 MongoDB中文社区
MongoDB中文社区
一.业务背景
QQ 小世界最主要的四个 Feed 场景有:基于推荐流的广场页、个人主页,被动消息列表以及基于关注流的关注页。
最新 Feed 云架构由腾讯老 Feeds 云重构而来,老 Feeds 云存在如下问题:
- 性能问题
老系统读写性能差,通过调研测试确认 MongoDB 读写性能好,同时支持更多查询功能。老系统无法像 MongoDB 一样支持字段过滤( Feed 权限过滤等),字段排序(个人主页赞排序等),事务等。
- 数据一致性问题
老系统采用了 ckv+tssd 为 tlist 做一层缓存,系统依赖多款存储服务,容易形成数据不一致的问题。
- 同步组件维护性问题
老系统采用同步中心组件作为服务间的连接桥梁,同步中心组件缺失运维维护,因此采用kafka作为中间件作为异步处理。
- 存储组件维护成本高
老系统 Feeds 底层 tlist 、 tssd 扩容、监控信息等服务能力相对不足。
- 服务冗余问题
老系统设计不合理,评论、回复、赞、转等互动服务冗杂在 Feeds 服务中,缺乏功能拆分,存在服务过滤逻辑冗杂,协议设计不规范等问题。
MongoDB 的优势
除了读写性能,通过调研及测试确认 MongoDB 拥有高性能、低时延、分布式、高压缩比、天然高可用、多种读写分离访问策略、快速 DDL 操作等优势,可以方便 QQ 系统业务快速迭代开发。
新的 Feed 云架构,也就是 UFO(UGC Feed all in One)系统,通过一些列的业务侧架构优化,存储服务迁移 MongoDB 后,最终获得了极大收益,主要收益如下:
- 维护成本降低
- 业务性能提升
- 用户体验更好
- 存储成本更少
- 业务迭代开发效率提升
- Feed 命中率显著提升,几乎100%
二.小世界 Feed 云系统面临的问题
通过 Feed 云系统改造,研发全新的 UFO 系统替换掉之前老的 Feed 云系统,实现了小世界的性能提升、三地多活容灾;同时针对小世界特性,对新 Feed 云系统做了削峰策略优化,极大的提升了用户体验。
2.1. 老 Feed 系统主要问题
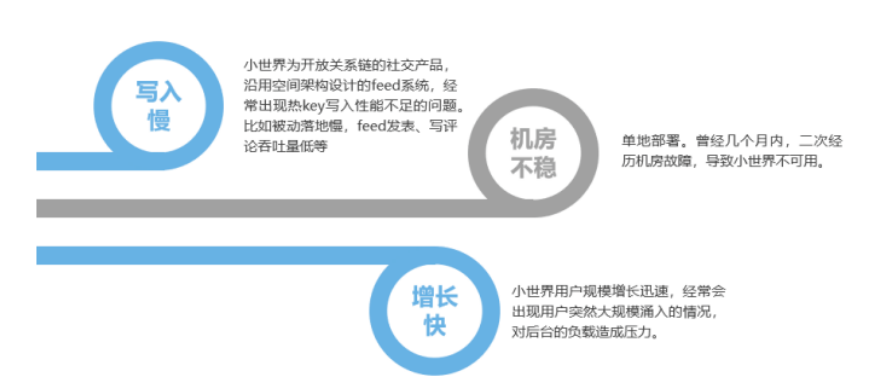
改造优化前面临的问题主要有三个方面:
- 写性能差
QQ 小世界为开放关系链的社交,时有出现热 Key 写入性能不足的问题。比如被动落地慢,Feed 发表、写评论吞吐量低等。
- 机房不稳定
之前小世界所有服务都是单地域部署,机房出现问题就会引起整个服务不可用,单点问题比较突出。
- 业务增长快,系统负载高
小世界业务目前 DAU 涨的很快,有时候做会出现新用户蜂拥进入小世界的情况,对后台的负载造成压力。
2.2. 新场景下 Feed 云问题
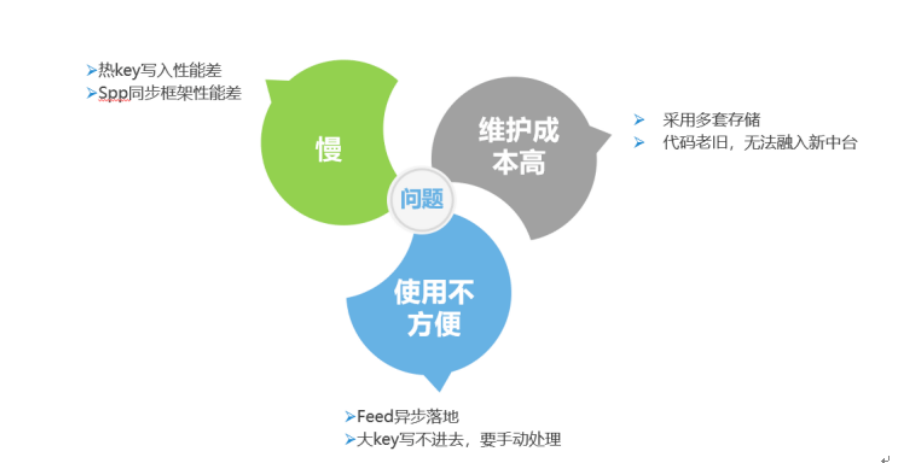
Feed 云是从 QQ 空间系统里抽出来的一套通用 Feed 系统,支持 Feed 发表,评论,回复,点赞等基础的 UGC 操作。同时支持关系链、时间序拉取 Feed ,按 ID 拉取 Feed 等,小世界就是基于这套 Feed 云系统搭起来的。
但在小世界场景下,Feed 云还是有很多问题。我们分析 Feed 云主要存在三个问题。首先是之前提到的慢的问题,主要体现在热 Key 写入性能差,SSP 同步框架性能差。其次一个问题是维护成本高,因为他采用了多套存储,同时代码比较老旧,很难融入新的中台。另外还有使用不方便问题,主要体现在一个是 Feed 异步落地,也就是我发表一个 Feed,跟上层返回已经发表成功,但实际上还可能没有在 Feed 系统最终落地。在一个是大 Key 有时候写不进去,需要手动处理。
三.数据库存储选型
下面就是对存储进行选型,首先我们要细化对存储的要求,按照我们的目标 DAU,候选存储需要满足以下要求:
- 高并发读写
- 方便快捷的 DDL 操作
- 分布式、支持实时快捷扩缩容
- 读写分离支持
