 MongoDB中文社区
MongoDB中文社区
有些问题每个月的那几天都有人问到,开这个系列的初衷就是想把这些问题集中解答一下,以后再被问到就可以让提问者自己阅读了。我会尽量不涉及底层实现,从使用的角度说明怎么理解这些知识点。
今天先聊聊MongoDB的缓存使用。
首先说明这里说的缓存是是指WiredTiger Cache,由参数wiredTiger.engineConfig.cacheSizeGB控制。
使用原则
cacheSizeGB不应该超过默认值
cacheSizeGB默认值是(RAM – 1GB) / 2。这个限制的出发点是防止OOM,因为MongoDB使用的总内存不仅是WT Cache,还包括了一些额外的消耗,例如:
-
执行CRUD需要的必要缓存
-
建立网络连接所需的堆栈空间
-
其他
在极端情况下,这些消耗有可能升高导致OOM,而在cacheSizeGB不超过默认值时通常很难OOM。
说到这里有人该问了,这么大内存我只用一半是不是太浪费了?实话实说,不浪费。剩下的空间会被操作系统用来最优化系统性能。对于数据库系统而言,这些内存大部分会被用于缓冲数据文件的内容(FS Cache)。而数据文件本质上也就是我们的数据,所以本质上这些内存还是被用于缓存数据了,只是以一种不同的形式。
那么这两部分缓存有什么不同呢?不同点就在于WT Cache里的内容是可以直接使用的,而FS Cache里的内容还需要一系列转换才能转移到WT Cache(比如解压,解密),然后才能被使用。但是毕竟这里是内存,所以数据如果来自FS Cache也会远远快于来自磁盘,或者从速度上讲:WT Cache > FS Cache > 磁盘。
为了更直观地表达整个过程中发生的情况,请参考下图:
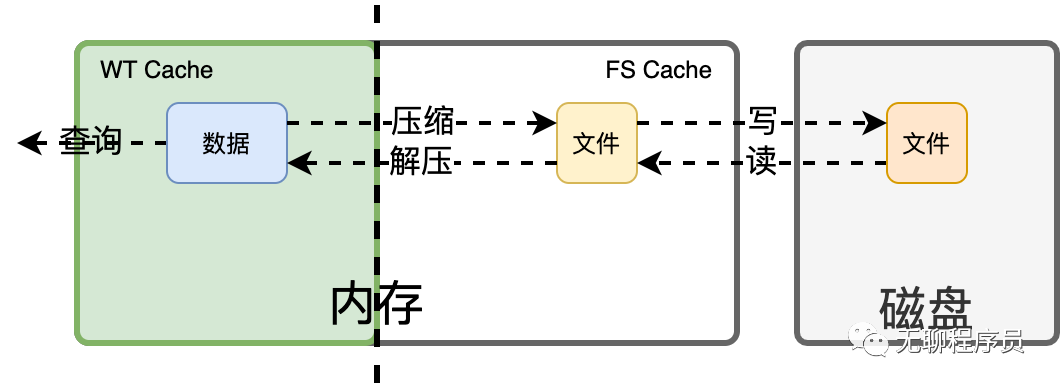
-
冷数据加载时,文件由磁盘加载到FS Cache,两者内容完全一致;
-
FS Cache中的文件内容经过解压、解密,加载到WT Cache成为实际可用的数据;
-
数据被用于服务查询
因为这里存在压缩解压的过程,换个说法:
-
数据放在FS Cache比放在WT Cache更省空间;
-
使用FS Cache中的数据需要先消耗CPU解压并将数据调入WT Cache;
基于上面的分析和MongoDB最佳实践,调整WT Cache的原则是:
-
如果热数据能够容纳在WT Cache中,则将WT Cache调大使之容纳热数据。但最大不能超过默认值;
-
如果热数据可以容纳在FS Cache中,则将WT Cache调小,使FS Cache足够容纳热数据;
-
如果以上两者都不能满足,则不要调整WT Cache(保持默认);
最后注意一点,以上描述的都是一台服务器运行一个mongod进程的情况。如果一台服务器上运行了多个mongod进程,则所有mongod的cacheSizeGB加起来不可以超过默认值。
关键阈值
脏数据<5%
脏数据<5%时不做任何处理,脏数据只在内存中,等待下一次Checkpoint时刷到磁盘。Checkpoint是MongoDB将内存数据与磁盘数据同步的机制,可以理解为将脏数据写到磁盘上。
Checkpoint每隔1分钟进行一次。由于Checkpoint本身也需要一定时间,这里的“每隔1分钟”是指一个Checkpoint完成后间隔一分钟才进行下一次。
