 MongoDB中文社区
MongoDB中文社区
最近 MongoDB 群里面有群友遇到2次重启 MongoDB 后一直处于实例恢复状态(应用 OPLOG ),多达几天甚至更长才完成重启,通常 MongoDB 副本集三个实例作为标准,重启主库会发生重新选出新主节点(通常在12s内完成)重新对外服务,通常不符合官方标准化或者内部发生异常导致的。经过了解副本集采用 PSA 架构且存在一个数据从节点不可达的情况(甚至有的从节点宕机几个月没有发现),来分析这些情况以及如何应对。
主要包括以下内容:( WT 存储引擎下版本是3.2、3.4、3.6、4.0、4.2为主,4.4、5.0也存在)。
- PSA 架构下从节点宕机后,重启主库为什么会这么久
- PSA 架构还有哪些问题
- PSA 架构下如何缓解内存压力以及推荐 PSS 方案
- 模拟 PSA 架构下重启主库实例后长时间等待的情况并通过不同方案来解决
二. PSA 架构重启主库为什么会这么久
备注:有个提前是从库宕机存在一定周期且在此期间产生大量的脏数据。
2.1 官方 PSA 架构介绍
当数据节点宕机且 enableMajorityReadConcern ( WT 3.2版本开始默认开启),内存压力增大,这里只是说内存压力增大,没有进一步说明影响,比如说压力超过内存限制后如何处理、对性能的影响以及超长时间等待重启之类。(由于没有源码能力,相关东西只能通过 jira 、专家交流以及自己实验来验证)。
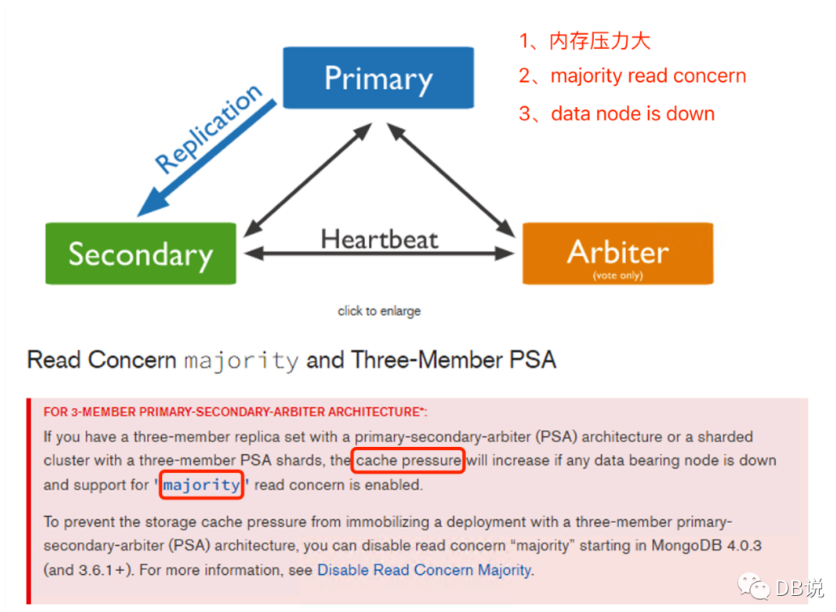
2.2 为什么会造成主库内存压力?
