 MongoDB中文社区
MongoDB中文社区
本文的上篇探讨了WiredTiger中WAL的原始算法,该算法用于合并写操作以达到最小化I/O的目的。它没有使用耗时的锁,而是分两个阶段使用CAS原子操作来实现。只要每个核运行的线程不太多,这个算法就可以非常好地工作。但当线程数超过该限制时,它为了避免锁而依赖于忙等待的机制会导致logjam——鉴于许多MongoDB的任务都会导致每个核有大量线程,这个问题相当严重。它阻碍了MongoDB将WiredTiger作为v3.2版本默认存储引擎这一目标。
多亏我的同事、高级技术服务工程师Bruce Lucas,这个故事有了个圆满的结局。是Bruce最先发现了logjam并报告给了我;而我们在没有给其它部分带来任何负面影响的情况下一起将其解决了。由于Bruce的思路没有被最初的设计方式所影响,他因而能够洞悉关键,为解决方案铺平道路,使得WiredTiger成为了v3.2版本的默认存储引擎。
为何线程必须等待?
那是2015年夏天,我还在试图消除Bruce发现的logjam。当时我正努力通过减少线程竞争来提高性能,可惜进展缓慢。而另一方面,Bruce则从完全不同的方向着手。他对线程在复制数据之前是否需要等待提出质疑,并着手编写了一个原型来证明这并不是必须的。
我们既不能禁止MongoDB使用大量线程——它正是为了此目的而设计的;也不能要求它只能在大规模的多核机器上运行;而使用互斥体更是天方夜谭。Bruce明白这些方法都是死路一条,所以他仔细研究了算法的概念构建块(conceptual building blocks):
- 在slot中声明一个位置(这需要原子性)这一操作可以和向slot中复制数据(这可以并行执行)这一操作解耦。
- 原子地在slot中声明一个位置,我们称之为连接,可以通过对一个索引变量进行CAS操作来实现。
- 该索引与声明的总字节数相等,因此我们称之为连接计数器(join counter)。
- 直到所有连接slot的线程都实际执行了它们的复制操作,slot才能被写入操作系统,因此slot必须要跟踪线程何时完成复制。
- 可以在释放计数器(release counter)上进行一个原子操作来跟踪写入的字节。当它的release == join时,一个slot就可以写入操作系统了。
- 我们还必须跟踪slot的状态,这样线程就知道它何时不可用、何时可连接、以及何时准备写入操作系统等。
这些项目单独来说都不需要线程等待;但当它们彼此交互时,这个需求就产生了。例如,为了安全地向操作系统写入一个slot,线程必须确定slot的状态是否允许,并且所有已在其缓冲区进行声明(join)的线程都已完成数据的复制(release)—— 而且这三个组件的检查必须原子地执行。
问题在于CPU不允许涉及两个以上寄存器的原子操作。(脚注:理论上是可以的,但在实际中没有这么做。)如果在单独的变量中跟踪连接(join)、释放(release)和状态(state),我们可以将状态与一个READY_TO_WRITE值进行比较,或者将join与release进行比较,但并非两者同时。
因此,要实现这个原子操作,必须使用单个寄存器 (变量) 来将slot的状态(state)与对连接(join)和释放(release)的字节记录结合起来。这正是本文上篇中描述的slot_state字段。
有个想法很有诱惑力,那就是允许线程在连接时增加slot_state,在释放时减少slot_state。但是我们列表中的第二项不允许这样做:slot_state必须始终指向缓冲区中的下一个空闲字节。允许一个线程在连接完成之前减少slot_state会将slot_state指向其它线程已经声明的内存。对缓冲区使用一个独立的、只增不减的指针可以解决这个问题,但这会破坏原子性。
总之:对原子性的需求限制了我们只能使用单个变量,而对跟踪线程可以写入位置的需求意味着我们不能将递增和递减操作混合到一起。因此,我们必须分两个阶段处理。在连接阶段,线程声明空间,但其后必须等待释放阶段开始;在释放阶段,线程将数据写入它已声明的空间并标记其写入的字节。
灵光乍现
如果我们能够为连接(join)和释放(release)维护两个独立的计数器,就可以消除线程等待的需要。我们可以让它们一从连接操作获得写入偏移量后立即向slot中开始写入。
但Bruce注意到了一些关键问题:这些计数器很容易放在32个比特内,所以它们都可以放在一个int64中。我们可以从逻辑上将一个寄存器分割为维护所有必要信息的部分:slot的状态和两个计数器。
有了这个方案,我们可以通过位屏蔽(masking)和位移位(bit-shifting)操作来实现连接和释放。Bruce用几个宏对其进行了整理:
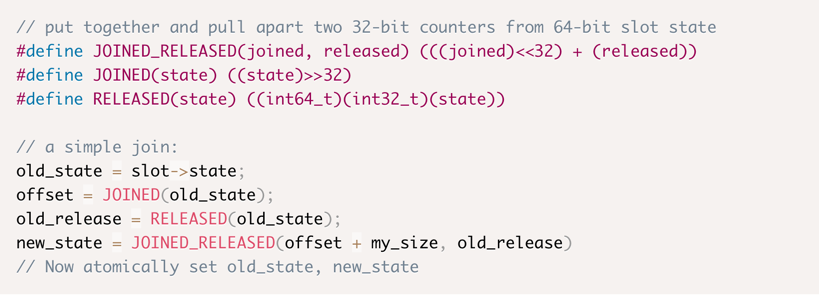
为了测试他的这个想法,Bruce编写了一个程序来进行演示,没有使用任何WiredTiger或MongoDB代码。他模拟了多线程负载并跑了一些数字,而实验结果使他大受鼓励并让他为WiredTiger做了一个patch。在概念验证阶段,他忽略了所有细节:滚动日志文件、太大而无法存储在缓冲区中的记录、会导致中断数据流的错误和超时等等。Bruce忽略了所有这些,而他的patch足以证明,即使在服务器正进行大量其它工作的情况下,他对WAL的优化效果也非常可观。
在不需要等待连接/释放阶段更替的情况下,线程可以声明一个点并对其进行写入,记录写入的字节然后离开,过程中无需任何等待。这个实现消除了对“leader”线程的需求,并将职责分摊到了两个线程上。当一个线程在执行填充缓冲区的连接时,它会关闭这个slot并准备一个新的。当一个线程在没有其它等待的写入操作并且缓冲区已满的情况下完成释放时,它会将缓冲区写入操作系统。
从概念验证(POC)到生产环境代码
当Bruce把他的第一个patch发给我的时候,我既充满希望又有点害怕!他设计的方案从一个我从来没有考虑过的角度来试图解决这个问题,但还有太多的细节没有被考虑进去;要与现有的WAL代码协调起来还需要做很多工作。但是性能的改进是如此的显著,这显然值得一试。在接下来的几周里,我开始查缺补漏,一点一点地解决了这些复杂问题。随着我工作的进行,我谨慎的乐观情绪变得越来越强烈,直到最后我终于使用新的方法完整实现了一个WAL。
最终,连接(joining)、复制(copying)以及释放(releaseing)的代码看起来像这样:

int64的slot_state中JOINED和RELEASED位在这里显示为两个单独的数字。
尽管我们在大多数计算中并没有显示它们,slot->state也为STATE编码了一些位。为了示范我们还指定了一个缓冲阈值;而其实际值远远高于1280。
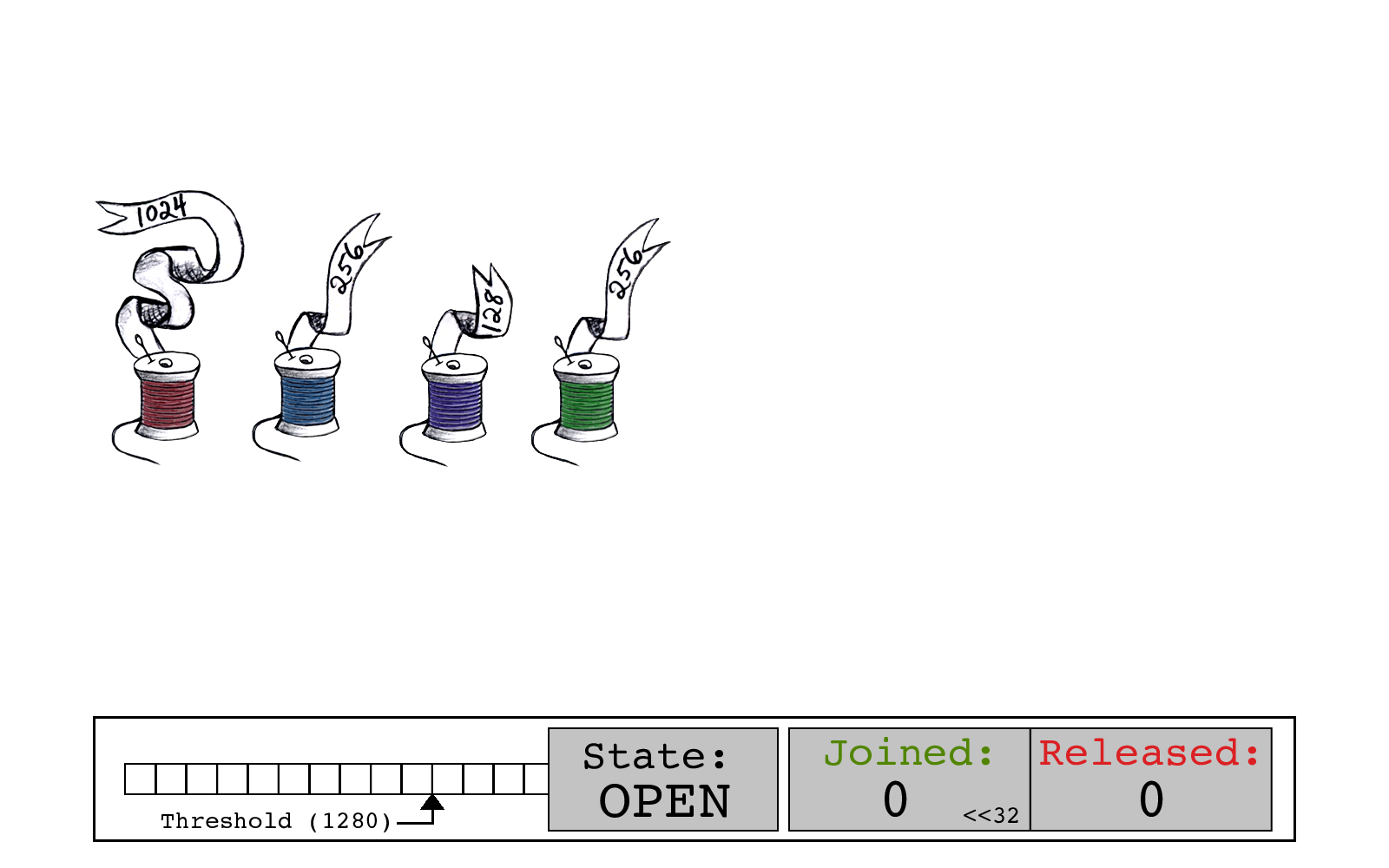
绿色线程通过读取当前的slot->state开始其连接,其中JOINED计数和RELEASED计数均为零。

