 MongoDB中文社区
MongoDB中文社区
你无法优化代码;优化是针对特定的条件来实现的。当条件改变时,你的优化反而可能会变为瓶颈。这时仔细审查你对这些条件的假设,其中也许就蕴藏着解决方案的关键。
WiredTiger的WAL(write-ahead log)正说明了这一原则。它是高性能存储引擎中的一个关键代码路径,我曾经对其进行了大量优化以避免I/O和锁。但当WiredTiger成为MongoDB的存储引擎时,我最初所针对的一些条件变得无效了。当我的一位同事在调查一个负伸缩(negative scaling)的案例时发现了测试过程中WAL的一个严重的瓶颈,我们叫它“logjam”。那次调查最终导致我们重新思考我们的假设,并为新的条件进行优化。我们用一个快速的原型验证了新方法,然后涵盖了所有复杂的和边缘的情况以产生一个完整的解决方案。
在这个系列文章的上篇我将深入WiredTiger WAL的内部,展示它是如何在不使用锁的情况下将多个线程的写入编排到单个缓冲区的。我将解释这种设计和新条件之间所遇到的两个冲突是如何导致logjam的。下篇将重点介绍我们如何消除瓶颈。我将分析它发生的根本原因并描述支持我们解决方案的关键,并详细介绍新算法以及它是怎么反映出我们所遇到的新条件。
预写式日志(The write-ahead log)
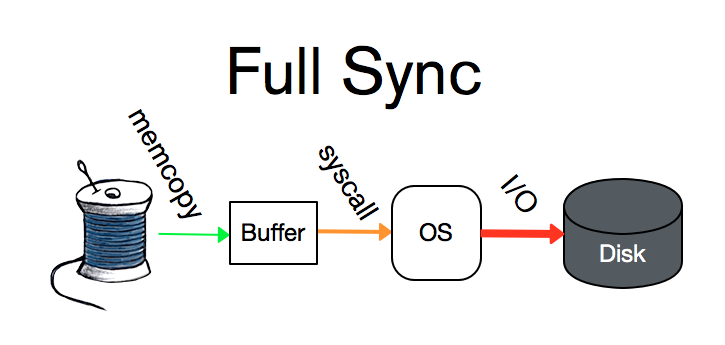