- 用于从副本集或者集群中读取数据时,能够允许读取到被大多数节点收到并被确认的数据,对应关系型数据库里面提交读。
注意:这里只是允许而已(数据库提供的能力,3.2版本才开始支持)。
客户端是否需要根据实际 readConcern 级别,不管我们是否需要这种 majorityReadConcern 级别,数据库 WT 引擎已经维护这些信息在内存中(默认是开启)。
- 当 PSA 副本集中存在一个数据节点宕机时,主库内存中数据的 Majority commit point 是无法推进的,此时 checkpoint 是不能将这些数据持久化(内存中脏数据无法更新到数据文件中),同时 OPLOG 会保留所有变更操作,如果从库宕机时间长且主库很忙,OPLOG 会增长很大(4.0版本开始会超过配置大小)。
- PSA 此时 checkpoint 不能对 Majority commit point 后的数据进行持久化,主库必须维护最近 Majority commit point 的快照提供给读,所以内存压力会增大和内存使用,最终这些内存数据溢出,此时 MongoDB 利用 SWAP 技术将内存中置换到磁盘上(将内存数据置换到磁盘上 WiredTigerLAS.wt ),所以性能会下降,如从库宕机时间长,此时主库性能也慢,同时磁盘空间也会暴涨。可能会考虑重启实例(通常情况下重启能解决大部分问题),那么实例可能重启需要等特几天甚至更长时间才能完成。因为数据没有持久化,重启的话就需要进行实例恢复,那么就会出现开头说重启好多天都没有完成的悲剧。重启过程这个问题会被无限循环。(4.4开始重构来缓解这个问题,使用 WiredTigerHS.wt 来替代)。最坏的情况可能会导致实例 OOM 。
三. PSA 架构还存在哪些问题
PSA 相比 PSS 少一份副本数据,相对应就 cost down. 这个是最直接好处。例如三机房部署 PSA 架构的副本集或者分片,对应 A 的机器最低配即可,不需要消耗什么资源。通常三机房采用 PSSSA 或者 PSSSS ,发生故障时优先切换本地机房。
正常情况下 PSA 正常下运行与 PSS 架构下无差别。主要出现 S 节点不可达以及长延迟情况会存在异常,除了内存压力增大造成性能的影响以及跟超长等待时间重启外,还如下常见场景:
writeConcern 或者 readConcern 为 majority ,读写会异常。majority 表示数据被副本集成员中大多数节点收到并被主确认。5.0之前版本默认 w:1,表示被主节点确认后表示操作成功,此时此群出现故障可能会导致写入主节点被回滚,从而造成数据丢失。所以 w:majority 是保证集群数据故障时不丢失的必需配置。
那么 majority 到底是多少个节点?对于 majority 是怎么计算?为什么 PSA 架构下宕机一个数据节点就不满足 majority ?
majority 节点数=最小值(副本集中所有数据节点具有的投票能力总数与副本集中1加上取整(1/2的具备投票节点总数包括仲裁节点))。默认情况下 PSA 中所有节点都具备投票能力,那么此时 majority 节点数= min (2,3(1+取整(0.5*3))) =2。从4.2.1版本开始,可以通过 rs.status() 中 writeMajorityCount 、 majorityVoteCount 来看。如果此时宕机一个数据节点或者不可达时,此时 majority 还是2,不会因为状态的改变而减少 majority 个数。此时需要满足 w:majority 的操作要不超时要不永不返回的状态。
注意:此时数据已经写入主节点,不管是超时还是永不返回,数据不会被回滚(不考虑事务的场景以及 failover 情况)。
同理3.2版本开始默认开启 enableMajorityReadConcern ,此时 majority commit point 也不会被推进。所以说 PSA 在一定程度上通过节约成本来降低系统高可用性。当然,说没有显式开启 majority ,是不是就没有问题?当存在一个数据节点不可达时,有些潜在场景默认是 majortiy 配置且不能修改,例如5.0开始 enableMajorityReadConcern 这个不能被禁用。例如 changestream 要求数据被大多数节点应用,同时也影响分片集群部分功能。
- 集群部分功能异常
分片集群数据平衡,源或者目标分片中不能满足大多数成员时,数据平衡或者扩缩分片都会失败。分片集群管理,例如 shardCollection 、 dropIndex 等要求 majoriy 都会失败。分片集群下 changeStream 同样会无法捕获最新数据造成同步延迟。
- 隐藏丢失数据操作
如果从库已经宕机 N 时间,此时主库也宕机了,如果运维人员先启动老的从库,那么会”丢 N 时间”数据,这个数据存在在原主库,此时原主库启动后需要先回滚 N 时间数据才能重新加入到副本集中,通常回滚有限制,大概率会回滚失败。
四. 如何缓解内存压力
4.1 缓解内存压力
- 避免一个数据节点实例宕机情况下对系统的影响,通过完善的监控及时发现节点异常(宕机、延迟),及时处理故障,否则无能为力。
- 禁用 MajorityReadConcern ( PSA 架构来避免内存压力,同时注意 changeStream ,4.2版本不管这个参数,对于出现问题的集群或者副本集。
- 临时将异常从库的优先级别与投票都设置为0(5.0版本由于不能禁用 MajorityReadConcern ,注意这个只能修改下应对从库宕机或延迟时,来缓解主库内存压力以及解决一些配置 majority 场景,但失去高可用,因为从库不能被选为主。适用场景是数据库需要重启时存在大量脏数据刷盘或者应用配置 w:majority 时,修改宕机实例优先级别与投票为0后进行重启才可以,如果已经重启的实例,此时只能等待)。