绿色线程通过将其大小256添加到JOINED位来计算new_state。
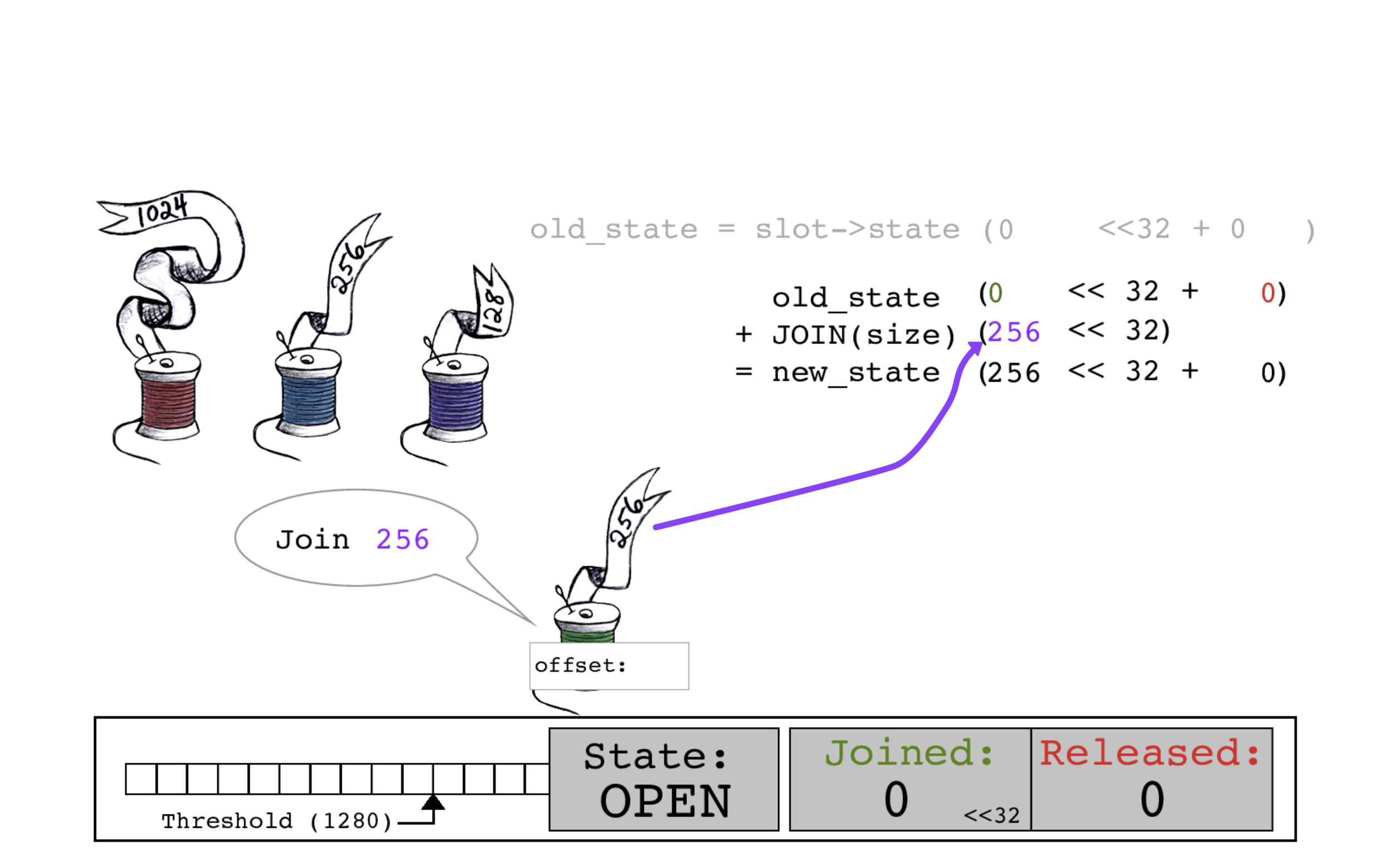
绿色线程执行CAS原子操作。它以旧的JOINED计数0作为偏移量,将slot->state的JOINED计数更新为256。
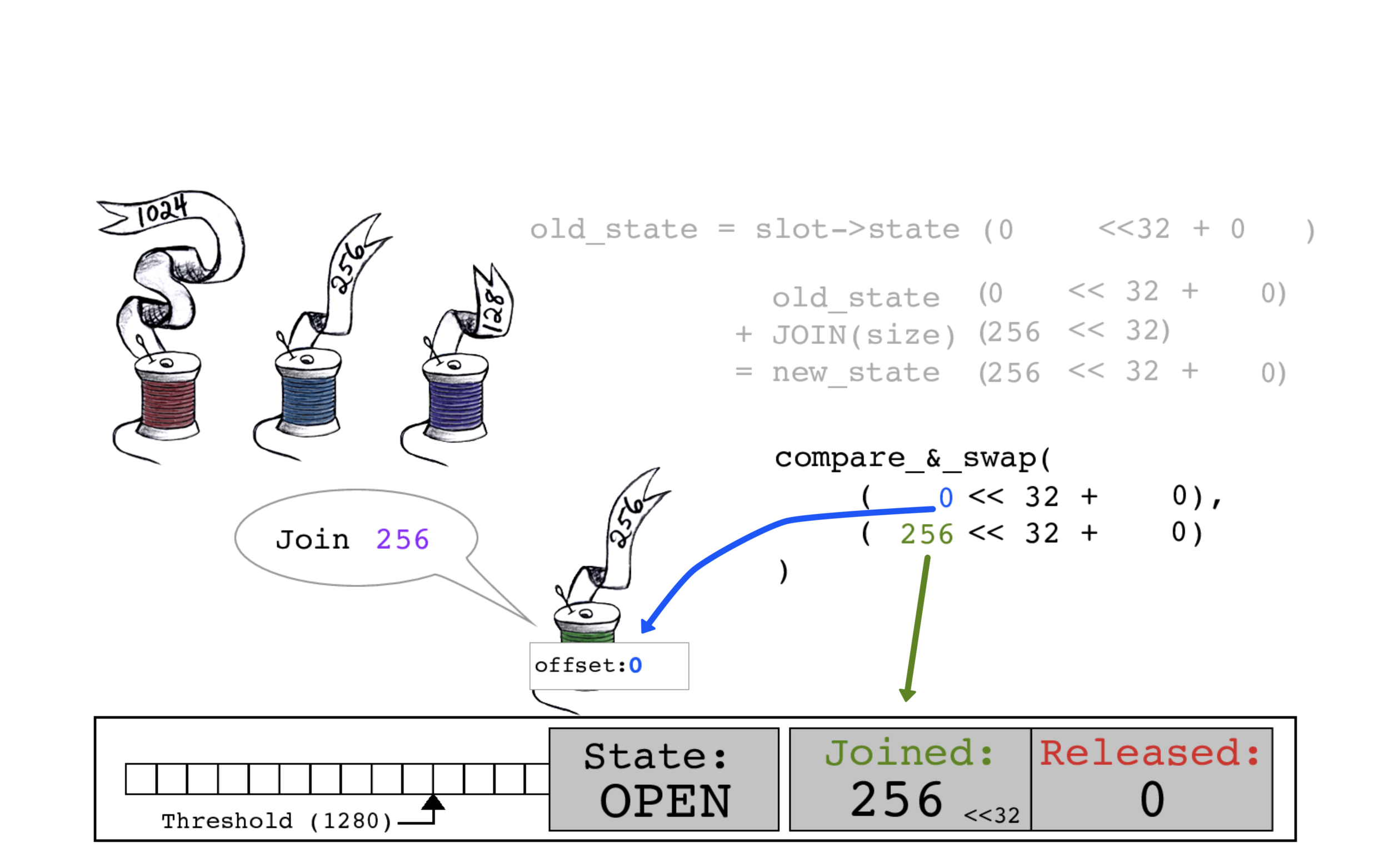
无需等待,绿色线程就将数据复制到其偏移量0。

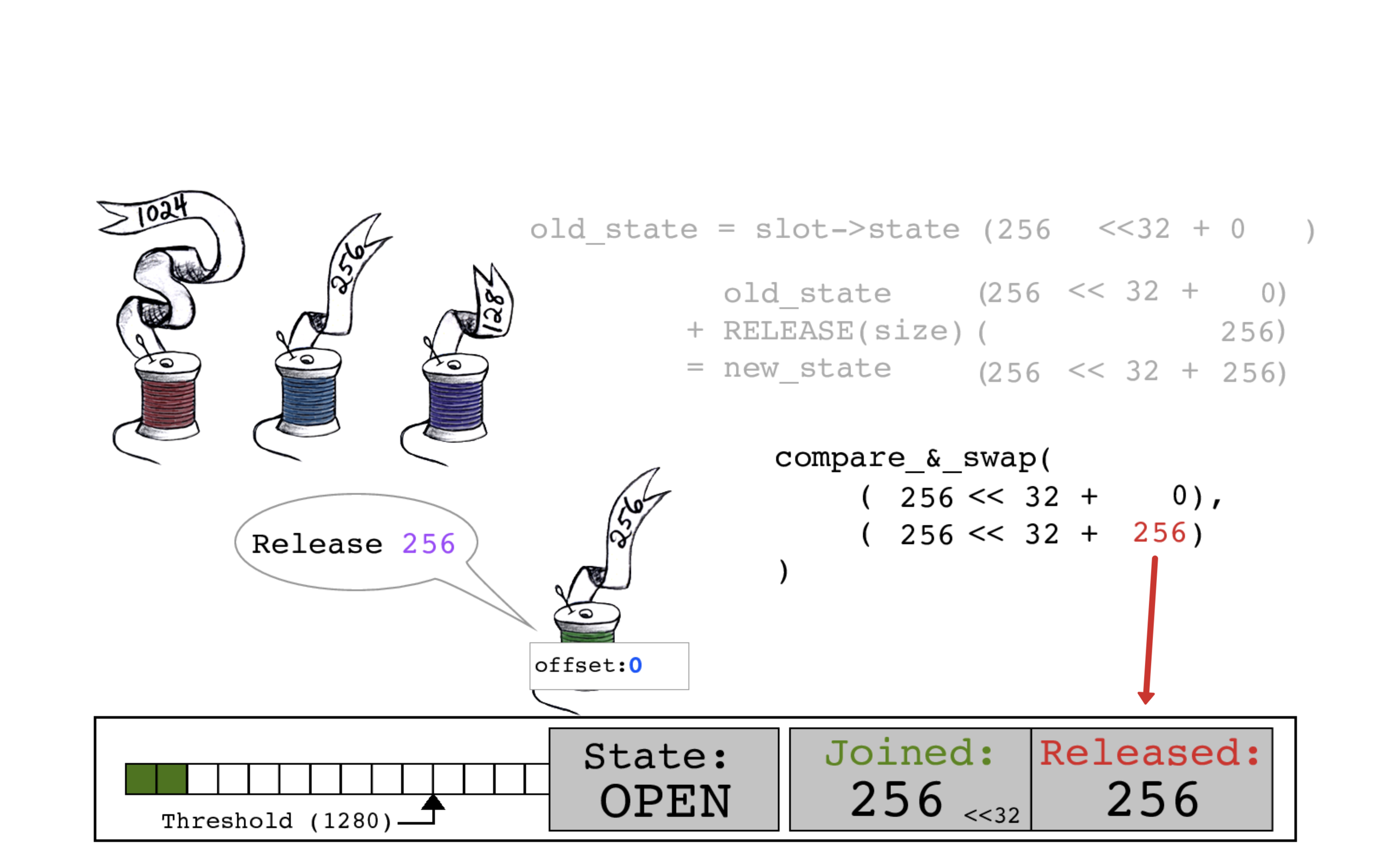
绿色线程通过再次读取当前的slot->state以开始释放操作。
这是必须的,因为尽管这里没有描述,但实际上其它线程可能在这期间已经更新了slot->state。

