本文主要分享腾讯智慧零售团队优码业务在MongoDB中的应用,采用腾讯云MongoDB作为主存储服务给业务带来了较大收益,主要包括:高性能、快捷的DDL操作、低存储成本、超大存储容量等收益,极大的降低了业务存储成本,并提高了业务迭代开发效率。
腾讯优码从连接消费者到连接渠道终端,实现以货的数字化为基础的企业数字化升级,包含营销能力升级和动销能力升级。腾讯优码由正品通、门店通和会员通三个子产品组成。
腾讯优码整体视图
1.1 正品通
腾讯优码正品通提供防伪鉴真能力,实现一物一码全流程正品追溯,全链路数据存储至区块链,确保真实可信;更可直达品牌私域,实现流量进一步转化;同时正品通提供微信域内的品牌保护能力,阻断品牌伪冒网站传播、帮助消费者识别假冒商品。
1.2 门店通
腾讯优码门店通是服务品牌方、经销商、业代员以及终端门店四大零售链路核心角色实现基于终端销售门店的销售管理手段升级与销售额提升。
1.3 会员通
腾讯优码会员通是面向零售品牌商提供的SaaS+定制化服务的产品,以扫码为切入点,连接线上线下场景。提供丰富的扫码/互动活动模型、活动评估体系助力品牌连接消费者。
腾讯智慧零售优码业务存储零售商品二维码信息,该信息为智慧零售最核心的数据信息,提供“从连接消费者到连接渠道终端,实现以货的数字化为基础的企业数字化升级”相关服务。因此码数据存储问题是项目最核心的问题。
2.1 需求和方案
要解决码存储问题,首先需要分析码存储的特征。经过分析码存储问题的主要特征是:
- 海量数据:腾讯优码做的商品二维码,随着越来越多的商品使用腾讯优码业务,二维码数据开始呈现指数级增长。
- 关联存储:码与码之间存在1:1和1:N:N的关联关系,需要存储这种关系,并且提供相应的关联查询。
- 多维度查询:针对不同的应用场景需要提供不同维度的条件查询。
在获取到码存储特征之后,经过多方调研和排查之后,初步选取了2种存储方案:
1. MySQL + ES:MySQL 分库分表存储码元数据,提供需要高性能的读写场景;然后根据需求将部分数据同步 ES 以应对各种复杂的查询场景。
2. MongoDB:MongoDB 是全球排名最高的分布式NoSQL数据库,其核心特性是 No Schema、高可用和分布式,非常适合分布式存储。
MySQL + ES 是一个比较常见的存储解决方案,并且在很多领域内被广泛应用,如会员或商品信息储存领域。此方案的优势是能够提供非常多的查询方式和不同的性能保障,可以应对各种各样复杂的业务查询需求。
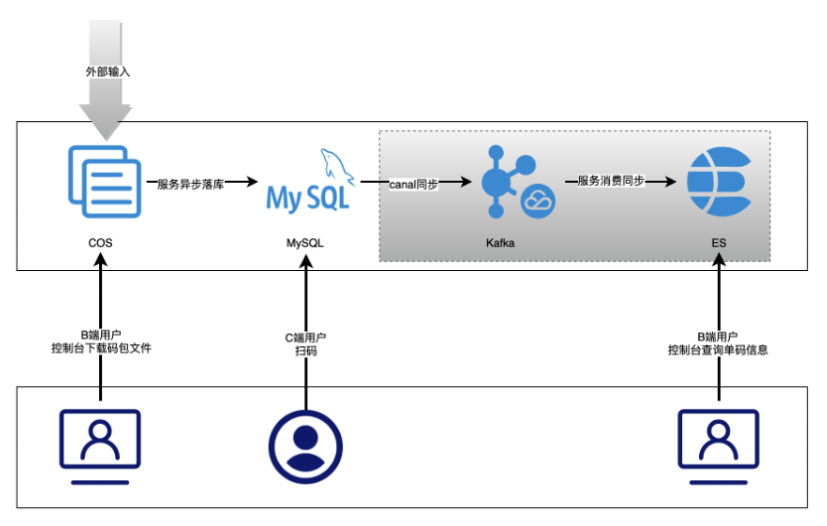
MySQL + ES 的常见架构是写操作直接作用于MySQL,然后通过 canal + Kafka 的方式将数据变更同步到ES,然后再根据不同的查询场景从MySQL或者ES查询数据。下图是在腾讯优码业务场景下可能的架构图:
- 数据同步和一致性问题:这个问题在数据量不大的情况下不会有影响。但是如果数据量百亿甚至千亿时就是一个非常严重的问题。
- 数据容量问题:一般情况下 MySql 的单表数据最好维持在百万级一下,如果单表数据量过大之后读写都是个问题。那么如果要存储千亿数据就要几千上万张表,如此多的分表需要业务自己维护时开发运维都是几乎不可行的。