总结: PSA 解决从库宕机后如何缓解主库内存压力,通过有效监控及时消除故障点,如果没有及时发现,在重启前通过方案3来避免长时间重启问题,针对方案2需要提前规划好,但对于 majority 场景以及分片模式下操作还是无能为力,如果从库宕机很久,此时已强制重启主库,此时只能进入躺平状态去等。其他解决方案需要具体问题具体分析,例如只要系统能写入数据即可,可以把从实例恢复起来或者搭建空实例。
4.2 推荐方案
尽管通过禁用参数或者修改配置来缓解问题,但存在潜在的问题或者不熟悉的人还是会遇到同样问题,条件允许情况下,应使用 PSS 取代 PSA 架构能够解决单一数据节点宕机带来的影响。如果正在使用 PSA 架构也没有关系,知道存在问题即可,出现问题能够知道带来的影响是什么即可。
备注:搭建4.2 PSA 副本集,手动 S 实例关闭并通过 POC 压测数据,构造20个字段1.1亿表。
5.1 查看数据情况
亿 show dbs 显示 POCDB 为0,这个显示不合理。datasize:62G ,磁盘上大小为12K (这个说明数据并没有写入到磁盘)。
PRIMARY:[db]POCDB> show dbsPOCDBPOCDB 0.000GBadmin 0.000GBconfig 0.001GBlocal 36.804GB[db]POCDB> db.POCCOLL.count();115155968[db]POCDB>db.POCCOLL.stats();{"ns" : "POCDB.POCCOLL","size" : 67368296749,"count" : 115155968,"avgObjSize" : 585,"storageSize" : 12288}
5.2 查看磁盘上文件大小
备注:LAS 文件有28G,但 POCCOLL 磁盘上12K。
[mongo@xiaoxu123 data]$ ls -lh WiredTigerLAS.wtmongo mongo 28G 5月 12 16:35 WiredTigerLAS.wt[mongo@vmt30129 data]$ ls -lh 0--6719021210235564209.wtmongo mongo 12K 5月 12 17:44 0--6719021210235564209.wt
5.3 验证 MajorityReadConcern 能否读取数据
备注:选取最近的数据,使用 readConcern:majority 没有读取到数据。
查看 MajorityReadConcern 是否开启。
db.serverStatus().storageEngine.supportsCommittedReads;true--表示支持.PRIMARY:[db]POCDB> db.POCCOLL.find({"_id" : { "w" : 3, "i" :34238463 }}).readConcern("majority").count();0PRIMARY:[db]POCDB>db.POCCOLL.find({"_id" : { "w" : 3, "i" :34238463 }}).count();1
5.4 查看内存压力情况
备注:此时没有读写,但通过 mongostat 监控发现 dirty 很高且 used 基本上在95%。

5.5 查看 rs.config 里面信息
主要关注lastStableRecoveryTimestamp:1652326222(ISODate(“2022-05-12T03:30:22Z”)),当前时间5月13号9点49分,而 recover 时间点是12号11点30+0800
根据 rs.config 里面相关时间来判断:重启实例需要12号11点30分来恢复数据。根据 checkpoint 时间点来看:数据并没有持久化.但oplog持久化了。
如果此时重启,需要追1天 oplog ,需要从库停了一周,那么需要更久实例恢复,通常来说,重启是一件很常见事。
rs.config 信息
[db]POCDB> rs.status();{"set" : "shard22","date" : ISODate("2022-05-13T01:49:15.297Z"),"heartbeatIntervalMillis" : NumberLong(2000),"majorityVoteCount" : 2,"writeMajorityCount" : 2,"lastStableRecoveryTimestamp" : Timestamp(1652326222, 1),"lastStableCheckpointTimestamp" : Timestamp(1652326222, 1)}
5.6 在不知道的情况下重启服务器
5.6.1 重启实例进入等待模式
备注:启动实例后进入无限等待时间窗口,在默认情况下 PSA 中 S 宕机多久,重启主库就需要不一定等比例时间,取决于多少脏数据以及服务器性能,因为进行 OPLOG 回放是并行,也许就是一个简单维护重启操作造成业务可能停机以天为级别的等待窗口。之前群里面遇到重启需要2天+等待窗口,正常业务肯定无法接受。登陆到数据库直接关闭主实例会报错(因为此时数据只有1个主+1仲裁),此时就应该注意到异常,也可能忽略这个错误,只重启即可。如果知道重启会遇到问题,就不会冒然重启。
[db]admin> db.shutdownServer()2022-05-13T09:56:21.930+0800 E QUERY [js] Error: shutdownServer failed: {"operationTime" : Timestamp(1652406965, 1),"ok" : 0,"errmsg" : "No electable secondaries caught up as of 2022-05-13T09:56:21.907+0800. Please use the replSetStepDown command with the argument {force: true} to force node to step down."