现在,线程将其大小256添加到RELEASED位以创建new_state。

通过CAS原子操作,用新的RELEASED计数256来更新slot->state。
绿色线程重新开始工作,而蓝色线程开始连接。没有发生锁或等待!
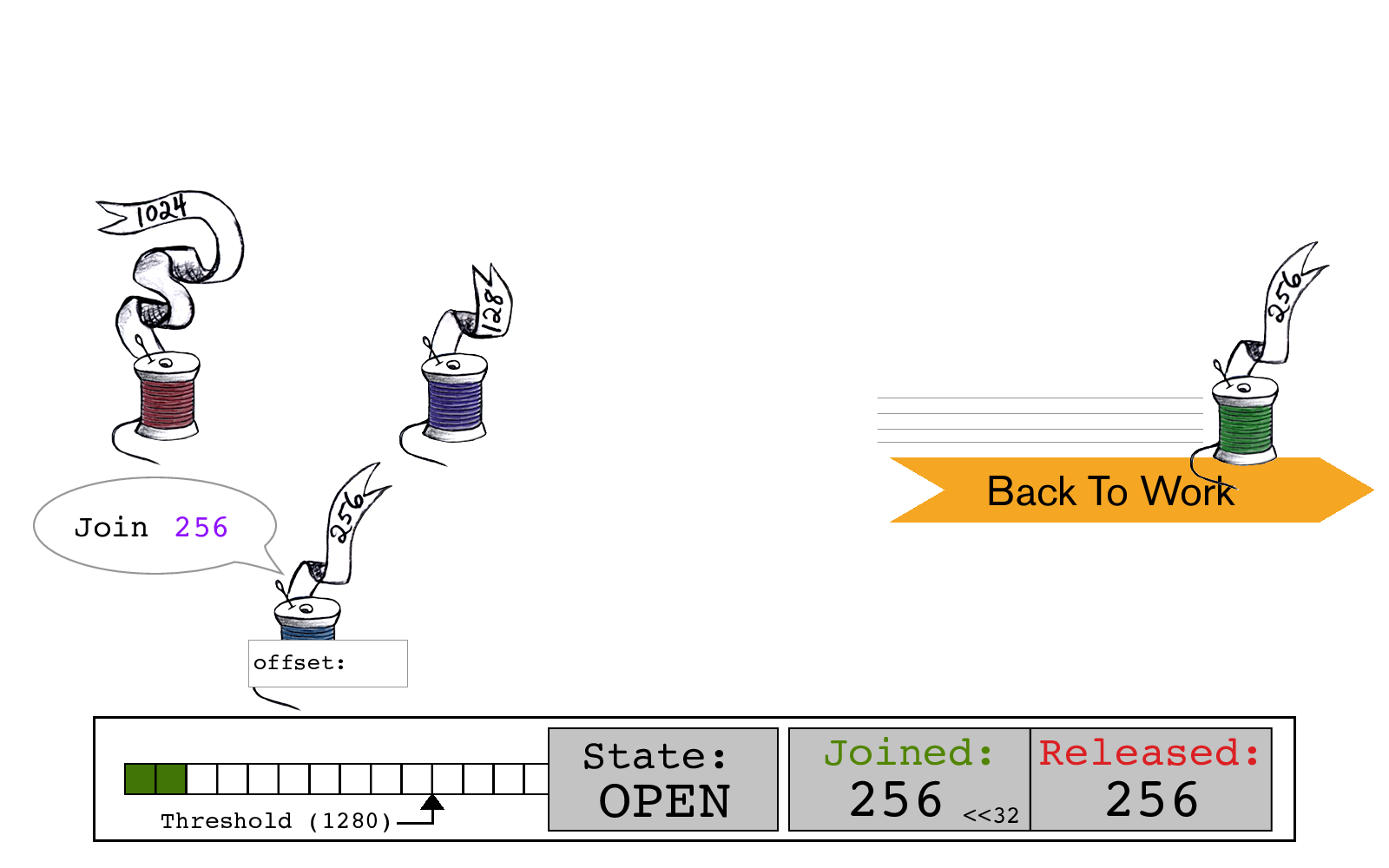
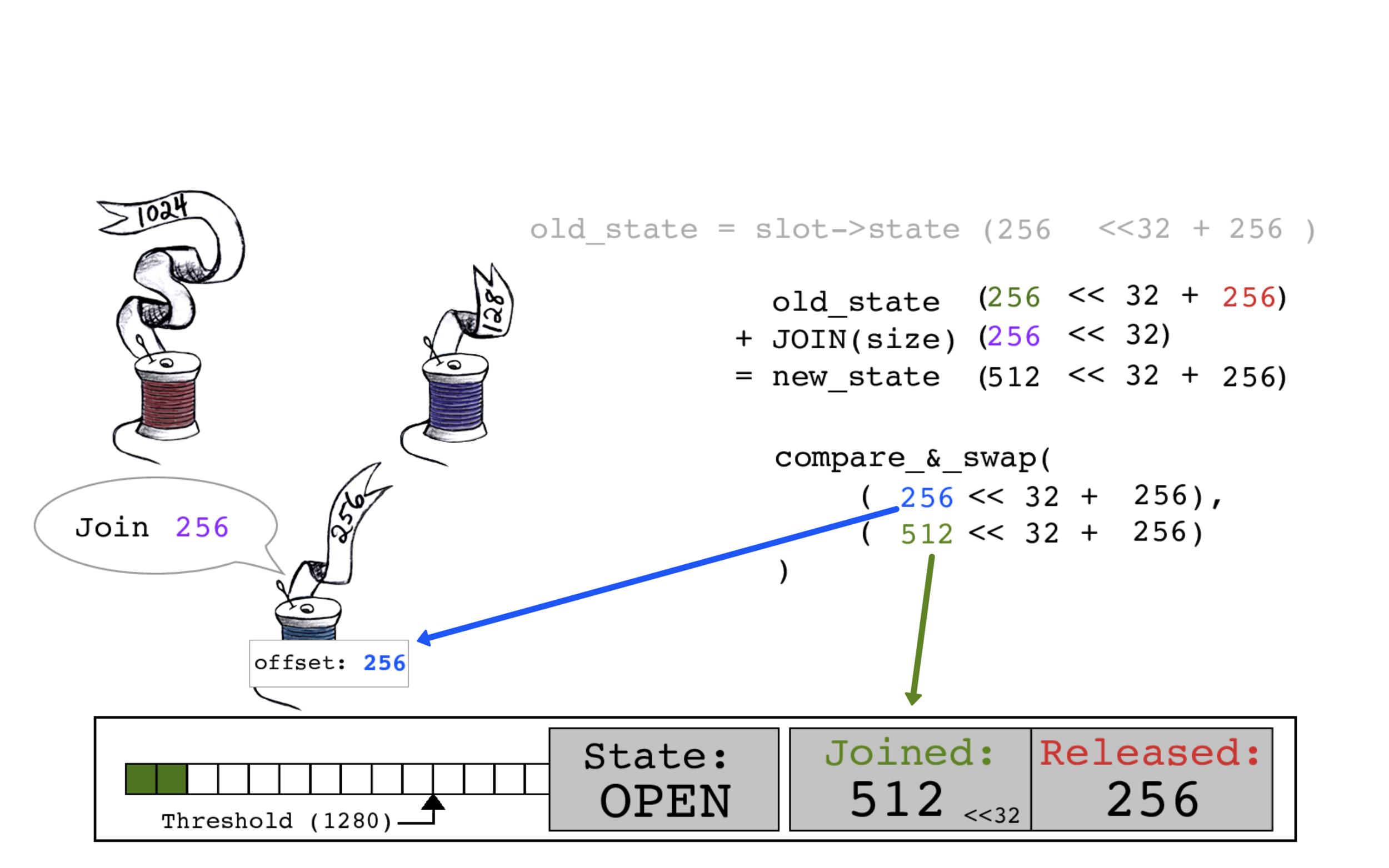
蓝色线程通过读取当前的slot->state开始其连接,其中JOINED和RELEASED计数均为256。

蓝色线程通过将其大小256添加到JOINED位来计算new_state。

蓝色线程执行一个CAS原子操作,用旧的JOINED计数256作为偏移量,将slot->state的JOINED计数更新为512。
在蓝色线程完成复制和释放之前,紫色线程开始连接。