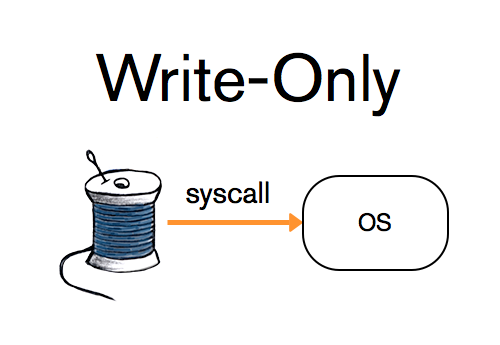
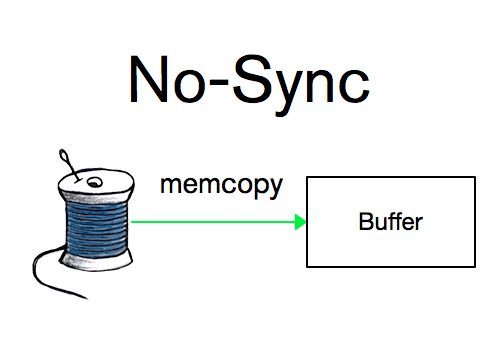
WAL是一种耐久性功能(durability feature), 使得WiredTiger不必担心进程或系统的崩溃。(MongoDB称其为“journal”)。任何将数据写入WiredTiger的线程首先将描述写入操作的记录添加到WAL;一旦发生崩溃,可以从此日志中重放未持久化到存储表的记录。WAL提供三种耐久性模式。最严格的是“full-sync”,保证在返回之前将记录刷新到磁盘, 从而使数据能够在系统级别的崩溃中幸存下来。第二个级别是“write-only”,保证记录写入操作系统的文件中, 然后返回给用户, 允许数据在进程级别的崩溃后仍然幸存。最后是“no-sync”,即将记录保存在内存的缓冲区中, 但不保证将其立即写入文件系统。
传统的WAL使用互斥体来协调多线程的写入,这在单核架构上可以很好地工作。但在多核架构中,这就浪费了大量的时间使线程等待互斥体。为了让WAL更好的实现并行化,我参考了《Very Large Databases Journal》中了一篇研究论文“Scalability of write-ahead logging on multicore and multisocket hardware”。