如果使用这种方式进行 shutdown 后启动或者使用 systemctl xx restart 底层实际是 kill 进程。

5.6.2 完成重启实例
备注:重启花30分钟才完成重启。注意如果反复重启,每次都会从相同 recoveryTimestamp 时间点开始,因为重启并不能推进 recoveryTimestamp 时间点,因为开启 enableMajorityReadConcern 。
几个指标:
- 启动总共34分:09:59:59到10:33:48。
- 恢复时间点:WiredTiger recoveryTimestamp. Ts: Timestamp(1652326222, 1)
- ISODate (“2022-05-12T03:30:22Z”),当时时间为13号10点。
- 压测程序:5个小时构造115155968插入记录。
After 18001 seconds, 115155968 new documents inserted - collection has 1151559686397 inserts per second on average0 keyqueries per second on average0 updates per second on average0 rangequeries per second on average
- 恢复时间:并没有需要5小时,因为纯插入,恢复日志每一个 batch 接近5000。我们正常相对复杂点。所以真实业务恢复起来会慢的。Applied 115162250 operations in 23035 batches 。
5.7 此时该如何做?
备注:此时系统重要指标:RPO、RTO 以及最终 SLA 指标。
5.7.1 对应情况如下
需要多久能恢复到最新数据时间点来提供服务(不允许丢失数据)。需要天级别的恢复,这个对应级别就很低了。这个还不是容灾灾难恢复,此时只能等待,运维压力山大。
需要最快恢复系统来提供服务(系统可用性优先) 。重新搞一个新实例就可以或者重启从库。对应丢失数据来换取系统可用性,例如日志类。
5.7.2 后续如何解决这个问题
备注:如无法使用 PSS 代替 PSA 架构,参考前面讲过2点。
disable majorityReadConcern 需要重启实例才生效(5.0之前 PSA 采用此方案,也是官方推荐的方案,另外注意 changestream 以及 readConcern 采用 majority )。
修改从节点的 vote 和 priority 为0,这个只适合临时针对实例宕机或者存在大延迟情况下降低主库的内存压力。否则此时PSA下主库宕机无法选出新主,失去天生高可用特性。
结论:经过前面讲解,我们知道 PSA 在宕机一个数据节点下才存在相关问题,如果 PSA 实例都是正常,我们无需担心这些问题。但实例宕机或者服务器故障不是我们能控制,需要考虑这种情况下,我们需要通过何种方式来解决这些问题。当系统出现问题时,第一种方案不太合适,只能适合下一次。相对第二种可以临时解决问题。
方案1:禁用 majorityReadConcern 参数,来缓解内存压力但无法解决其他问题,需要重启实例下一次才生效。
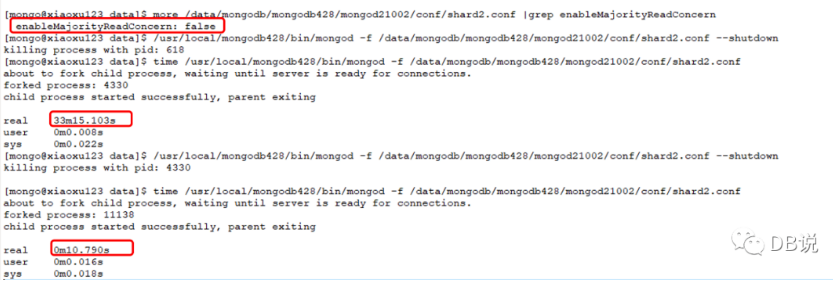
结论:通过禁用 majorityReadConcern 后,第一次重启还是花费30分钟,第二次重启就瞬间完成启动。但无法解决第一次重启长时间等待问题,需要预先规划并修改参数,当遇到问题时直接重启即可。在 PSA 架构出现数据节点宕机避免对主节点内存压力。但存在 majority 的场景还是无法解决,甚至 changestream 、分片集群下部分功能失效,重要系统还建议 PSS 架构。
方案2:临时将异常从库的优先级别与投票都设置为0来恢复。
5.7.3 查看 config 里面信息
几个重要时间:
当时北京时间:9号21点(最新时间)
OPLOG 最后提交时间:7号15点32分
readConcernMajorityOP 时间:7号15点32分
OPLOG应用时间以及持久化时间:9号21点(最新时间)
上一个稳定恢复点时间:7号15点32分
上一个稳定checkpoint时间:7号15点32分
根据 rs.config 里面相关时间来判断:重启实例需要7号15点32分来恢复数据。同时根据 checkpoint 时间点来看:数据并没有持久化。但 oplog 持久化了。此时重启需要从7号开始。
rs.config 信息