- 海量表数据,新增字段业务无感知
目前腾讯内部大致符合我们需求的存储主要是 MongoDB 和 Redis,因此那我就对两者做了对比,下表里面列了一些详细的情况。4C8G低规格 MongoDB 实例性能数据对比结果如下:
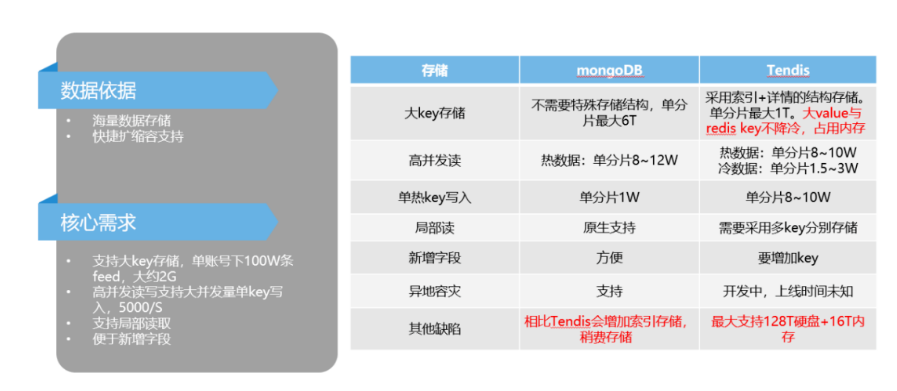
包括大 Key 的支持,高并发读的性能,单热 Key 写入性能,局部读能力等等。发现在大 Key 支持方面,Tendis 不能满足我们业务需求,,主要是大 Value 和 Redis 的 Key 是不降冷的,永久占用内存。
所以最终我们选择了 MongoDB 作为最终存储。
四.MongoDB 业务用法及内核性能优化
4.1. MongoDB 表设计
4.1.1. Feed 表及索引设计
- InnerFeed 表
InnerFeed 为整个主动被动Feed结构,主要设计Feed核心信息,设计 Feed 主人、唯一ID、Feed 权限:
message InnerFeed{string feedID = 1; //id,存储层使用,唯一标识一条feedstring feedOwner = 2; //Feeds主人trpc.feedcloud.ufobase.SingleFeed feedData = 3; //feed详情数据uint32 feedMask = 4; //信息中心内部使用的//feed 权限flag标志,参考 ENUM_UGCFLAGtrpc.feedcloud.ufougcright.ENUM_UGCFLAG feedRightFlag = 5;};
- SingleFeed 表
SingleFeed 为 Feed 基本信息,Feed 类型,主动、评论被动、回复被动、Feed 生成时间以及 Feed 详情:
message SingleFeed {int32 feedType = 4; //Feed类型,主动、评论被动、回复被动。。。uint32 feedTime = 5;FeedsSummary summary = 7; //FeedsSummarymap<string, string> ext = 14; //拓展信息...};
- FeedsSummary 表
FeedsSummary 为 Feed 详情,其中 UgcData 为原贴主贴数据,UgcData.content 负责存储业务自定义的二进制数据,OpratorInfo 为 Feed 操作详情,携带对应操作的操作人、时间、修改数据等信息:
//FeedsSummarymessage FeedsSummary{UgcData ugcData = 1; //内容详情OpratorInfo opInfo = 2; //操作信息};// UgcData 详情message UgcData{string userID = 1 [(validate.rules).string.tsecstr = true]uint32 cTime = 2;bytes content = 5; //透传数据,二进制buffer...};message OpratorInfo{uint32 action = 1; //操作类型,如评论、回复等,见FC_API_ACTION//操作人uinstring userID = 2 [(validate.rules).string.tsecstr = true];uint32 cTime = 3; //操作时间//如果是评论或者回复,当前评论或者回复详情放这里,其它回复内容是全部。T2Body t2body = 4;uint32 modifyFlag = 11; //ENUM_FEEDS_MODIFY_DEFINE...};
- Feed索引设计
Feed 主要涉及个人主页 Feed 拉取、关注页个人 Feed 聚合:
"key" : {"feedOwner" : -1,"feedData.feedKey" : -1}根据 FeedID 拉取指定的 Feed 详情:
"key" : {"feedOwner" : -1,"feedData.feedTime" : -1}4.1.2. 评论回复表及所有设计
- InnerT2Body 表
InnerT2Body 为整个评论结构,回复作为内嵌数组内嵌评论中,结构如下:
message InnerT2Body{string feedID = 1;//如果是评论或者回复,当前评论或者回复详情放这里,其它回复内容是全部。trpc.feedcloud.ufobase.T2Body t2body = 2;};
- T2Body 表
T2Body 为评论信息,涉及评论 ID、时间、内容等基本信息:
message T2Body //comment(评论){string userID = 1; //评论uinuint32 cTime = 2; //评论时间string ID = 3; //ugc中的seq//评论内容,二进制结构,可包含文字、图片等,业务自定义string content = 5;uint32 respNum = 6; //回复数repeated T3Body vt3Body = 7; //回复列表...};
- T3Body 表
T3Body 为回复信息,涉及回复 ID、时间、内容、被回复人的 ID 等基本信息:
message T3Body //reply(回复){string userID = 1; //回复人uint32 cTime = 2; //回复时间int32 modifyFlag = 3; //见COMM_REPLY_MODIFYFLAGstring ID = 4; //ugc中的seqstring targetUID = 5; //被回复人//回复内容,二进制结构,可包含文字、图片等,业务自定义string content = 6;};
- 评论索引设计
(1)评论主要涉及评论时间序排序:”key” : {“feedID” : -1,”t2body.cTime” : -1}
(2)根据评论 ID 拉取指定的评论详情:”key” : {“feedID” : -1,”t2body.ID” : -1}
4.2. 片建选择及分片方式
以 Feed 表为例,QQ 小世界主要查询都带有 feedowner ,并且该字段唯一,因此选择码 ID 作为片建,这样可以最大化提升查询性能,索引查询都可以通过同一个分片获取数据。此外,为了避免分片间数据不均衡引起的 moveChunk 操作,因此选择 hashed 分片方式,同时提前进行预分片,MongoDB 默认支持 hashed 预分片,预分片方式如下:
use feedsh.enableSharding("feed")//n为实际分片数sh.shardCollection("feed.feed", {"feedowner": "hashed"}, false,{numInitialChunks:8192*n})
4.3. 低峰期滑动窗口设置
当分片间 chunks 数据不均衡的情况下,会触发自动 balance 均衡,对于低规格实例,balance 过程存在如下问题:
- CPU 消耗过高,迁移过程甚至消耗90%左右 CPU
- 业务访问抖动,耗时增加
- 慢日志增加
- 异常告警增多
以上问题都是由于 balance 过程进行 moveChunk 数据搬迁过程引起,为了快速实现数据从一个分片迁移到另一个分片,MongoDB 内部会不停的把数据从一个分片挪动到另一个分片,这时候就会消耗大量 CPU,从而引起业务抖动。
MongoDB 内核也考虑到了 balance 过程对业务有一定影响,因此默认支持了 balance 窗口设置,这样就可以把 balance 过程和业务高峰期进行错峰,这样来最大化规避数据迁移引起的业务抖动。例如设置凌晨0-6点低峰期进行balance窗口设置,对应命令如下:
use configdb.settings.update({"_id":"balancer"},{"$set":{"activeWindow":{"start":"00:00","stop":"06:00"}}},true)
4.4. MongoDB 内核优化
4.4.1内核认证随机数生成优化
MongoDB 在认证过程中会读取 /dev/urandom 用来生成随机字符串来返回给客户端,目的是为了保证每次认证都有个不同的 Auth 变量,以防止被重放攻击。当同时有大量连接进来时,会导致多个线程同时读取该文件,而出于安全性考虑,避免多并发读返回相同的字符串(虽然概率极小),在该文件上加一把 spinlock 锁(很早期的时候并没有这把锁,所以也没有性能问题),导致 CPU 大部分消耗在 spinlock ,这导致在多并发情况下随机数的读取性能较差,而设计者的初衷也不是为了速度。
腾讯 MongoDB 内核随机数优化方法:新版本内核已做相关优化:mongos 启动的时候读 /dev/urandom 获取随机字符串作为种子,传给伪随机数算法,后续的随机字符串由算法实现,不去内核态获取。
优化前后测试对比验证方法:通过 Python 脚本模拟不断建链断链场景,1000个子进程并发写入,连接池参数设置 socketTimeoutMS=100,maxPoolSize=100 ,其中 socketTimeoutMS 超时时间设置较短,模拟超时后不断重试直到成功写入数据的场景(最多100次)。测试主要代码如下:
def insert(num,retry):print("insert:",num)if retry <= 0:print("unable to write to database")returndb_client = pymongo.MongoClient(MONGO_URI,maxPoolSize=100,socketTimeoutMS=100)db = db_client['test']posts = db['tb3']try:saveData = []for i in range(0, num):saveData.append({'task_id':i,})posts.insert({'task_id':i})except Exception as e:retry -= 1insert(num,retry)print("Exception:",e)def main(process_num,num,retry):pool = multiprocessing.Pool(processes=process_num)for i in xrange(num):pool.apply_async(insert, (100,retry, ))pool.close()pool.join()print "Sub-processes done."if __name__ == "__main__":main(1000,1000,100)
优化结果如下:
优化前:CPU 峰值消耗60核左右,重试次数 1710,而且整体测试耗时要更长,差不多增加2 倍。优化后:CPU 峰值: 7核 左右,重试次数 1272,整体性能更好。
mongos 连接池优化:
通过调整 MinSize 和 MaxSize ,将连接数固定,避免非必要的连接过期断开重建,防止请求波动期间造成大量连接的新建和断开,能够很好的缓解毛刺。优化方法如下:
ShardingTaskExecutorPoolMaxSize: 70ShardingTaskExecutorPoolMinSize: 35
如下图所示,17:30调整的,慢查询少了 2 个数量级:

4.5. MongoDB 集群监控信息统计
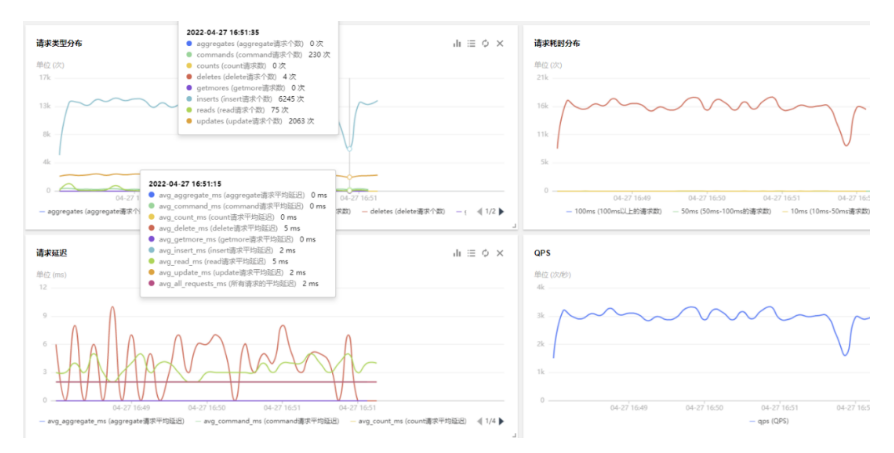
如下图所示,整个 QQ 小世界数据库存储迁移 MongoDB 后,平均响应时延控制在5ms以内,整体性能良好。



评论前必须登录!
注册