这里线程并不对写操作进行同步,也不按照线程独立进行写操作,而是将其记录复制到单个的内存缓冲区中,该缓冲区可以在一次调用中写入文件系统。线程仍需等待所需的耐久性级别才能返回,但WAL的总体吞吐量提高了,因为每个线程不会进行自己的系统调用。
相对于互斥体,原子操作提供了对写入的隔离,允许所有线程在不会锁定的情况下运行。但这种设计不能和控制对内存缓冲区访问的互斥体一起使用,那样只是在调用栈的不同层面重新引入了竞争。
传统的WAL也不能提供no-sync模式,但由于WiredTiger已经将写入整合到了内存中,因此这种能力本身就已经具备了。它只是让线程返回,而无需等待其写入或同步。这样,一组逻辑上相关的写入操作就可以更快地运行:客户端代码可以先用no-sync模式进行其余调用,然后再使用write-only或full-sync模式发出最后一个进行收尾。
麻烦初现
2015年夏天,MongoDB高级技术服务工程师Bruce Lucas正在进行让WiredTiger作为MongoDB 3.2版默认存储引擎的工作。Bruce需要拥有深入且高度专业的MongoDB知识来支持客户,为此他正在进行实验以研究WiredTiger在各种情况下的表现。其中一个实验是由许多小的插入组成的工作负载,每个核都会有大量的线程。他在其中发现了一个负伸缩(negative scaling)的问题。
以下是在8核AWS Linux上运行MongoDB 3.0.4中WiredTiger代码的结果:
| threads | k ops/sec |
|---|---|
| 8 | 278 |
| 16 | 379 |
| 24 | 232 |
| 32 | 158 |
| 48 | 126 |
| 64 | 118 |
使用“Poor Man’s Profiler”(它定期调用gdb来获取所有线程的完整堆栈跟踪),Bruce找到了瓶颈所在——WiredTiger WAL中的忙等待(busy-waits)。随着继续深入,他发现了WAL的设计中不适合作为MongoDB存储引擎的两个地方。
不匹配条件1:耐久性级别(durability level)
在我最初设计WAL的时候,WiredTiger还不是MongoDB的一部分。那时我假设大多数使用WAL的应用程序都使用write-only模式,可能有些会使用full-sync。这对于当时直接使用WiredTiger库作为键值存储的客户来说是典型用例。
然而,MongoDB正是这样一种系统——它可以受益于先发出一系列有关联的no-sync写入,并以一个full-sync写入结束。WiredTiger通过表中的键/值对来构造数据,这些表是MongoDB所有数据结构的基础——集合、oplog、索引和各种内部的MongoDB元数据都是WiredTiger表。对MongoDB文档的单次写入会导致对多个WiredTiger表的多次写入调用。从客户端的角度来看,必须所有的写入都完成持久化,否则就没有意义。所以即使对MongoDB的调用指定了在写操作返回之前必须将journal同步到磁盘上,MongoBD也可以对除最后一次之外的所有调用使用高效的no-sync模式。这使得“no-sync”成为目前最常见的情况。
深入研究:WiredTiger的log slot
现在,大量的no-sync调用将WiredTiger对写入的整合机制推到了台前,其核心是一种称为“slot”的数据结构(研究论文中的术语)。slot封装了内存缓冲区、相关元数据和一个称为“slot_state”的特殊int64_t字段,该字段统计缓冲区中声明占用的字节数。我们将slot_state的低位保留为内部状态值使用,而高位则称为“READY”。线程首先连接一个READY状态的slot,通过在slot_state上一个原子操作在其缓冲区上声明一个点(spot)。当slot对后续的连接关闭时,它们会进行数据的复制操作并通过在slot_state上的另一个原子操作来释放它们的占用声明。
WiredTiger维护了一个slot池。若要将记录写入log,线程将尝试连接当前处于READY状态的活动slot。第一步是通过对slot_state添加记录的大小来确定剩余的缓冲区空间是否足够。如果够用,线程将通过一个原子的CAS(compare-and-swap)操作对slot_state更新总大小。当操作成功时,slot_state的先前值指示的是该线程在缓冲区中的偏移量,而新值反映的是下一个要连接线程的正确偏移量(或该缓冲区的最终大小)。