PRIMARY:[db]admin> new Date();ISODate("2022-05-09T13:00:31.827Z")[db]admin> new Date(1651908725*1000);ISODate("2022-05-07T07:32:05Z"):PRIMARY:[db]admin> rs.status();{"set" : "shard22","majorityVoteCount" : 2,"writeMajorityCount" : 2,"optimes" : {"lastCommittedOpTime" : {"ts" : Timestamp(1651908725, 3642),"t" : NumberLong(16)},"lastCommittedWallTime" : ISODate("2022-05-07T07:32:05.621Z"),"readConcernMajorityOpTime" : {"ts" : Timestamp(1651908725, 3642),"t" : NumberLong(16)},"readConcernMajorityWallTime" : ISODate("2022-05-07T07:32:05.621Z"),"appliedOpTime" : {"ts" : Timestamp(1652101157, 1),"t" : NumberLong(16)},"durableOpTime" : {"ts" : Timestamp(1652101157, 1),"t" : NumberLong(16)},"lastAppliedWallTime" : ISODate("2022-05-09T12:59:17.625Z"),"lastDurableWallTime" : ISODate("2022-05-09T12:59:17.625Z")},"lastStableRecoveryTimestamp" : Timestamp(1651908725, 3642),"lastStableCheckpointTimestamp" : Timestamp(1651908725, 3642),
修改宕机的节点优先级别与投票都位0方案1。
- 修改从库的优先级与投票。
PRIMARY:[db]POCDB> cfg=rs.config(){"_id" : "shard22","protocolVersion" : NumberLong(1),"writeConcernMajorityJournalDefault" : true,"members" : [{"_id" : 0,"host" : "10.160.100.149:21002","arbiterOnly" : false,"buildIndexes" : true,"hidden" : false,"priority" : 2,"tags" : { },"slaveDelay" : NumberLong(0),"votes" : 1},{"_id" : 1,"host" : "10.160.100.150:21002","arbiterOnly" : false,"buildIndexes" : true,"hidden" : false,"priority" : 1,"tags" :{ },"slaveDelay" : NumberLong(0),"votes" : 1},{"_id" : 2,"host" : "10.160.100.151:21002","arbiterOnly" : true,"buildIndexes" : true,"hidden" : false,"priority" : 0,"tags" : {},"slaveDelay" : NumberLong(0),"votes" : 1}],}PRIMARY:[db]POCDB> cfg.members[1].priority=00PRIMARY:[db]POCDB> cfg.members[1].votes=00PRIMARY:[db]POCDB> rs.reconfig(cfg)
- 查看 MajorityReadConcern 、Recovery 等信息。
PRIMARY:[db]POCDB> rs.status();{"set" : "shard22","date" : ISODate("2022-05-09T13:32:08.214Z"),
- ” majorityVoteCount ” :2, 投票节点还是2;” writeMajorityCount ” :1,writeMajority 从2变1相应的 MajorityReadConcern 也是变1。
"optimes" : {"lastCommittedOpTime" : {"ts" : Timestamp(1652103116, 1),"t" : NumberLong(16)},
” lastCommittedWallTime ” : ISODate(“2022-05-09T13:31:56.255Z”),这个时间也变;
” readConcernMajorityWallTime ” : ISODate(“2022-05-09T13:31:56.255Z”),这个时间也变了” lastStableRecoveryTimestamp ” : Timestamp(1651908725, 3642),恢复点还没有变;” lastStableCheckpointTimestamp ” : Timestamp(1651908725, 3642),checkpoint 点还没有变。
