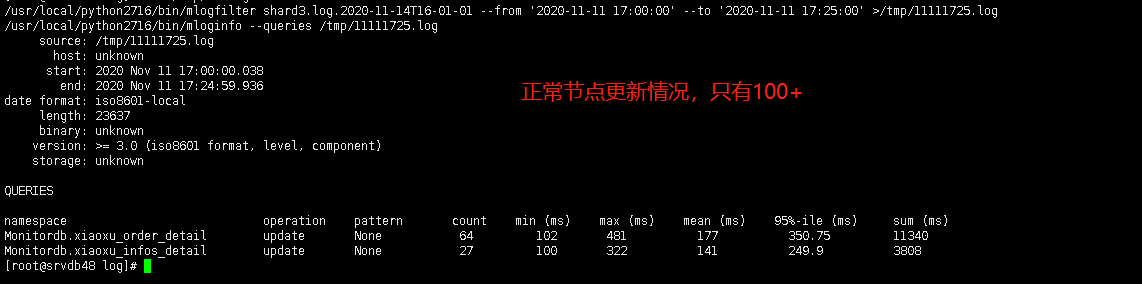
☐ mongod主库慢日志分析
备注:正常节点与异常节点,SQL执行时间基本上差不多,主要是执行次数不一样多。
【异常节点】
【正常节点】
【数据库问题分析】
☐ 主从为什么会延迟
根据官方解释主要包括如下:
- 网络延迟–同一套环境,环境环境相同,其他节点都没有这个问题,应该可以排除网络延迟问题
- 磁盘–从监控来,磁盘IOPS在40000-60000之间,所有机器性能差不多,没有特别大的异常,包括cpu都是相对稳定
- 并发–从监控来,17点到17.30出现连接翻倍的情况,这个可能会影响备库拉取oplog性能
- 写关注–应用采用默认策略,写入主库ack即可,所以这个不存在问题
备注:因为集群分片集合都是基hashed,数据很均衡,没有出现分片节点数据差别很大的情况,所以目前主从延迟根因很难判断,主从延迟只是双11当天出现过,其他时间没有出现过。因为双11当天有限流,下午开始取消限流,可能导致数据库一瞬间波动造成的延迟(出现偶发的情况)
☐ SQL执行为什么会等待锁,被阻塞
因为我们的聚合SQL对时效不是非常敏感,因为是多线程执行聚合,每一个线程按照部门取聚合的,有几百到几千部门,只是关注总时间,总执行时间在1分钟内(有的SQL都是毫秒级别),双11执行异常,分析具体慢SQL才发现很多主要等待在获取锁上,所以出现异常。查询官方文档以及mongodb官方博客,mongodb 4.0之前版本备库写会阻塞读,平时没有延迟所以备库阻塞读的时间非常短。
《https://www.mongodb.com/blog/post/secondary-reads-mongodb-40》
《https://mongoing.com/archives/13473》


☐ 备库拉取oplog失败
4.4版本之前都是备库主动取获取日志,如果主库忙、网络出现问题以及磁盘等问题,会导致拉取失败的,从而导致从库不能及时应用日志,如果开始级联复制(默认开启),那么此时备库可能从其他备库拉取日志,如果数据源也延迟,那么拉取日志备库延迟概率与时间会更多,我们此次遇到延迟,就是级联复制影响,从失败里面看虽然一直尝试切换数据源,最终还是选择的都是备库,根本没有切换到其他数据源,是否切换数据源(存在一些判断条件),如果主备都满足候选数据源时,其中有一个参数maxSyncSourceLagSecs来触发再次选择同步原,这个值是30s,从监控来看17.20分,同步源本身延迟超过30s,最终重新将同步源到主库,很快恢复延迟。4.4版本中主动推动oplog。相对从库主动拉取能够提高效率。
如何规避与解决这个问题
☐ 读写分离问题
4.0之前版本如果主库压力不大,不建议读写分离,因为写会阻塞读,除非业务对响应时间不是非常关注以及读取历史数据(接受一定时间延迟),本次版本是3.6集群,我们是跑批业务且平时延迟很小,所以目前来看,读写还是可以接受。考虑明年升级到4.4版本。
☐ 备库延迟问题
1. 做好主从延迟监控告警,及时发现潜在的性能问题,比如磁盘问题、主库性能问题等
2. 如果开启级联复制(默认开启),级联数据源压力比较大,那么也会导致拉取日志失败从而造成延迟,根据实际情况是否调整级联复制.
3. 升级到4.4版本,开始支持stream replication,变成主动推oplog,那么复制效率会提升。
作者:徐靖
物流快递行业数据库运维与技术研究,主要是Oracle,MongoDB,Mysql技术。
应用案例来自:圆通速递,七牛云,平安科技,京东,以及不便分享的神秘伙伴
更多案例请期待后期分享!
主办方介绍及鸣谢