- 成本问题:数据冗余存储,会增加额外的存储成本。同时ES 为了保证数据可靠性和查询性能,需要更多的机器和内存。而且 ES 存在数据膨胀问题,对于同样的数据,需要相当MySql来说更大的磁盘。
- DDL运维问题:MySql 在分库分布之后,因为DDL语句需要操作大量的库表,因此非常耗时,同时也容易出错。根据我们以前的项目经验来说,当有几百张表,单表几十万数据时,一个简单的增加字段的DDL语句也需要1小时甚至更久才能完成。
- 开发成本问题:此方案需要业务自己维护分库分表、数据同步和根据需求选取不同的查询引擎。不仅整个架构复杂,同时在做业务需求时需要慎重考虑,稍不注意使用错的存储引擎就可能导致性能问题。
- 水平扩容问题:MySql 分库分表要扩容需要业务手动 rehash 搬迁数据,成本非常高,而且很难处理扩容过程中的数据读写问题。
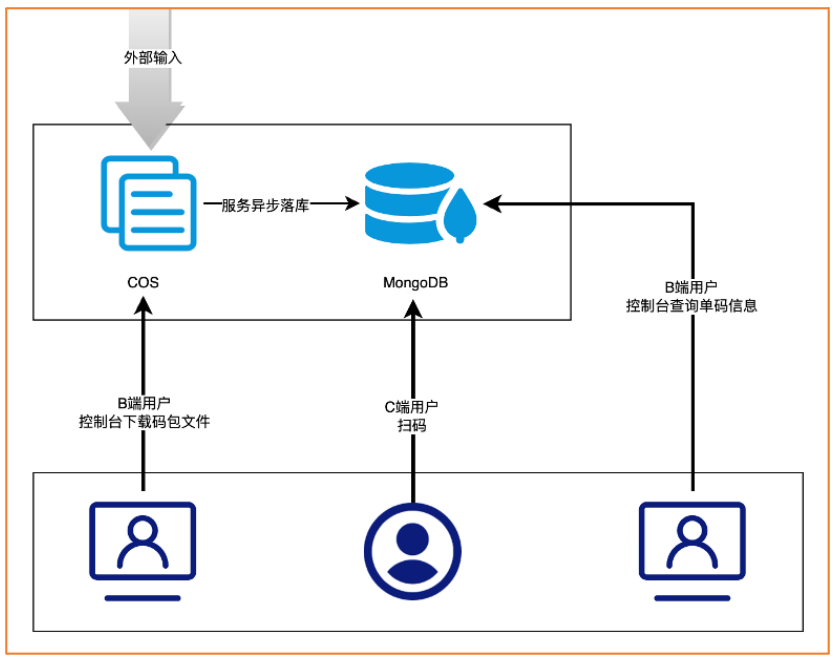
MongoDB 是非常出名的分布式存储引擎,具备 No Schema、高可用、分布式、数据压缩等多方面的优势。虽然MongoDB 是NoSQL 存储引擎,但是其 Wired Tiger 存储引擎和innerdb 一样底层使用的是B+树,因此MongoDB 在提供分布式存储的前提下同时能够提供大部分MySql 支持的查询方式。因此,在使用 MongoDB 时,我们不需要MySql冗余表或者 ES 来支持大部分的分布式查询。在腾讯优码的应用场景下,基于MongoDB 的存储架构如下图所示:
从图中可以看出,MongoDB可以避免冗余存储带来的数据同步和一致性问题、存储成本问题、资源/运维/开发成本。而且在进一步测试和分析MongoDB的功能和性能之后,我们发现MongoDB还具备如下优势:
- 无DDL问题:因为MongoDB 是No Schema 的,因此可以避免MySql的DDL问题。
- 数据自动均匀:MongoDB 有自动rebalance 功能,可以在数据分布不均匀的时候,自动搬迁数据,保证各个分片间的负载均匀。
- 更低的成本:MongoDB 自带数据压缩,在同等数据下,MongoDB 需求的磁盘更少。
- 更高的性能:MongoDB 最大化的利用了内存,在大部分场景下拥有接近内存数据库的性能。经过测试MongoDB的单分片读性能约为3万QPS。
- 更多的读写方式:虽然MongoDB没有ES的倒排索引,其支持的查询方式略逊于ES。但是,MongoDB在拥有大部分ES的查询能力的同时,其性能远高与ES;而且相对MySql 来说MongoDB 的字段类型支持内嵌对象和数组对象,因此能满足跟多的读写需求。
2.3 方案对比
通过前面的分析,我们初步判断MongoDB拥有更好的表现。因此为了进一步确定MongoDB的优势,我们深入对比了MySQL + ES 与MongoDB在各方面的表现。
2.3.1 存储成本对比
MongoDB 在存储上的优势主要体现在两个方面:数据压缩和无冗余存储。
为了更加直观的看出磁盘使用情况,我们模拟了在腾讯优码业务场景下,MySQL + ES和MongoDB下的实际存储情况。