紫色线程读取当前的slot->state,这是这个过程中第一次在一个连接操作开始时JOINED位(512)和RELEASED位(256)的计数产生了不同。
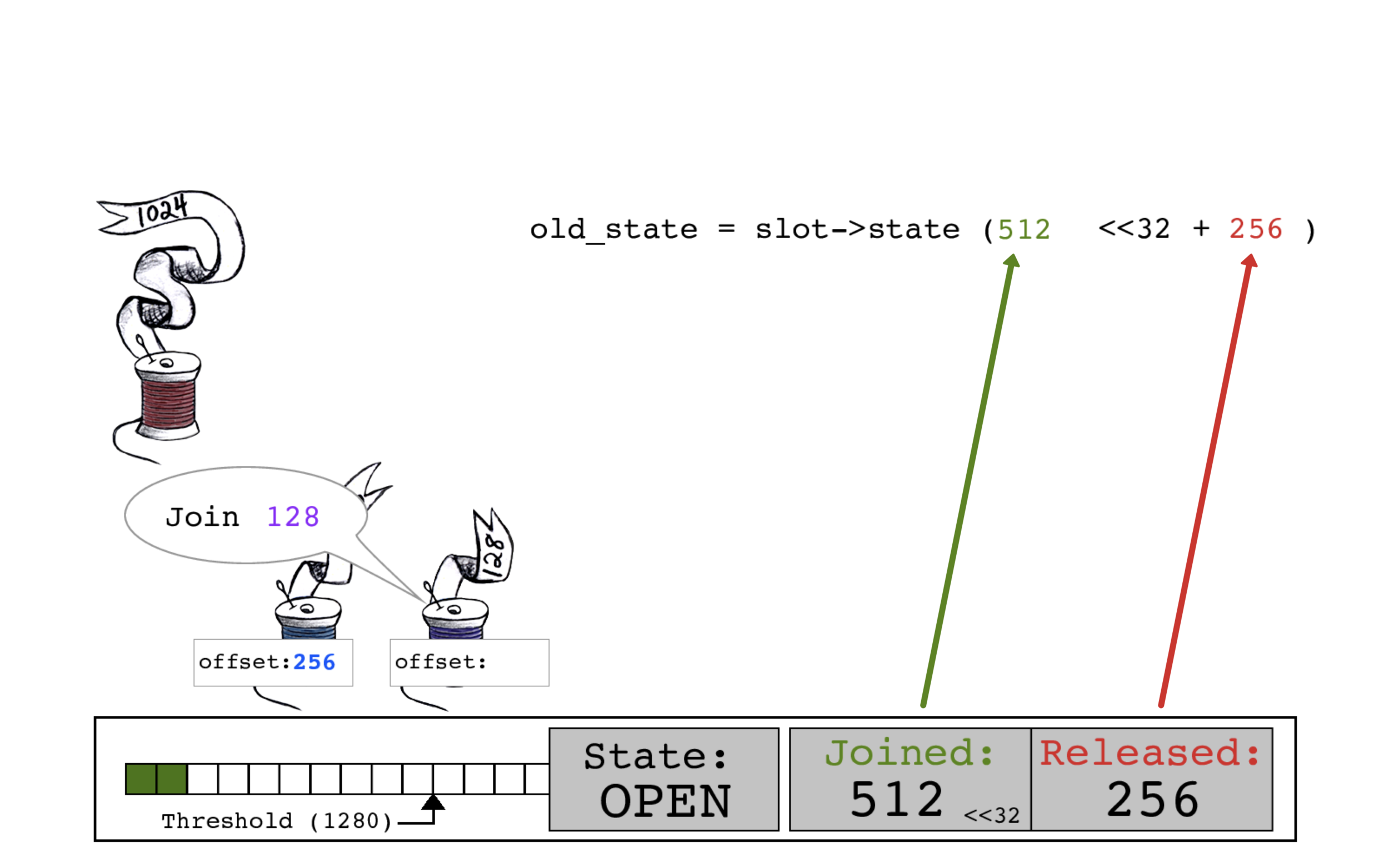
紫色线程通过将其大小128添加到JOINED位来计算new_state。
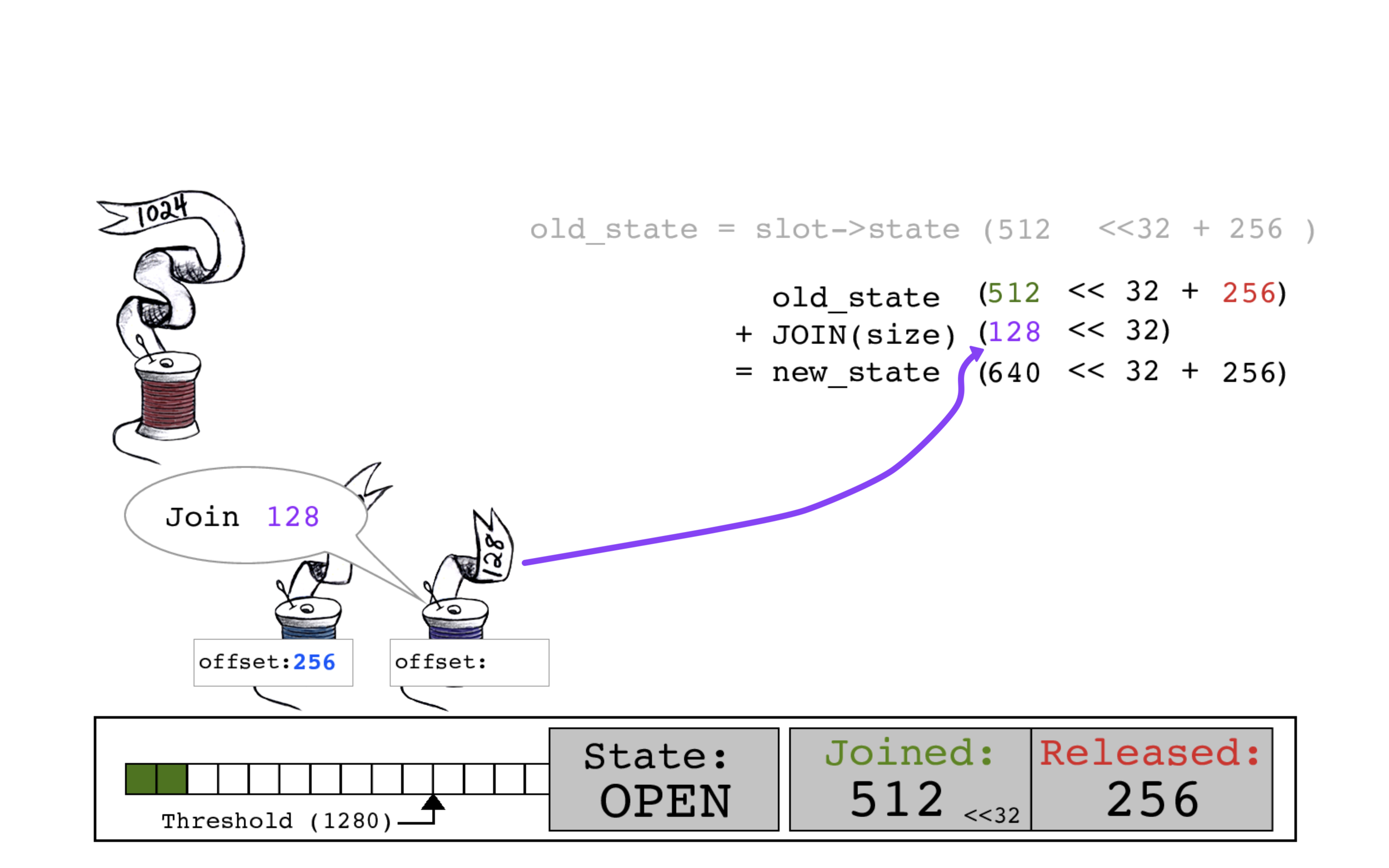
紫色线程执行一个CAS原子操作,用旧的JOINED计数512作为偏移量,将slot->state的JOINED计数更新为640。

紫色线程将数据复制到其偏移量512。

紫色线程通过读取当前的slot->state以开始释放操作。
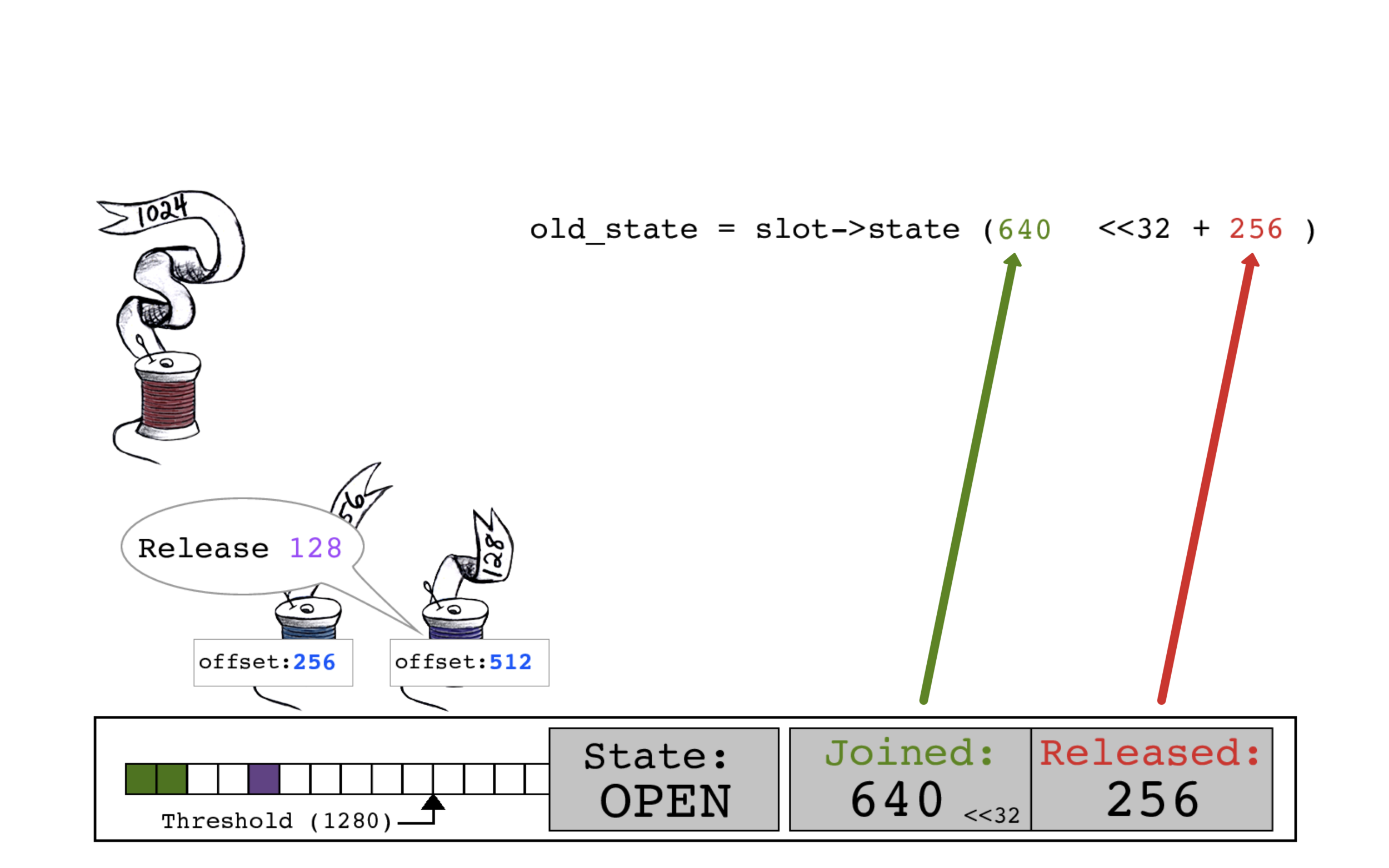
紫色线程将其大小128添加到RELEASED位以创建new_state。