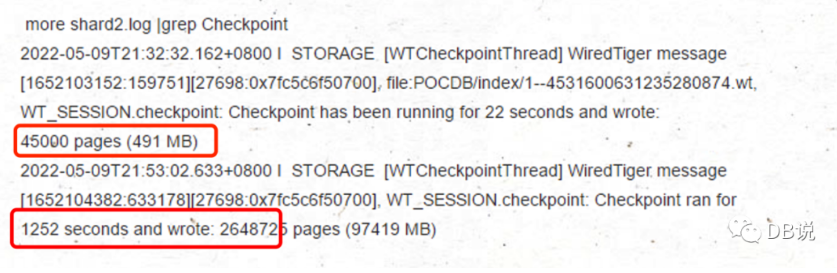
- 经过24分钟刷盘后,checkpoint 终于成功推进。
PRIMARY:[db]admin> rs.status();{"set" : "shard22","date" : ISODate("2022-05-09T13:56:56.426Z"),"majorityVoteCount" : 2,"writeMajorityCount" : 1,"optimes" : {"lastCommittedWallTime" : ISODate("2022-05-09T13:56:49.036Z"),"readConcernMajorityWallTime" : ISODate("2022-05-09T13:56:49.036Z")"lastAppliedWallTime" : ISODate("2022-05-09T13:56:49.036Z"),"lastDurableWallTime" : ISODate("2022-05-09T13:56:49.036Z")},
” lastStableRecoveryTimestamp ” : Timestamp(1652104559, 1),已经改变;
” lastStableCheckpointTimestamp ” : Timestamp(1652104559, 1),已经改变。
- 查看 checkpoint 信息与集合信息
备注:共20分钟刷97G。包括索引与集合2部分,其实刷时间也挺久的,比重启快10分钟,相对来说比重启影响小很多。
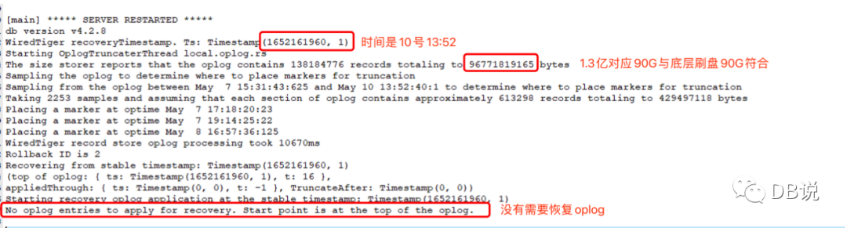
- 重启实例
结论:重启很快并没有把从从实例宕机后所有 OPLOG 都应用一遍,提示 No oplog entries to apply 。
总结:至此完成分析 PSA 架构存在问题以及对应方案,不管怎么应对,当单个数据节点宕机或者长延迟时,在一定程度上牺牲高可用性。在知道 PSA 架构优缺点后,需要在数据一致性与可用性做折中考虑,从5.0开始默认writeConcern从w:1变成 majority 。说明 MongoDB 在设计上更加关注数据一致性,这个改变实际从4.4版本就埋下种子,4.4版本开始 oplog 从默认拉取变成推送模式,在一定程度改善延迟问题。所以说在条件允许下,尽量采用 PSS 架构。但 5.0 PSA 默认 WriteConcern 变成 w:1。有个计算公式:
if [ (#arbiters > 0) AND (#non-arbiters <= majority(#voting-nodes)) ]defaultWriteConcern = { w: 1 }elsedefaultWriteConcern = { w: "majority" }
5.0分片集群采用 PSA 出现S宕机时,客户端写入 hang ,并没有按官方文档描述那样 PSA 默认写是 w:1。当初只是验证 PSA 副本集发现与官方描述一致,但并没有验证分片架构,导致存在偏差。

六. 分析与验证过程
6.1 验证 PSA 副本集模式
6.1.1 PSA副本集默认写关注
shard2:PRIMARY> db.adminCommand({getDefaultRWConcern:1}){"defaultReadConcern" : {"level" : "local"},"defaultWriteConcernSource" : "implicit","defaultReadConcernSource" : "implicit","localUpdateWallClockTime" : ISODate("2022-05-17T06:03:42.239Z"),},
6.1.2 验证50 PSA 版本默认 writeConcern
备注:关闭一个数据节点后写入是否正常。
shard2:PRIMARY> cfg.members[0].stateStrPRIMARYshard2:PRIMARY> cfg.members[1].stateStr(not reachable/healthy)shard2:PRIMARY> cfg.members[2].stateStrARBITERshard2:PRIMARY> use testswitched to db test
没有指定 writeConcern 成功写入。
shard2:PRIMARY> db.testDefaultWriteConcern.insert({w:1})WriteResult({ "nInserted" : 1 })
指定写入失败,说明默认 majority 而是官方说 w:1。