一方面,在MySQL+ES的方案下,为了满足需要我们需要将冗余一份ES数据和MySQL的冗余表。其中码的核心数据存储在MySQL中,其磁盘总量仅占总的38.1%。前面说过 MongoDB的方案是不需要冗余存储的,因此使用MongoDB可以减少这61.9%的总数据容量。
另一方面,经过测试同样的码数据,MongoDB snappy压缩算法的压缩率约3倍,zlib 压缩算法的压缩率约6倍。因此,虽然业务为了保证系统的稳定性而选择 snappy 压缩算法,但MongoDB 仍然只需要 MySQL 三分之一的磁盘消耗。
- 无数据同步链路:使用MongoDB不需要数据同步,因此就不需要维护canal服务和kafka队列,大大减少开发和运维难度。
- 人力成本收益:在MySQL+ES架构下每次对MySQL集群做添加字段变更,都需运维 一定的人日投入,并且存在业务抖动风险,同时影响业务迭代发布进度,迭代发布耗时且风险大。
- 开发维护成本:MongoDB存储架构简单,一份存储,无数据一致性压力。
- 动态扩容:MongoDB 支持随时动态扩容,基本不存在容量上限问题,而MySQL在扩容时需要业务手动rehash变迁数据,并自己保证数据一致性和完整性。
2.3.3 性能对比
经过压测,同样的4C8G的机器配置下,MySQL和MongoDB在大数据量下写性能基本一致。MySQL的读性单分片约6000QPS左右,ES的性能只有800QPS左右。而 MongoDB 单分片地读性能在3万QPS左右,远高于MySQL和 ES 的性能。
经过上面的分析和对比之后,可以明显看出 MongoDB 在各方面都有优势。为了更加直观的看出不同方案的差异,这里列出了从功能、性能、成本、可扩展性和可维护性等5个方面的对比数据:
综上所述,MongoDB 不仅能完全满足业务需求,同时在性能、成本、可维护性等各方面都优于其它两种方案,因此腾讯优码最终选用的是MongoDB 作为业务核心数据码的存储方案。
零售优码业务对成本要求较高、数据量较大,线上真实读写流量不是太高(读3W QPS要求),因此采用低规格4C8G规格(单节点规格)分片模式集群部署。
3.1 分片集群片建选择+预分片
零售优码数据查询都是通过码id查询,因此选择码id作为片建,这样可以最大化查询性能,索引查询都可以通过同一个分片获取数据。此外,为了避免分片间数据不均衡引起的moveChunk操作,因此选择hashed分片方式,同时提前进行预分片,MongoDB默认支持hashed预分片,以优码详情表为例,预分片方式如下:
use db_code_xx
sh.enableSharding("db_code_xx")
sh.shardCollection("db_code_xx.t_code_xx", {"id": "hashed"}, false,{numInitialChunks:8192*n})
3.2 低峰期滑动窗口设置
由于MongoDB实例节点规格低(4C8G),当分片间chunks数据不均衡的情况下,会触发自动balance均衡,由于实例规格低,balance过程存在如下问题:
- CPU消耗过高,迁移过程甚至消耗90%左右CPU
- 业务访问抖动,耗时增加