与此同时,蓝色线程可以并行地将其数据复制到偏移量256。
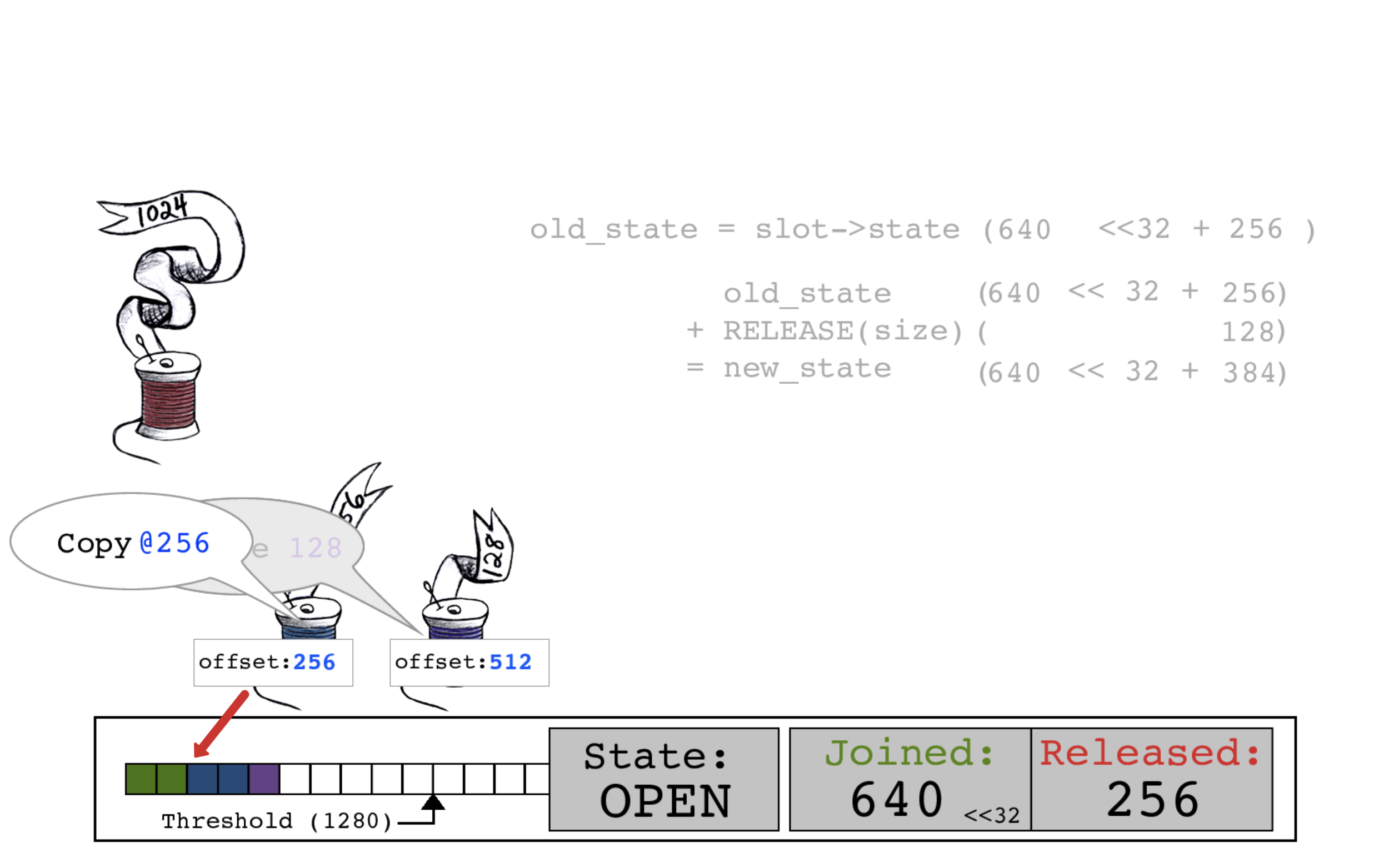
回来看紫色线程:通过CAS原子操作,用新的RELEASED计数384来更新slot->state。
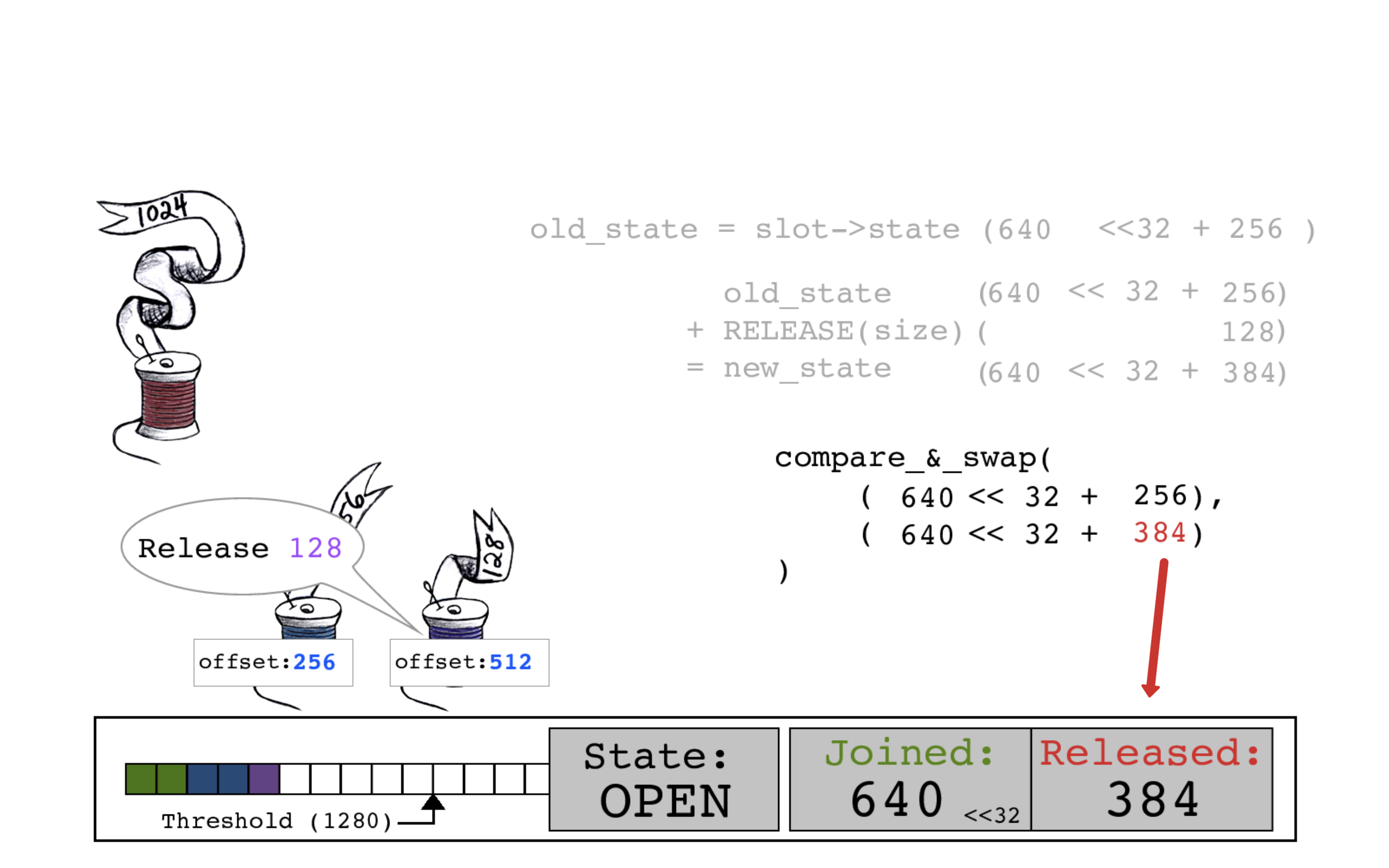
现在紫色线程已经完成了任务并重新开始工作。
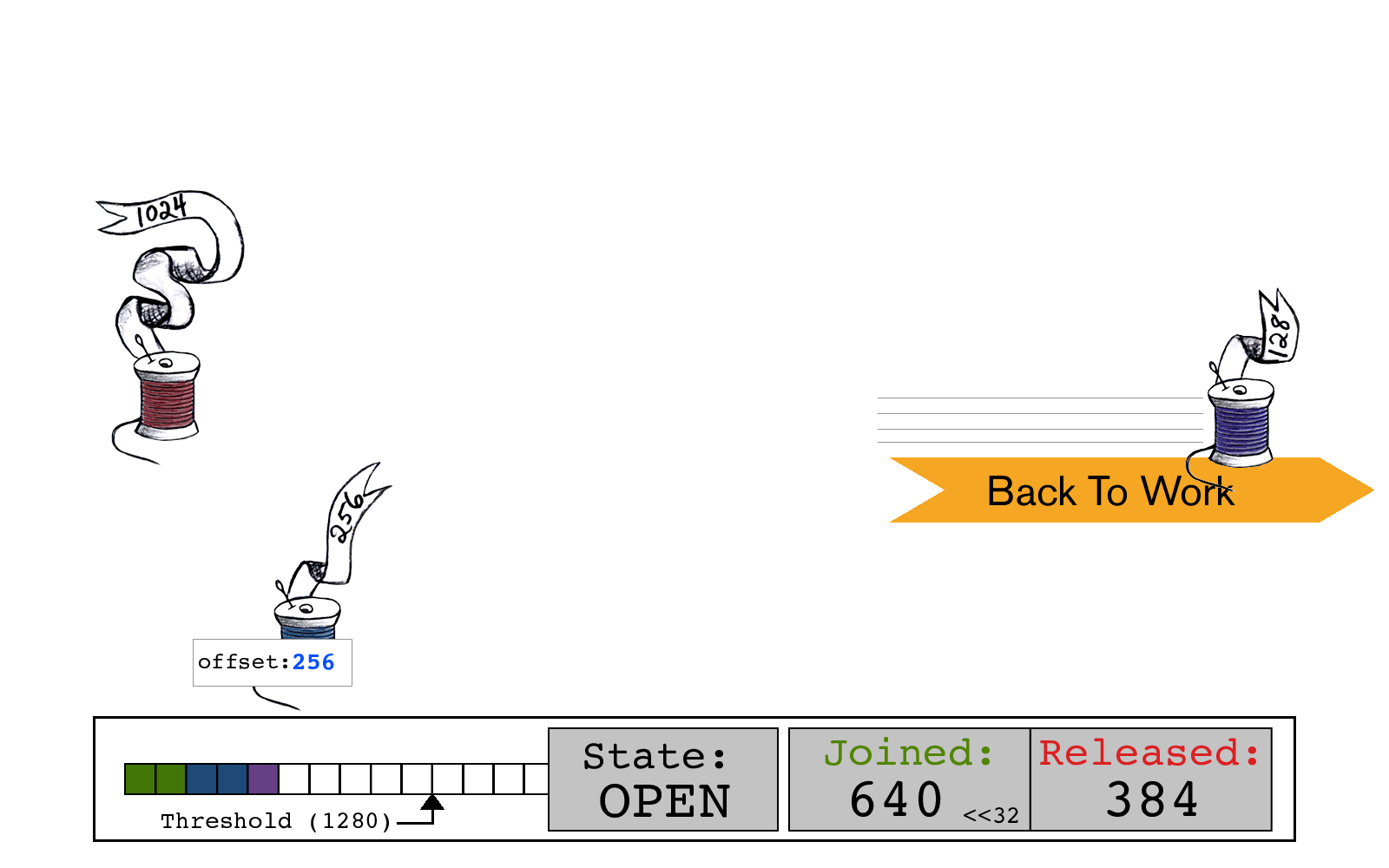
同时,蓝色线程开始释放,读取当前的slot->state,JOINED计数为640,RELEASED计数为384。
蓝色线程通过将其大小256添加到RELEASED位来计算new_state。