注意此时线程还未真正写入数据!必须等到slot关闭对其它线程的连接,才会在相关联预定的地方执行这些写操作(这个工作会由一个leader线程来完成,后文会说明)。所以现在,它只是在等待并监视slot_state,等待其关闭的指示。
如果一个线程获得的偏移量为零,那么它就会成为leader线程。leader线程不会坐等slot关闭,相反它会去关闭slot。但首先,它要从池中准备一个新的slot,以确保可以为后续的连接和写入操作做好准备。在整个过程中,这是一个会用到锁的地方。当这个过程结束时,leader会使用一个原子操作来反置slot_state的符号。负的slot_state表示slot对后续的其它连接已经关闭,这正是其它写入线程正在等待的信号。它们已经知道自己的数据在缓冲区中的位置,因而可以并行地进行复制。完成任务后,它们通过原子地将记录大小添加到slot_state来释放slot,该值现在是一个负数,它指代剩余的要复制到缓冲区的总字节数。当slot_state变为零时,所有复制均已完成,该slot已完全准备好写入操作系统了。最后那个释放slot的线程会看到这个零值,并负责将缓冲区写入操作系统。而这对其它线程完全没有影响,它们早已继续它们愉快的旅程去了。
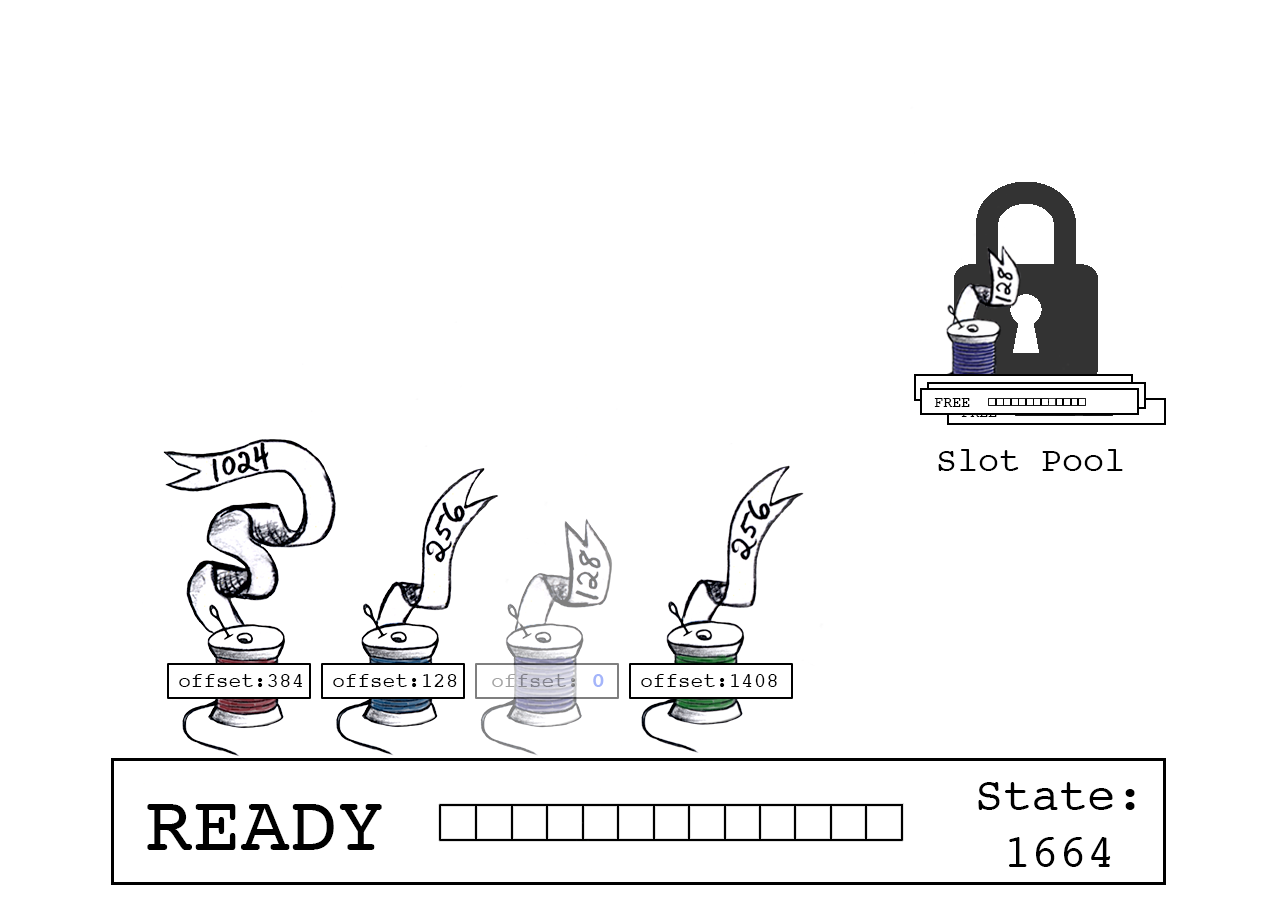
一个slot正处于READY状态并等待连接线程。一个空闲的slot池既没有被使用也不处于READY状态中等待被连接。
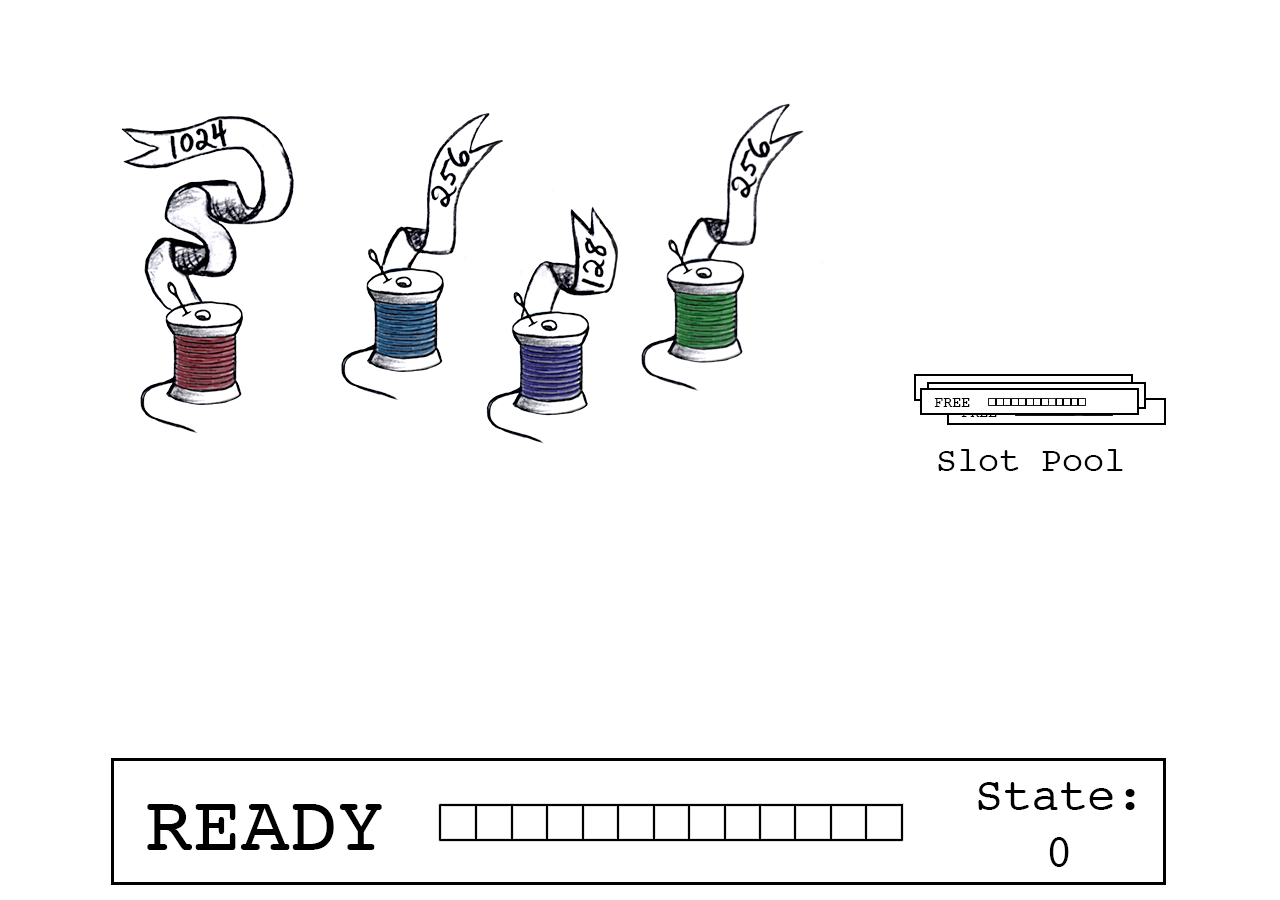
紫色线程开始连接,在缓冲区中请求128字节的空间。
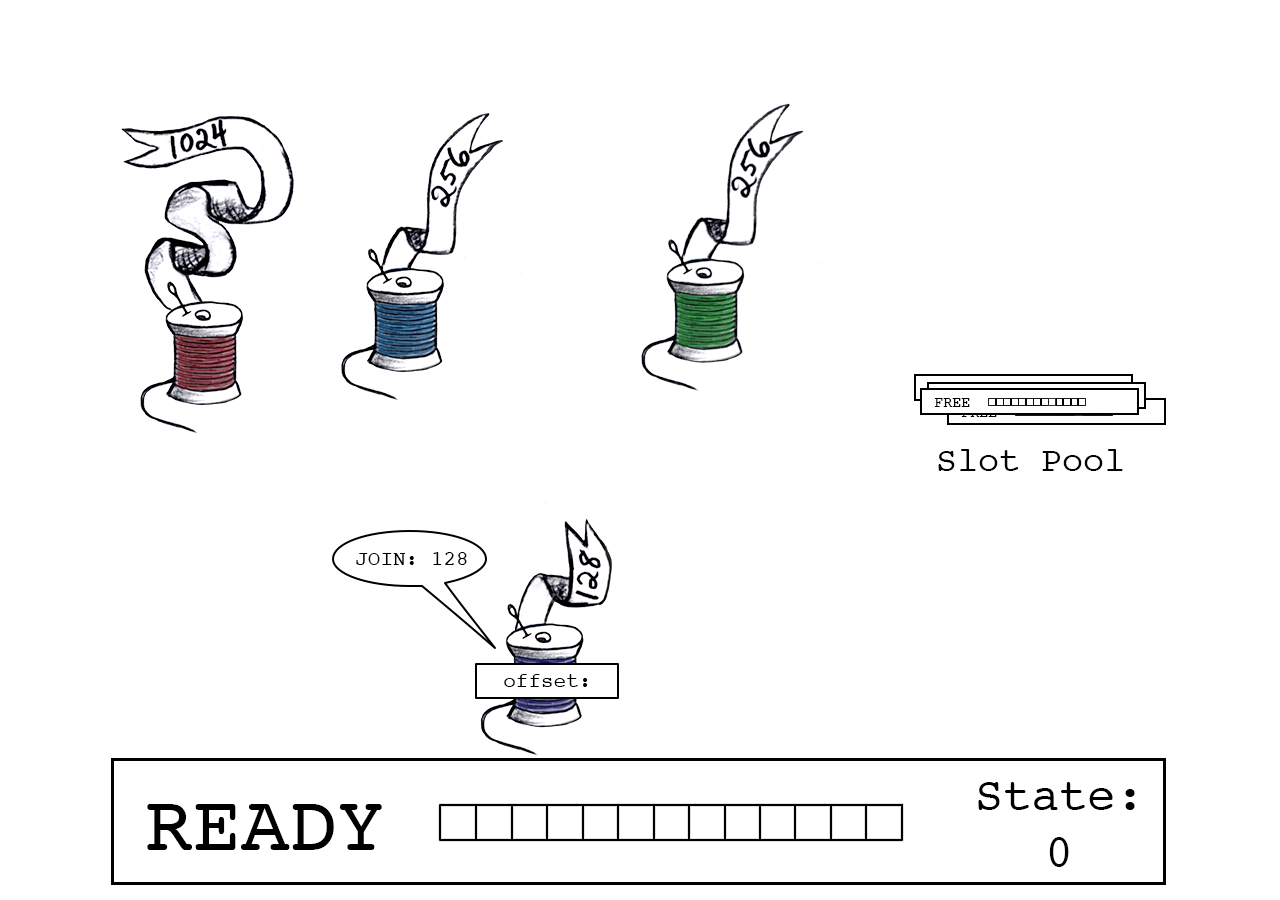
Join total是slot_state(0)和紫色线程数据大小(128)的总和。

CAS原子操作确保只有在slot_state自紫色线程读取以来保持不变的情况下连接才会成功。

成功:紫色线程声明偏移量“0”,slot_state现在指向下一个可用字节(128)。
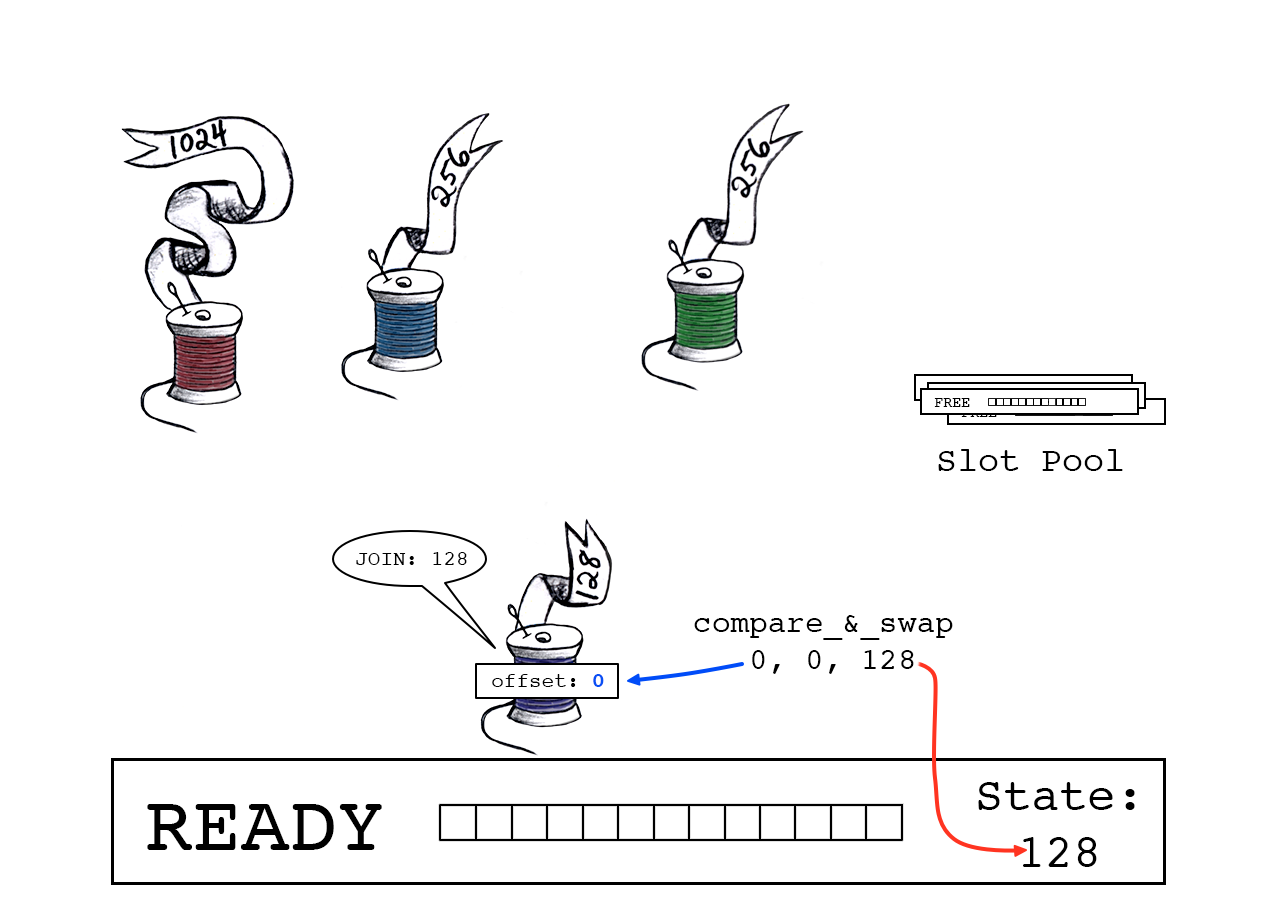
offset == 0 表示紫色线负责准备下一个slot。
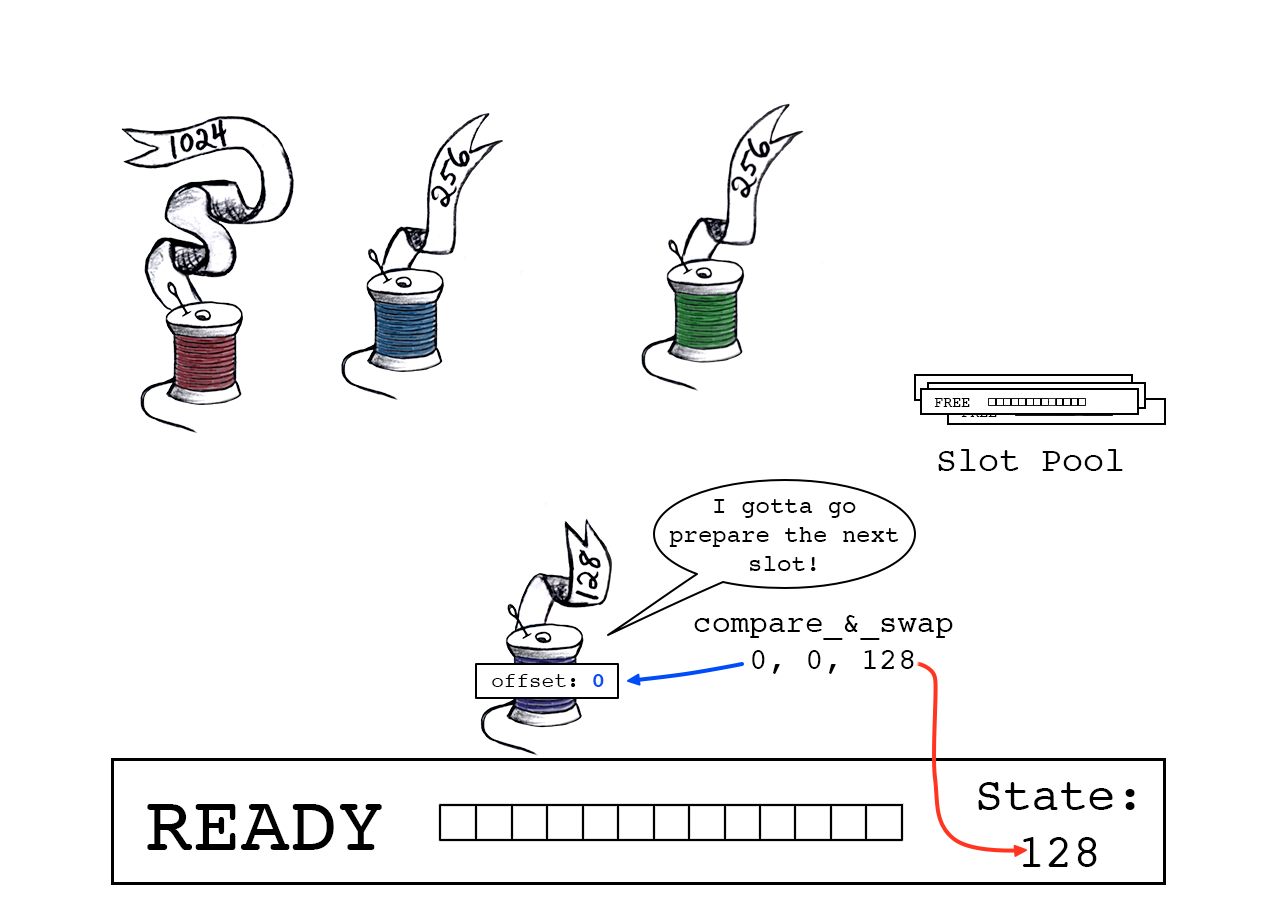
紫色线程对一个互斥体上锁以保护slot池。
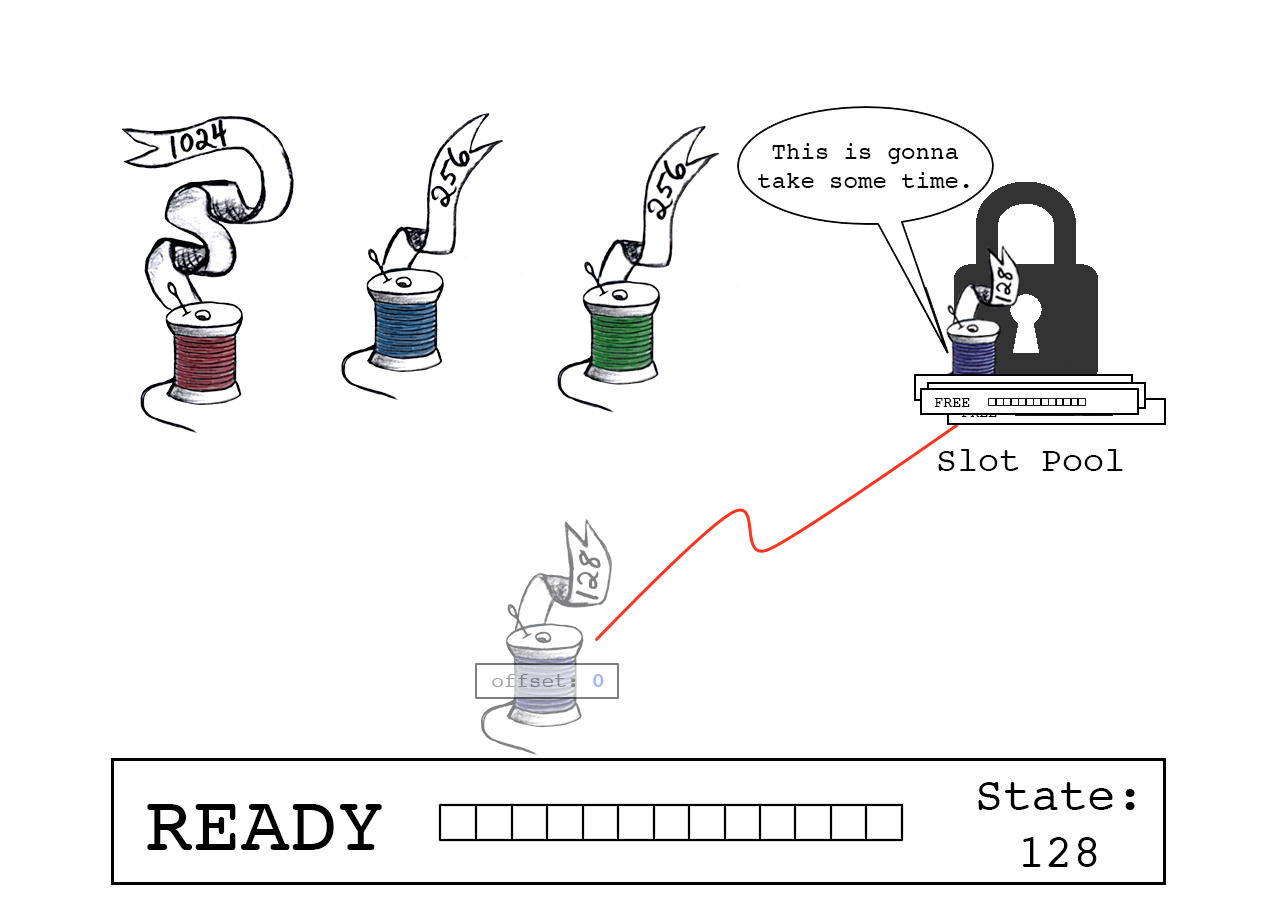
蓝色线程尝试连接,向缓冲区中请求256个字节。
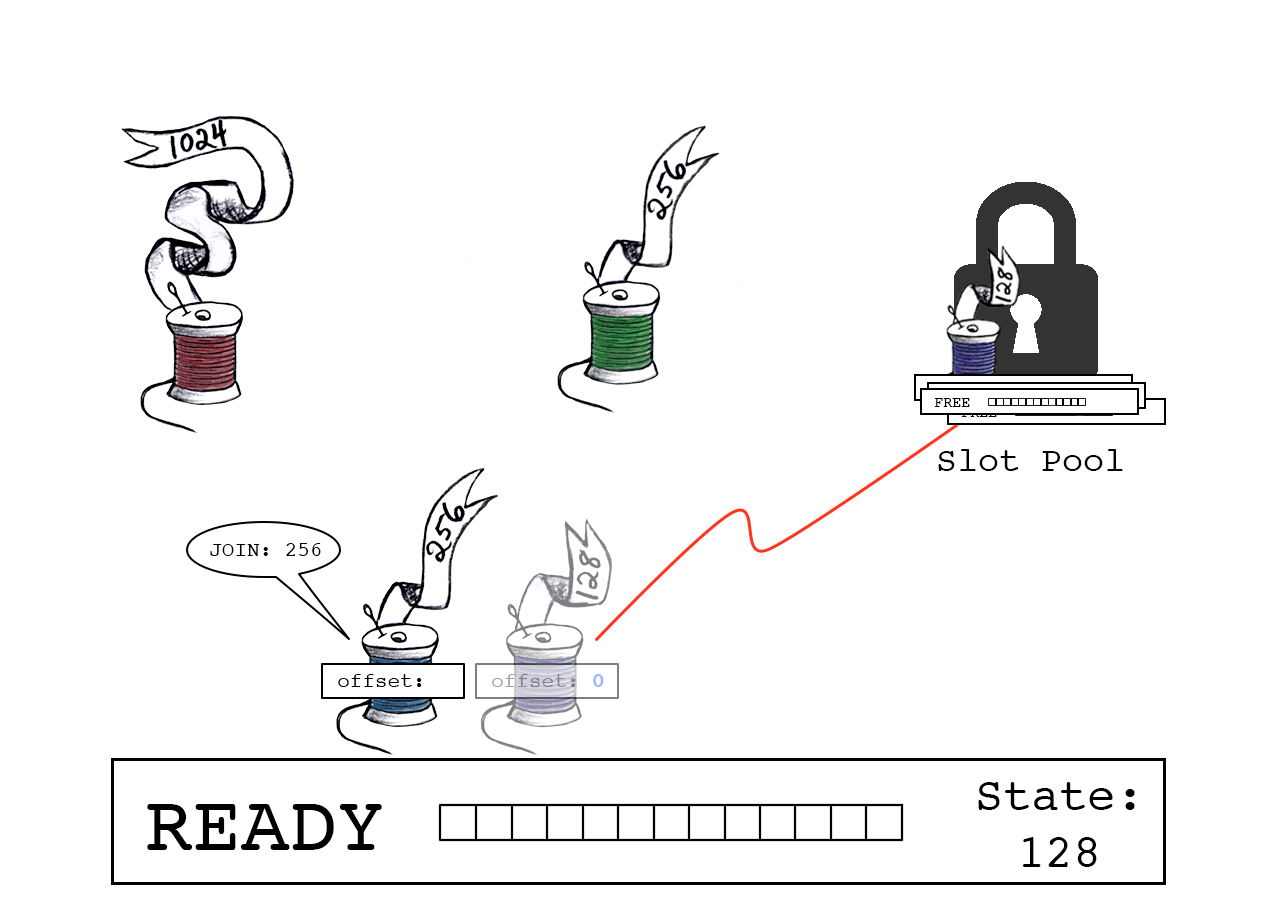
Join total是slot_state(128)和蓝色线程数据大小(256)的总和。