shard2:PRIMARY>db.testDefaultWriteConcern.insert({w:1},{writeConcern:{w:"majority",wtimeout:1000}})WriteResult({"nInserted" : 1,"writeConcernError" : {"code" : 64,"codeName" : "WriteConcernFailed","errmsg" : "waiting for replication timed out","errInfo" : {"wtimeout" : true,"writeConcern" : {"w" : "majority","wtimeout" : 1000,"provenance" : "clientSupplied"}}}})
6.1.3分片使用单个PSA shard来验证来验证默认写关注级别
查看集群信息。
mongos> sh.status()--- Sharding Status ---shards:{ "_id" : "shard2","host" : "shard2/10.230.10.150:21017,10.230.9.150:21017", "state" : 1,"topologyTime" : Timestamp(1652772600, 4) }active mongoses:"5.0.2" : 1autosplit:Currently enabled: yesdatabases:{ "_id" : "config", "primary" : "config", "partitioned" : true }2、创建分片集合mongos> sh.enableSharding("xiaoxu"){"ok" : 1,}mongos> sh.shardCollection("xiaoxu.testDefaultWriteConcern",{_id:"hashed"}){"collectionsharded" : "xiaoxu.testDefaultWriteConcern","ok" : 1,}
6.1.4 正常情况插入测试数据。
备注:不管采用默认 writeConcern 还是采用 w:1 或者 w:”majority” 模式都没有问题。
mongos> use xiaoxuswitched to db xiaoxumongos> db.testDefaultWriteConcern.insert({_id:1,name:"xiaoxu"})WriteResult({ "nInserted" : 1 })mongos>db.testDefaultWriteConcern.insert({_id:2,name:"xiaoxu"},{writeConcern:{w:"majority",wtimeout:1000}})WriteResult({ "nInserted" : 1 })mongos>db.testDefaultWriteConcern.insert({_id:3,name:"xiaoxu"},{writeConcern:{w:1}})WriteResult({ "nInserted" : 1 })
6.1.5 模拟PSA副本中S宕机的场景来插入数据
备注:手动关闭从实例。
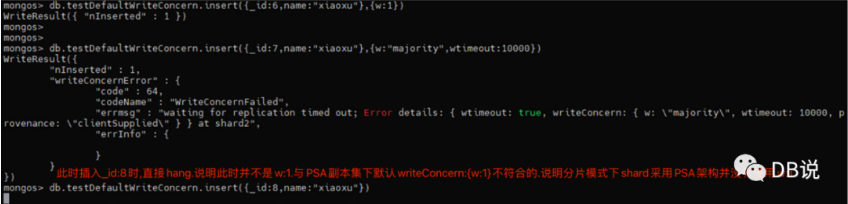
shard2:PRIMARY> cfg.members[0].stateStrPRIMARYshard2:PRIMARY> cfg.members[1].stateStr(not reachable/healthy)shard2:PRIMARY> cfg.members[2].stateStrARBITERmongos> db.testDefaultWriteConcern.insert({_id:6,name:"xiaoxu"},{w:1})WriteResult({ "nInserted" : 1 })mongos>mongos>mongos>db.testDefaultWriteConcern.insert({_id:7,name:"xiaoxu"},{w:"majority",wtimeout:10000})WriteResult({"nInserted" : 1,"writeConcernError" : {"code" : 64,"codeName" : "WriteConcernFailed","errmsg" : "waiting for replication timed out; Error details: { wtimeout: true, writeConcern: { w: \"majority\", wtimeout: 10000, provenance: \"clientSupplied\" } } at shard2","errInfo" : {}}})
异常:此时没有指定 writeConcern ,采用默认的行为.此时写入 hang 住。
mongos> db.testDefaultWriteConcern.insert({_id:8,name:"xiaoxu"})
6.1.6 分片下写入数据默认的 writeConcern 来源哪里?