MongoDB中文社区( Mongoing.com)成这立于2014年,是大中华区获得官方认可的中文社区,经过社区志愿者们的不断努力,目前已经有超过2万的线上及线下成员。中文社区由博客、线下活动、技术问答、社群、官方文档翻译等版块组成。截至2020年社区已成功举办数十场人数超百的线下活动,发表关于MongoDB应用优质文章数百篇,相关合作单位已达20多家。中文社区的愿景是:为广大MongoDB中文爱好者创建一个活跃的互助平台;推广MongoDB成为企业数据库应用的首选方案;聚集 MongoDB开发、数据库、运维专家,打造最权威的技术社区。Mongoing中文社区公众号: mongoing – mongoingMongoing中文社区http://mongoing.com/
 上海锦木信息技术有限公司是国内领先的 MongoDB数据库服务提供商,是 MongoDB厂商官方合作伙伴。锦木信息始终坚守在数据技术领域扎实地实昽和前行,成为国内 MongoDB领域的新兴技术力量。服务的客户广泛分布于金融、电信、零售、航空等行业,助力用户完成从传统IT架构向互联网架构的顺利转型。2018年起,锦木信息与MongoDB中文社区建立了良好的合作关系,致力于共同创建繁荣的 MongoDB生态环境。上海锦木信息技术有限公司http://www.jinmuinfo.com/
上海锦木信息技术有限公司是国内领先的 MongoDB数据库服务提供商,是 MongoDB厂商官方合作伙伴。锦木信息始终坚守在数据技术领域扎实地实昽和前行,成为国内 MongoDB领域的新兴技术力量。服务的客户广泛分布于金融、电信、零售、航空等行业,助力用户完成从传统IT架构向互联网架构的顺利转型。2018年起,锦木信息与MongoDB中文社区建立了良好的合作关系,致力于共同创建繁荣的 MongoDB生态环境。上海锦木信息技术有限公司http://www.jinmuinfo.com/
 用一种崭新的方式,解一个很老的问题。让客户可以像使用自来水一样,简单地使用属于他们的数据。Tapdata,是基于MongoDB 的实时ETL及数据服务平台工具。我们的产品能够帮助那些缺乏专业数据工程师的企业提供产品化的数据解决方案。实时双向的数据同步+简单的数据治理及建模+无代码API服务式交付+百TB级亚秒级的性能,无论您是为您客户构建数据统一平台,还是构建一个横跨BU的企业级数据中台,Tapdata都可以为你提供低成本快速落地的一个有效技术方案。深圳钛铂数据有限公司https://tapdata.net/
用一种崭新的方式,解一个很老的问题。让客户可以像使用自来水一样,简单地使用属于他们的数据。Tapdata,是基于MongoDB 的实时ETL及数据服务平台工具。我们的产品能够帮助那些缺乏专业数据工程师的企业提供产品化的数据解决方案。实时双向的数据同步+简单的数据治理及建模+无代码API服务式交付+百TB级亚秒级的性能,无论您是为您客户构建数据统一平台,还是构建一个横跨BU的企业级数据中台,Tapdata都可以为你提供低成本快速落地的一个有效技术方案。深圳钛铂数据有限公司https://tapdata.net/



是不是可以使用Secondary或者SecondaryPreference实现读写分离来提高系统的承载能
力?
1、Secondary节点的写压力跟Primary基本是相同的,所以,读操作在从库上并不会提高
查询速度。
2、由于是异步复制数据,所以读Secondary的数据可能是过时的。
3、在分片架构中使用读写分离的时候有可能会丢失数据或者读到重复数据。
读写分离真的收益不大吗
1、Secondary节点的写压力跟Primary基本是相同的,所以,读操作在从库上并不会提高
查询速度。
问题:
1、其实主备的写压力不是完全一致性,备库是批量应用oplog,主库有可能是单个操作来提交的,所以说写压力并不是完全等同.
即使在写压力等同的情况下,本次读写操作,读主要聚合计算,由于专门读节点来操作,存在大并发下消耗大量CPU,避免影响主库正常的读写操作.
2、例如在跨地区的副本集或者分片,此时读本地的从节点能够解决网络的延迟问题,从而提升读响应时间,从而提升查询速度。
3、如果主备的机器性能存在瓶颈,此时读确实不会提升查询速度。如果都不存在瓶颈的话,通常情况下读写分离不会提升查询速度。
2、由于是异步复制数据,所以读Secondary的数据可能是过时的。
回答:
确实存在的这样问题,如果要求实时很高,不建议读从库,直接主库。如果能接受可控的延迟,此时可以考虑。
可以在连接串配置最大延迟时间,最小允许配置是90s.
3、在分片架构中使用读写分离的时候有可能会丢失数据或者读到重复数据。
读写分离真的收益不大吗
问题:
对于重复数据这个是由于读从节点时默认读关注是available,读主库默认是local,所以调整默认读关注即可可以解决这个问题。
对于数据丢失–这个跟写关注设置有关系,即使不是访问备库,也可能存在如write concern设置1
至于读写分离收益问题需要具体问题具体分析,对于数据库强一致或者实时非常高的,此时读写分离会带来问题。
对于实时要求不高、分析统计类(过去时间点)、跨地区的集群、主库连接太多等情况下,读写分离还是有收益的