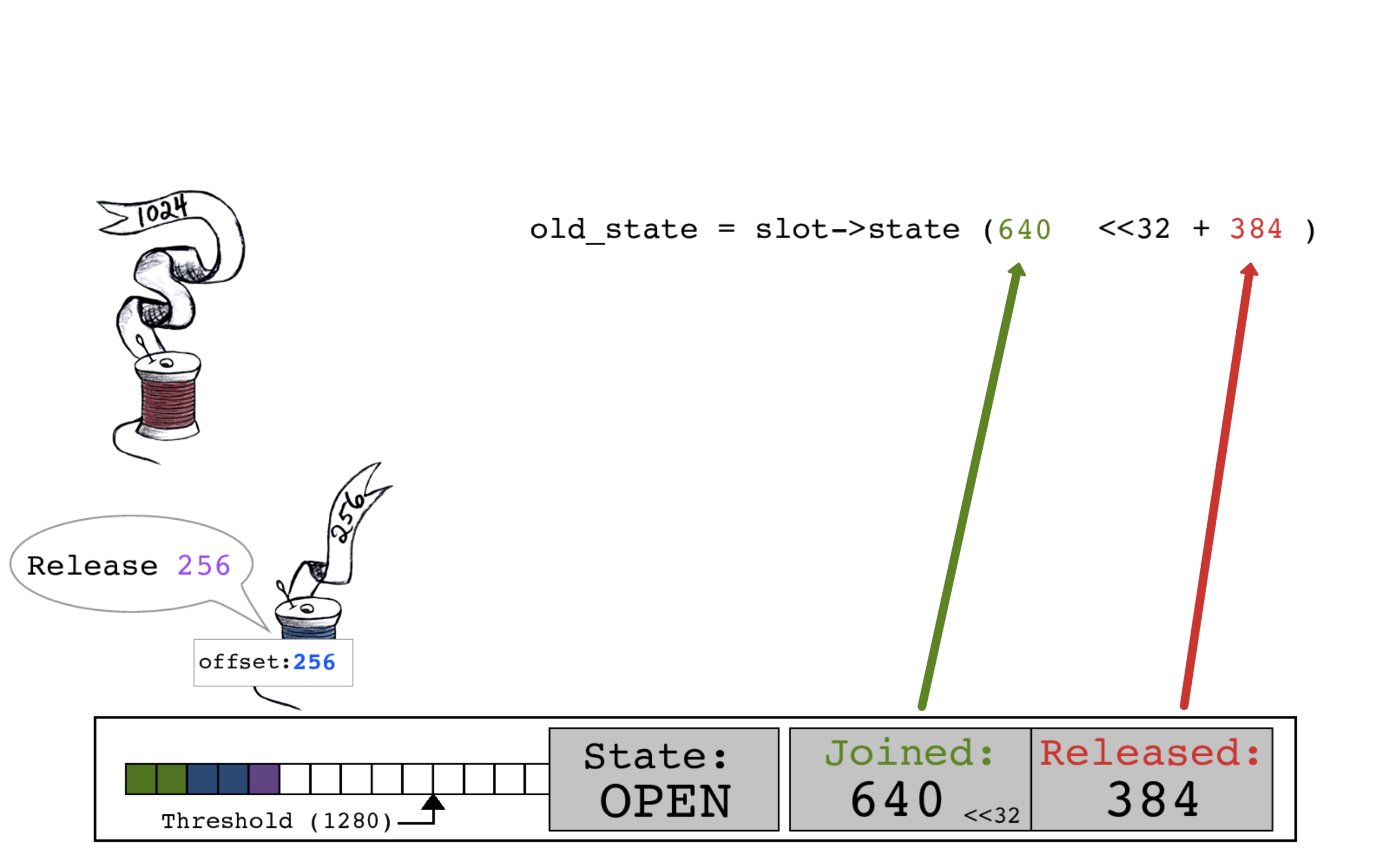
紫色线程执行一个CAS原子操作,用新的RELEASED计数640来更新slot->state,现在JOINED和RELEASED计数再次相等了。
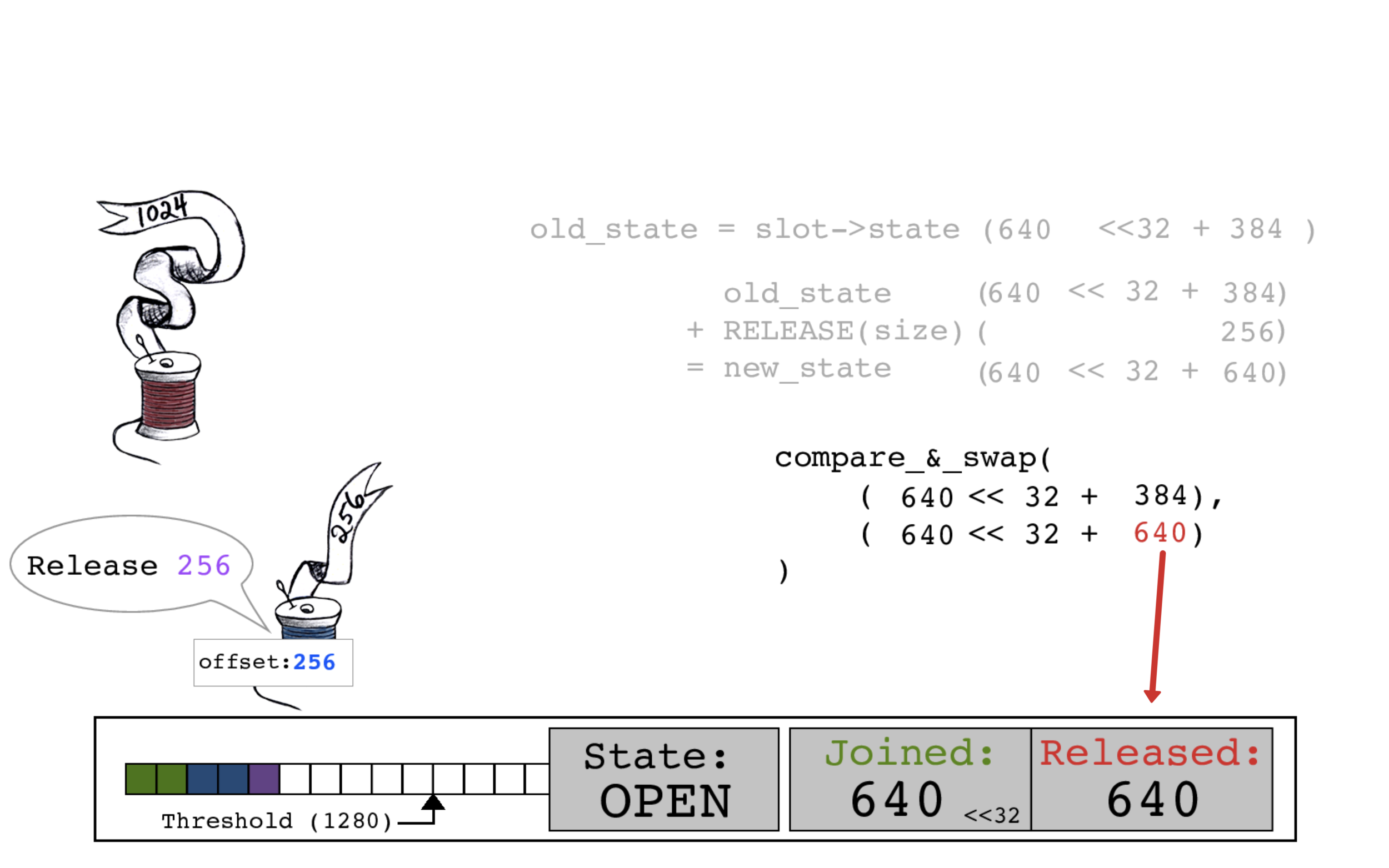
蓝色线程重新开始工作。
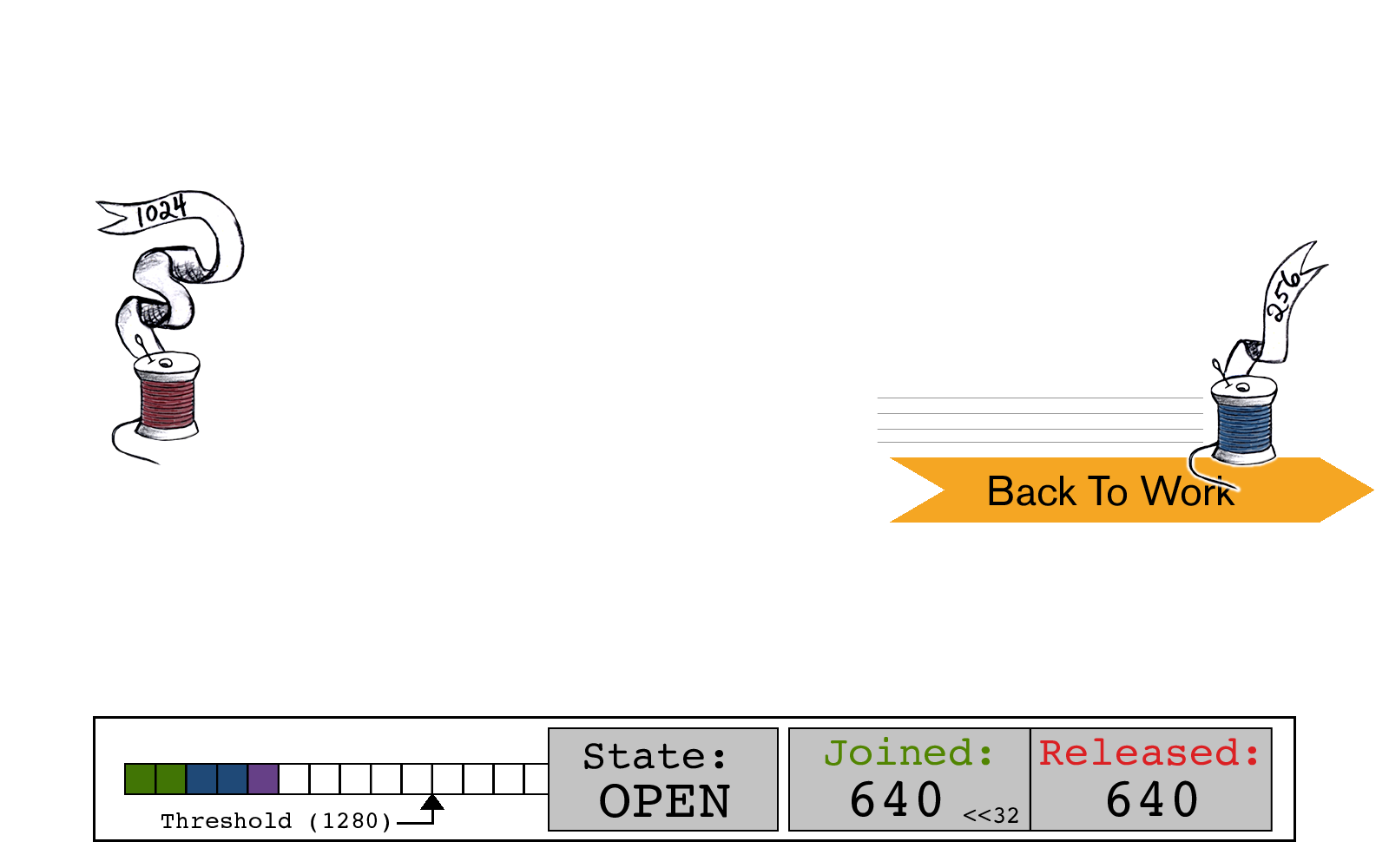
红色线程开始连接。