备注:查询发现 defaultWriteConcern 是 w:majority 。这个信息是来自于 config 。而不是 shard 层面,目前 config 是单节点的副本集。尝试改成 PSA 架构试试?
mongos> db.adminCommand({getDefaultRWConcern:1}){"defaultReadConcern" : {"level" : "local"},"defaultWriteConcern" : {"w" : "majority","wtimeout" : 0},"defaultWriteConcernSource" : "implicit","defaultReadConcernSource" : "implicit",}
6.1.7 尝试把 config 副本集改成 PSA 架构
备注:config 副本集中禁止加入仲裁节点,那么 config 默认是 writeConcern 就是 {w:majority} 。
config:PRIMARY> rs.reconfigForPSASet(2, cfg);Running first reconfig to give member at index 2 { votes: 1, priority: 0 }{"ok" : 0,"errmsg" : "Arbiters are not allowed in replica set configurations being used for config servers","code" : 103,"codeName" : "NewReplicaSetConfigurationIncompatible","$gleStats" : {"lastOpTime" : {"ts" : Timestamp(1652693376, 3),"t" : NumberLong(1)}
6.1.8 针对分片集群下 DefaultRWConcern 相关说明
解释:
连接到 mongos 时没有显式指定 writeConcern 时,mongos 使用全局默认设置,这个全局设置来自 config 副本集,而不是底层分片,所有底层分片 PSA 下架构默认 writeConcern:{w:1} 直接被 config 副本集全局设置覆盖。因为 config 不支持仲裁,所以默认是 writeConcern:{w:”majority”} 。

6.1.9 5.0 PSA 出现 S 宕机时,为了避免上一篇文章提到问题外。还包括如下:
如果客户端没有指定 writeConcern 采用默认行为会导致写入 hang 的情况应对措施:
采用方案2。注意是临时的,等从库恢复及时重置回去,否则当主库宕机,没有办法选出新主,从而影响系统可用性,此时从宕机或者机器挂了,需要及时监控并修改配置,否则可能会影响应用使用。

修改 config 默认 writeConcern 为 w:1 虽然能解决写入 hang 问题,但无法解决底层分片内存压力以及性能下降问题等问题。
6.1.10 修改分片中宕机的实例节点信息来验证写入
shard2:PRIMARY> cfg.members[1].priority=00shard2:PRIMARY> cfg.members[1].votes=00shard2:PRIMARY> rs.reconfig(cfg)
6.1.11 再次验证 mongos 插入数据
备注:经过修改后,不管是否指定 writeConcern 还是指定 majority 都可以。
注意应:用此时指定 w:2 就有问题。
mongos> db.testDefaultWriteConcern.insert({_id:9})WriteResult({ "nInserted" : 1 })mongos>db.testDefaultWriteConcern.insert({_id:10},{writeConcern:{w:"majority",wtimeout:1000}})WriteResult({ "nInserted" : 1 })
总结:至此完成分析 PSA 架构包括集群下使用 PSA 分片存在问题以及对应方案不管怎么应对都需要注意潜在的影响。例如当单个数据节点宕机或者长延迟时可,以通过程序定时检测节点状态出,现异常时临时将优先级别与投票设置0来避免5.0分片集群下默认多节点写入导致 hang 或者客户端指定多节点写入 hang 问题由,此带来一致性问题与高可用性问题需要关注的。
关于作者:徐靖



评论前必须登录!
注册