细心的朋友可能该问了,Checkpoint是1分钟一次,如果脏数据低于5%,那在里程崩溃时是不是最多会丢失1分钟的数据?答案是对但也不对。如果只依赖Checkpoint,那确实是会丢失1分钟数据,但是MongoDB还有100ms刷盘的Journal(WAL)提供了第二层保护机制。所以在真正发生进程崩溃时会用上一次Checkpoint加上Journal恢复到丢失最多100ms数据的状态。再加上第三层机制——复制集,数据会从其他节点上再被复制过来,所以最终结果是数据都不会丢失。当然回滚的情况另行讨论,与当前主题无关,这里不再赘述。
脏数据>5%
当脏数据>5%时说明在Checkpoint之间产生了较多的更新操作。为了减小Checkpoint的压力,MongoDB会使用一个后台线程查询并找到脏数据,同时把它们同步到磁盘上,尽量保证在Checkpoint到来之前压数据<5%。
脏数据>20%
如果在两次Checkpoint之间脏数据达到了20%以上,则说明期间产生了大量写操作,以至于后台线程清理脏数据都已经忙不过来。除了少数Bug的情况,这通常是由于磁盘性能瓶颈造成的(观察读写延迟和util%通常都可以观测到较大的磁盘压力),而不像很多人想的那样是否增加刷盘线程就可以解决问题。比如说你只能扛100斤的东西,我叫再多拉拉队给你加油你还是只能扛100斤,帮助不大。
尽管如此,在这种情况下,MongoDB还是会运用本来用于服务应用请求的线程来帮助清理脏数据。其意义不在于更快,更多的是降低应用程序请求的处理速度,从而控制新的脏数据进入的速度。如果刷盘是开源,那么这里做的就是截流。
读缓存使用率<80%
此时不作任何动作。也就是很多人说的“吃内存”。如果你仔细想一下的话就知道这是正常行为。原因在于,只要是缓存的数据,就有可能被人使用。而一旦命中缓存,就不用从磁盘捞数据,也就加快了访问速度。这就是数据库的本职工作——高效服务请求,而不是省内存。所以不要说什么“吃内存”,这只是在做本职工作,并且大部分数据库也都有同样的行为。如果不愿意占用这么多内存,应该通过cacheSizeGB限制内存使用,而不是占完了再来想怎么释放。
读缓存使用率>95%
此时跟脏数据达到20%时有相似的行为,动用服务应用的线程来帮助清理缓存。其目的也是相近的,通过这样的方式截流来降低新请求进入的速度从而更好地清理缓存。
读缓存使用率=100%
最坏的情况出现了,MongoDB也会动用最紧急的处理机制,阻塞所有请求,直到读缓存使用率降低到80%以下为止。
总结
作者介绍:
张耀星,MongoDB亚太区首席技术咨询服务顾问,MongoDB中文社区常委会委员,论坛联席主席。公众号:无聊程序员。
![]()
5月29日(本周六)来长沙即可参加MongoDB中文社区2021年第一场线下大会!互联网证券及金融系统实践案例、物联网实时数据融合平台案例分享,存储引擎、数据迁移同步等诸多MongoDB一手实践干货在现场等你来!

长沙大会速递Conference
时间:2021年5月29日(周六) 13:30 – 18:00
地点:长沙市岳麓区中南大学科技园(研发)总部1号栋3楼309多功能厅
名额: 150人
报名链接: https://sourl.cn/EJNURJ
* 9.9元票请添加小芒果(微信ID:mongoingcom)按照说明获取。
* 分享活动还有机会领取MongoDB周边礼品!
您也可以直接阅读相关活动介绍:
大会奖品Prizes




你好,请教2个问题:
1. 实际生产环境中遇到mongod一直占着很大的内存(40G),这时候mongodb其实是空闲的,不明白为什么不会自动释放一些内存。另外我设置的wiredtiger.cacheSize 是16G而已。
2. 最佳实践是一个机器上最好只运行一个mongod吗?