- 慢日志增加
- 异常告警增多
以上问题都是由于balance过程进行moveChunk数据搬迁过程引起,为了快速实现数据从一个分片迁移到另一个分片,MongoDB内部会不停的把数据从一个分片挪动到另一个分片,这时候就会消耗大量CPU,从而引起业务抖动。
MongoDB内核也考虑到了balance过程对业务有一定影响,因此默认支持了balance窗口设置,这样就可以把balance过程和业务高峰期进行错峰,这样来最大化规避数据迁移引起的业务抖动。例如设置凌晨0-6点低峰期进行balance窗口设置,对应命令如下:
use config
db.settings.update({"_id":"balancer"},{"$set":{"activeWindow":{"start":"00:00","stop":"06:00"}}},true)
3.3 写多数派优化
由于优码二维码数据非常核心,为了避免极端情况下的数据丢失和数据回归等风险,因此客户端采用writeConcern={w: “majority”}配置,确保数据写入到副本集大多数成员后才向客户端发送确认。
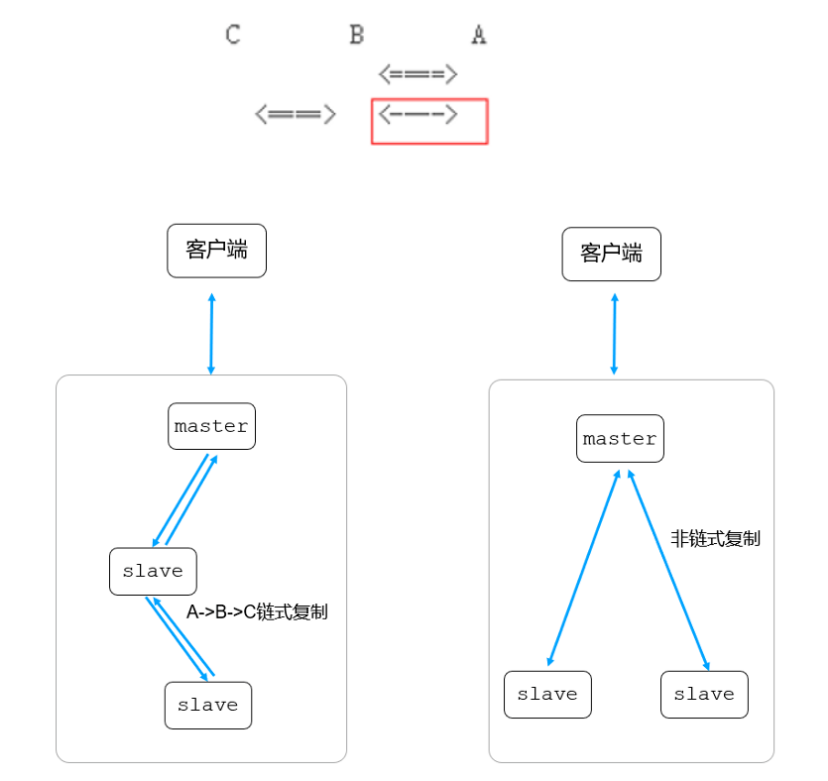
链式复制的概念:假设节点A(primary)、B节点(secondary)、C节点(secondary),如果B节点从A节点同步数据,C节点从B节点同步数据,这样A->B->C之间就形成了一个链式的同步结构,如下图所示:
MongoDB多节点副本集可以支持链式复制,可以通过如下命令获取当前副本集是否支持链式复制:
cmgo-xx:SECONDARY> rs.conf().settings.chainingAllowed
true
cmgo-xx:SECONDARY>
此外,可以通过查看副本集中每个节点的同步源来判断当前副本集节点中是否存在有链式复制情况,如果同步源为secondary从节点,则说明副本集中存在链式复制,具体查看如下副本集参数:
cmgo-xx:SECONDARY> rs.status().syncSourceHost
xx.xx.xx.xx:7021
cmgo-xx:SECONDARY>
由于业务配置为写多数派,鉴于性能考虑可以关闭链式复制功能,MongoDB可以通过如下命令操作进行关闭:
cfg = rs.config()
cfg.settings.chainingAllowed = false
rs.reconfig(cfg)
- 链式复制好处:可以大大减轻主节点同步oplog的压力。
- 链式复制不足:当写策略为majority时,写请求的耗时变大。
基于写性能考虑,当业务采用“写大多数”策略时,直接关闭链式复制功能,确保写链路过长引起的写性能下降。
为了让社区组委会成员和志愿者朋友们灵活参与,同时我们为想要深度参与社区建设的伙伴们开设了“招募通道”,如果您想要在社区里面结交志同道合的技术伙伴,想要通过在社区沉淀有价值的干货内容,想要一个展示自己的舞台,提升自身的技术影响力,即刻加入社区贡献队伍~ 点击链接提交申请:
 MongoDB中文社区
MongoDB中文社区









评论前必须登录!
注册