当红色线程计算新的JOINED计数时发现它的数据将越过缓冲区阈值,这表示slot应该被关闭并准备写入操作系统了。
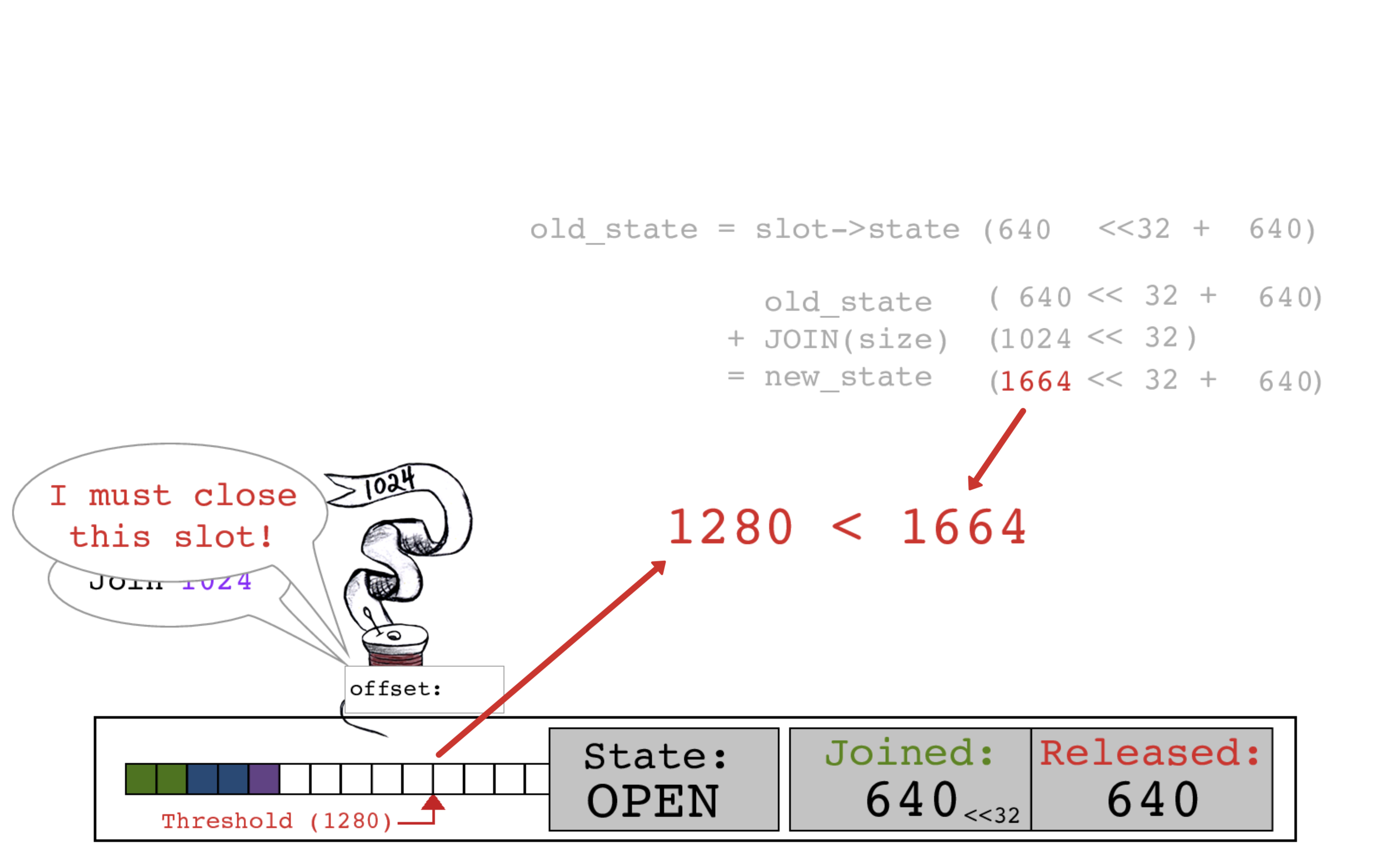
当红色线程执行其CAS操作时,还将相应的位进行添加并将slot状态置为CLOSED。
红色线程以旧的JOINED计数640作为偏移量,设置slot->state的JOINED计数为1664。
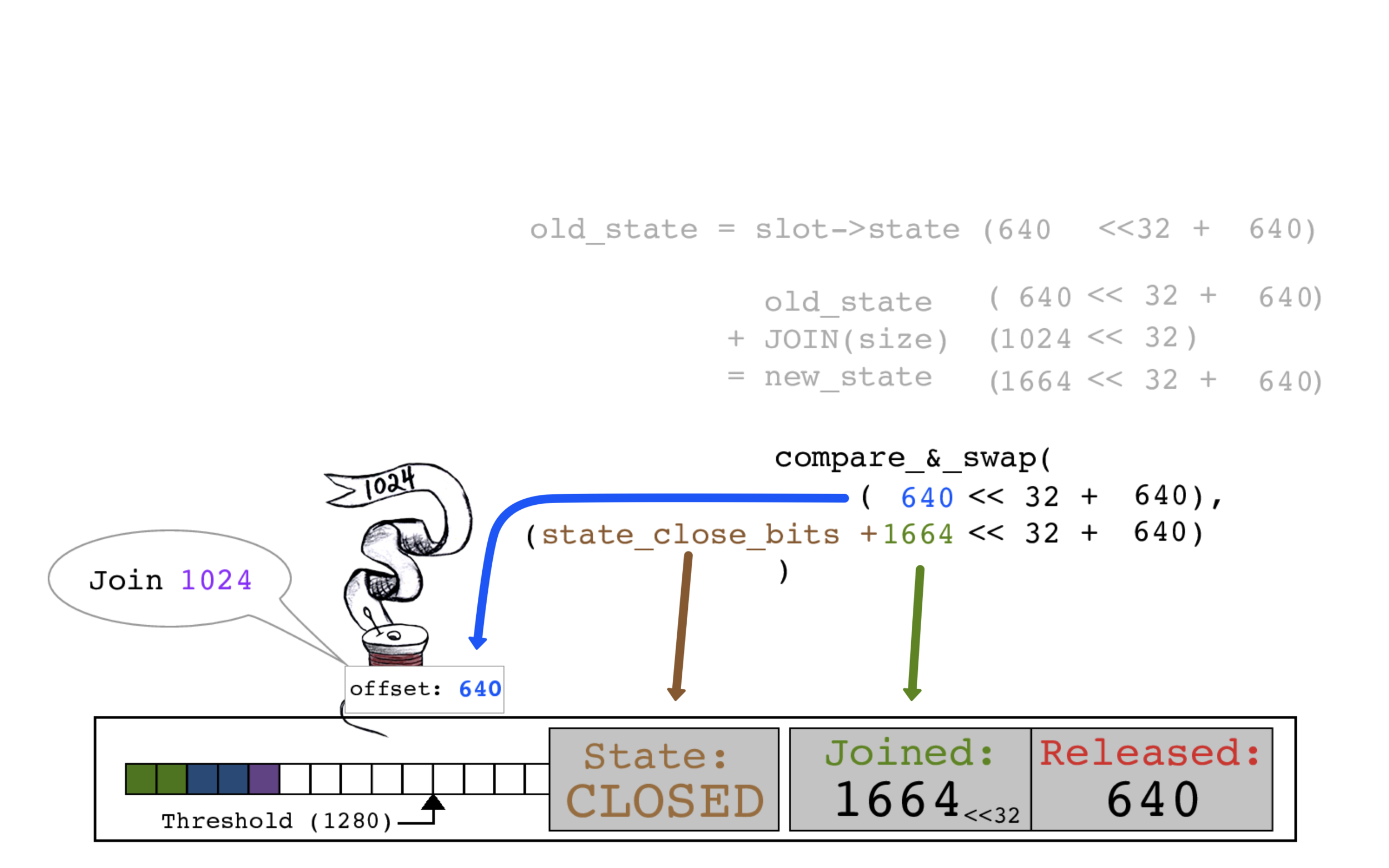
红色线程执行复制操作。
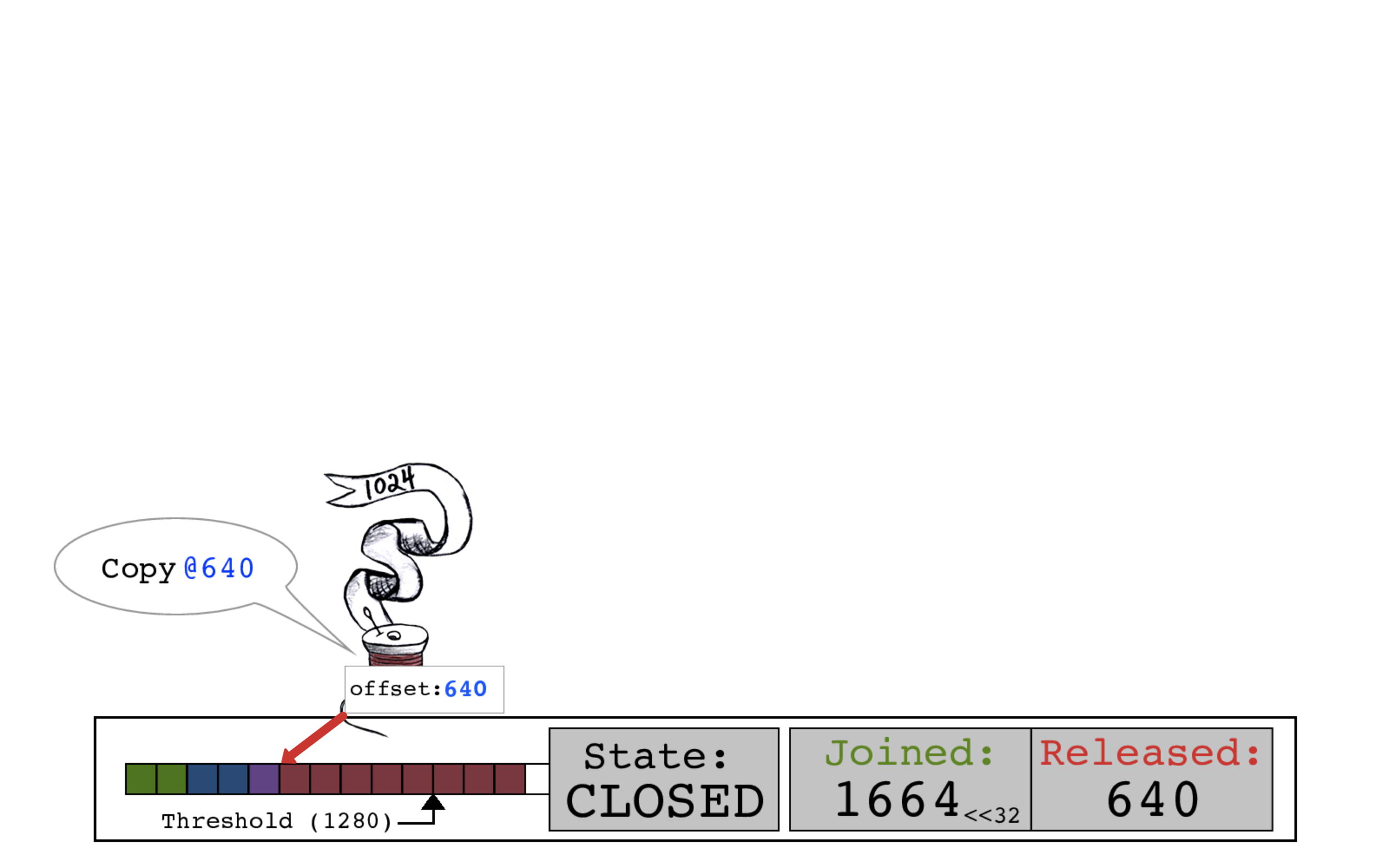
红色线程执行释放操作,并将slot->state的RELEASED计数设置为1664。

当 STATE == DONE 并且 JOINED == RELEASED 时,红色线程知道所有复制均已完成,可以安全地将缓冲区写入操作系统了。
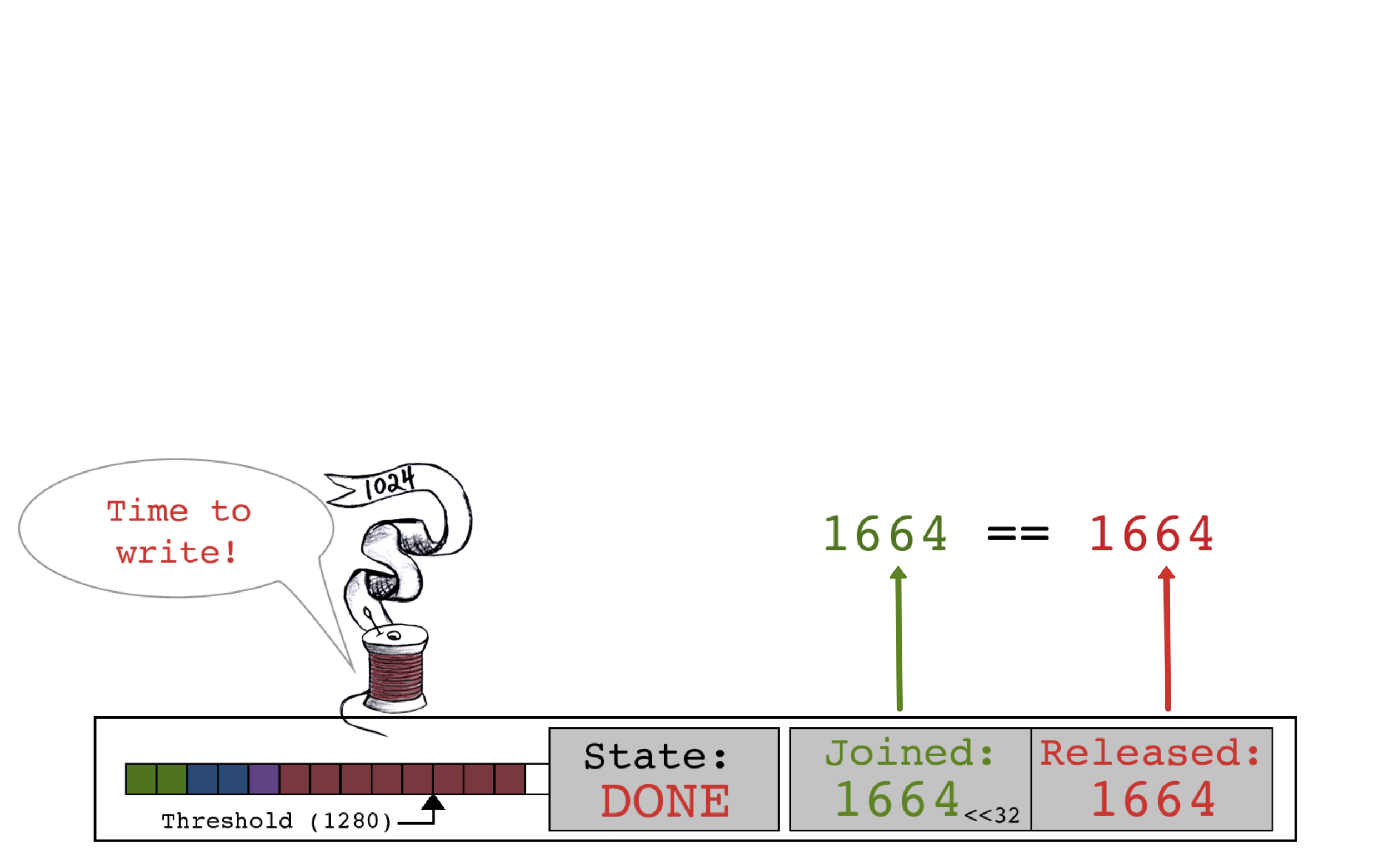
红色线程发出写操作请求,并重新开始工作。

一个重要细节:空闲系统
由于将记录写入操作系统这个动作是由填充slot缓冲区来触发的,因此该算法可以很好地处理不断传入的记录。但如果系统处于空闲状态,那么当前未填充缓冲区中的任何记录都不会被刷新, 直到有足够的写入来填充缓冲区, 或者使用 j:true 强制同步进行写入。虽然从技术上讲,缓冲区中的记录是在没有持久性保证的情况下显式写入的,但是系统空闲时记录不应保持在未刷新状态!为了解决这个问题,我们添加了一个50毫秒的空闲超时来将缓冲区推送至操作系统。这限制了一个记录暴露在进程崩溃风险中的时间,并且MongoDB每100毫秒会做一个磁盘同步,以降低系统崩溃的风险。
现在快多了
针对之前的问题,我们重新用生产环境代码对其进行了测试,结果令人振奋:
| threads | existing 3.0.4 code | 3.0.4 with new algorithm |
|---|---|---|
| 8 | 278 k ops/s | 281 k ops/s |
| 16 | 379 k ops/s | 419 k ops/s |
| 24 | 232 k ops/s | 431 k ops/s |
| 32 | 158 k ops/s | 401 k ops/s |
| 48 | 126 k ops/s | 353 k ops/s |
| 64 | 118 k ops/s | 330 k ops/s |
我们将journal算法的性能提高了近三倍,并且几乎完全消除了高线程数下的负伸缩现象(negative scaling),而同时也没有降低低线程数下的性能。WiredTiger团队有一套标准的测试基准(benchmarks),这其中有一些比其它基准获得了更多受益,但没有一个因为这些变化受到损害。
结语
存储层的代码更改其影响通常是不可检测的,因为这会被上面许多层产生的开销所掩盖。像这样有机会获得显著的、用户可见的改进是很罕见的,使这项工作能够带来很强的满足感。
最后,针对一组特定条件进行代码优化不仅仅是细化代码——它还细化了你的思路。当你的想法越来越深入到问题空间时,它们会留下一些痕迹,进而慢慢成为轨迹,最终成为一条路径,然后你的想法会自然而然地形成。因此,当你遇到一种情形需要使代码适应全新环境时,有一个不受你先入为主影响的朋友在旁边会大有帮助。



评论前必须登录!
注册