CAS原子操作确保old_state依然有效。
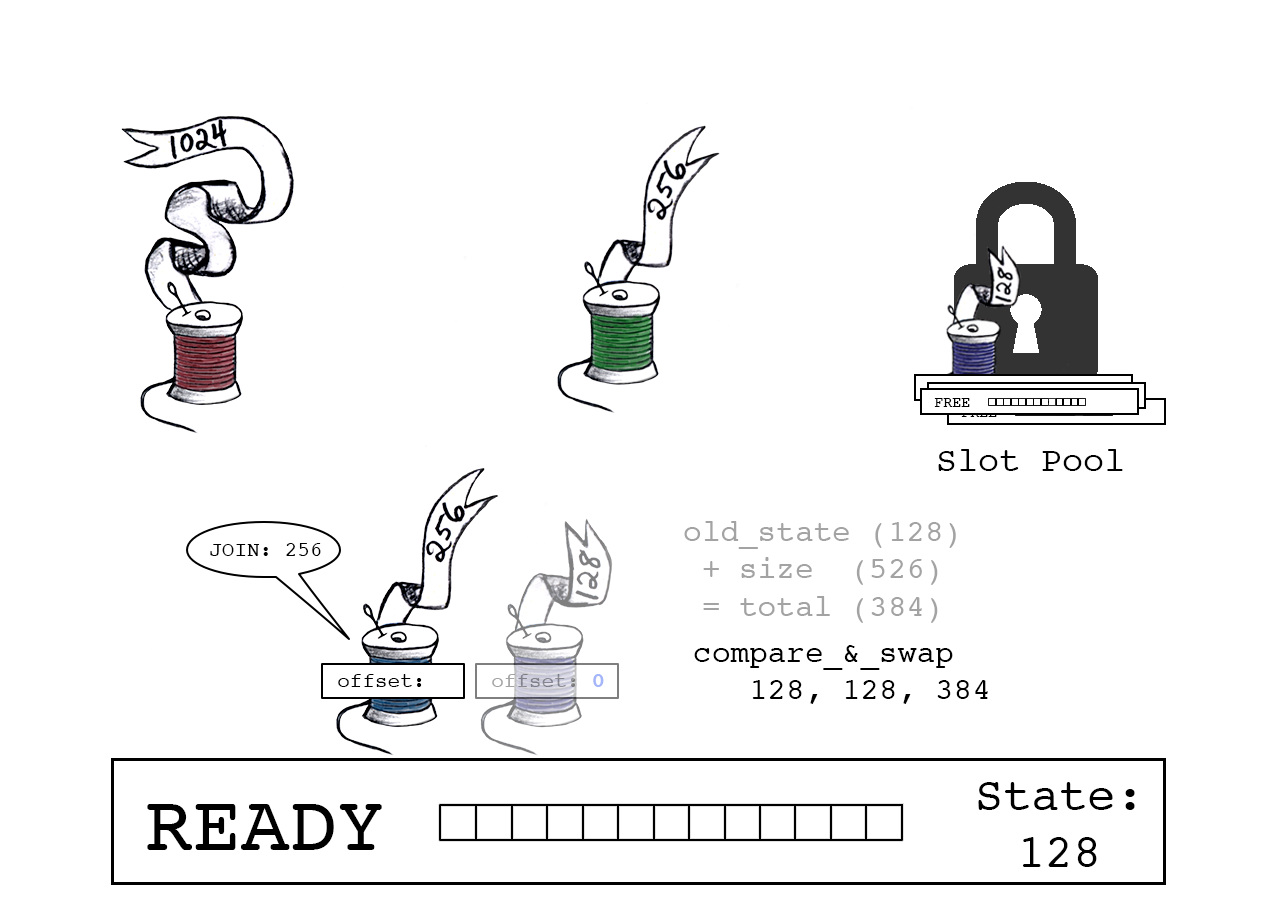
成功:蓝色线程声明偏移量“128”,slot_state现在指向下一个可用字节(384)。

同时,紫色线程继续准备下一个slot。
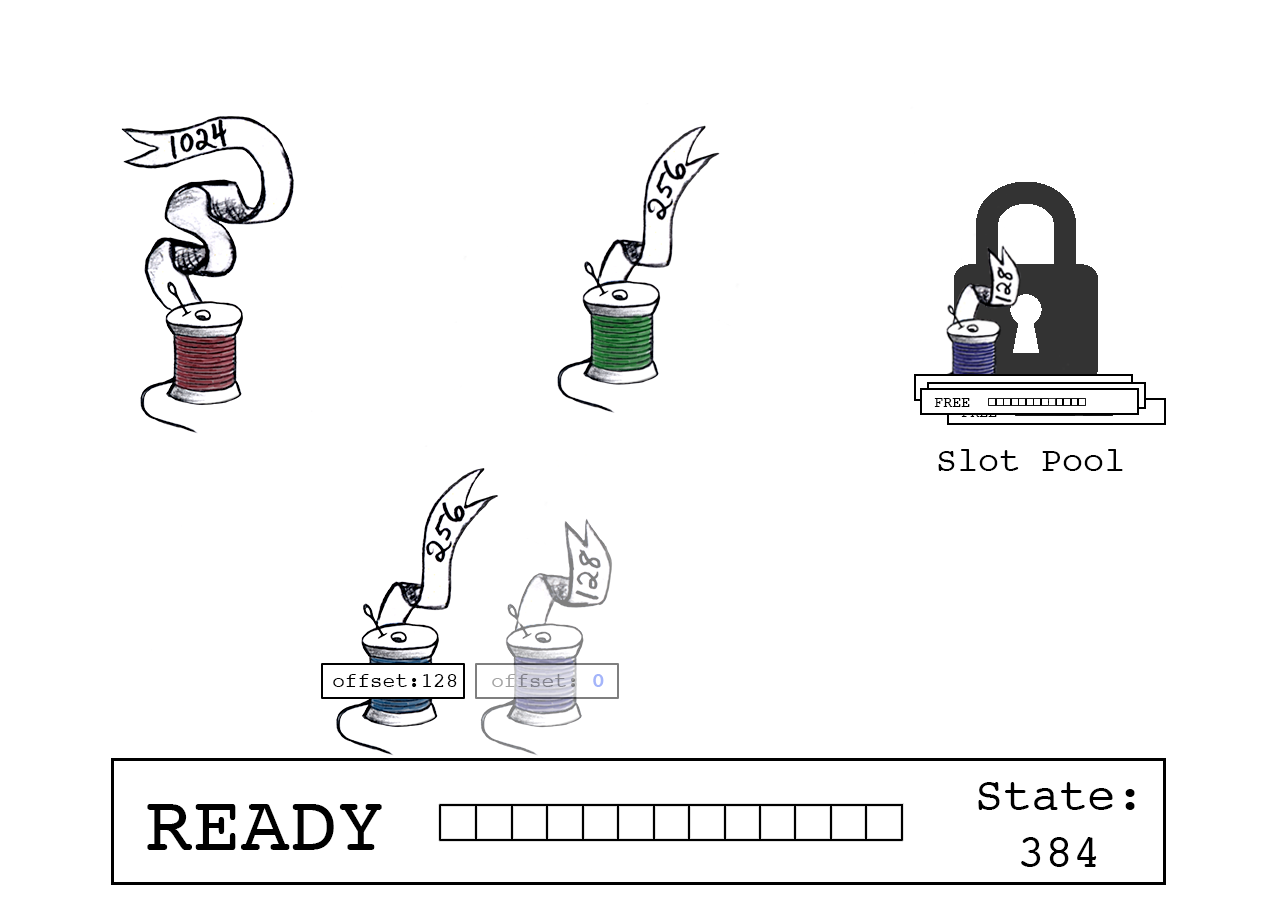
红色线程尝试连接,它有1024字节数据。

成功:红色线程声明偏移量“384”,slot_state现在指向下一个可用字节(1408)。

绿色线程尝试连接,它有256字节数据。
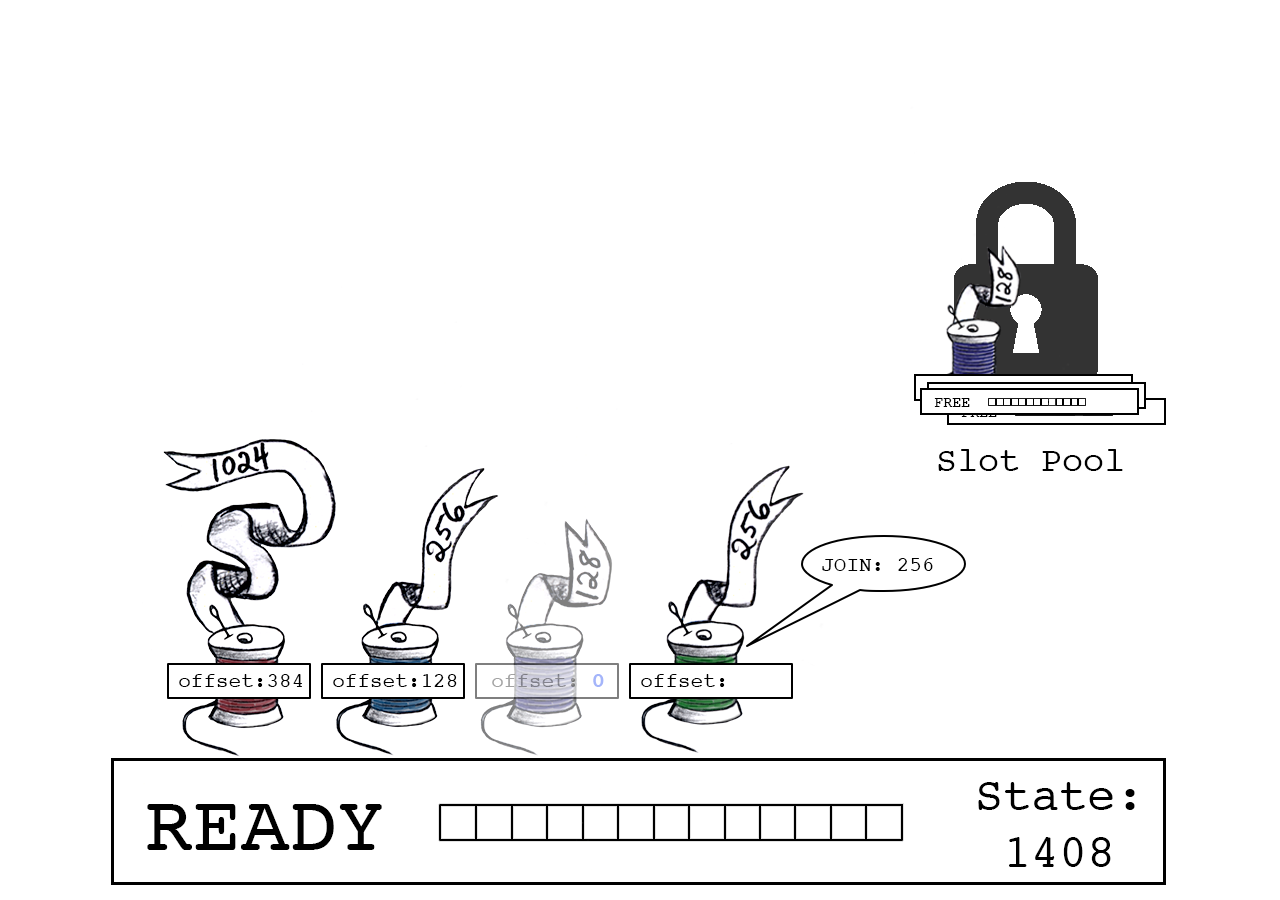
成功:绿色线程声明偏移量“1408”,slot_state现在指向下一个可用字节(1664)。
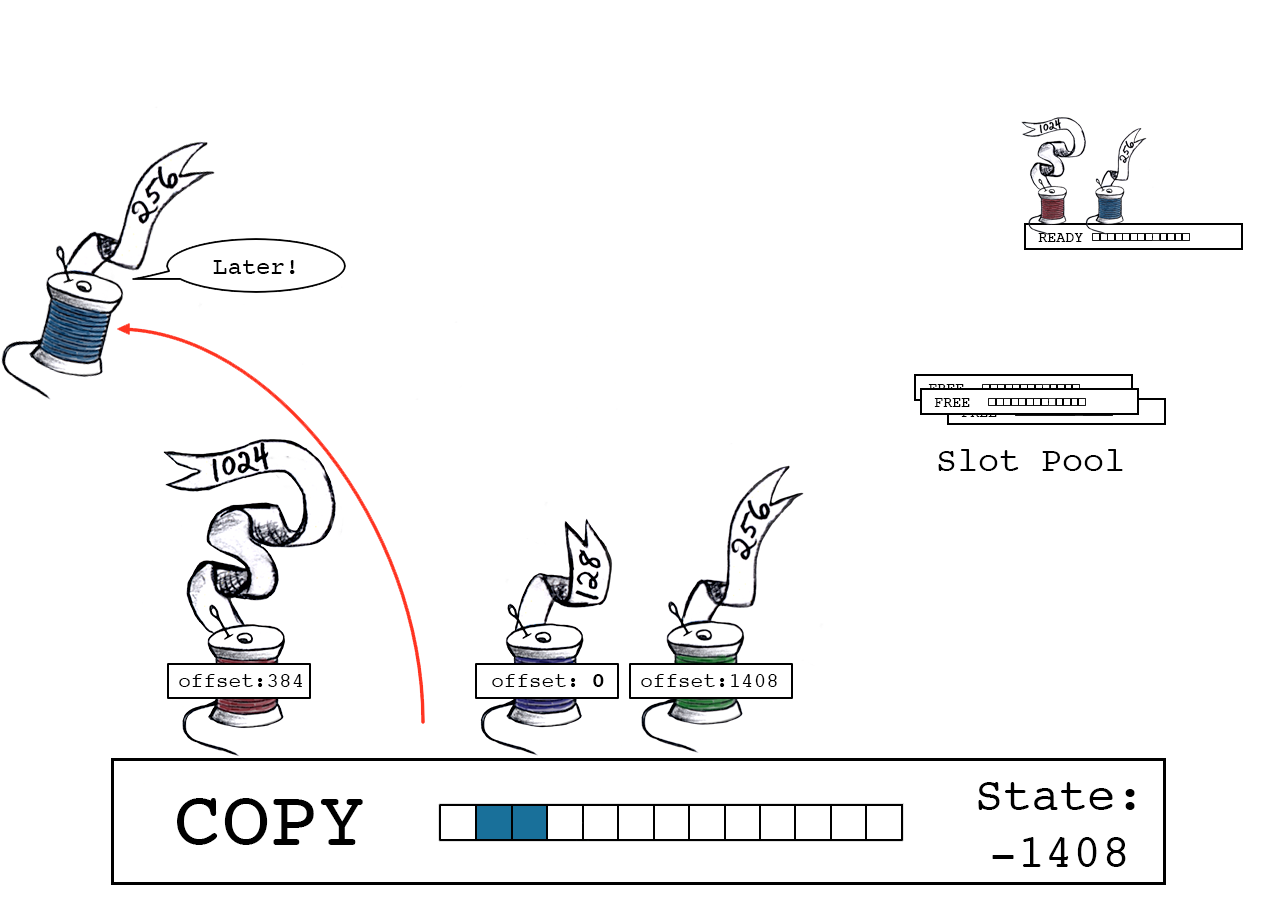
紫色线程完成对下一个slot的准备。

紫色线程将新slot设置为READY状态;而对当前的slot,会通过反转其符号来标识它处于COPY状态。

紫色线程解锁slot池。已连接的线程可以并行进行复制操作(但为了清晰起见,这些数字将一次一个的显示)。

蓝色线程将其256字节复制到偏移量128的位置。同时,其它线程连接新的READY状态的slot。

蓝色线程释放,使用原子操作将它的大小添加至(负值的)slot_state。

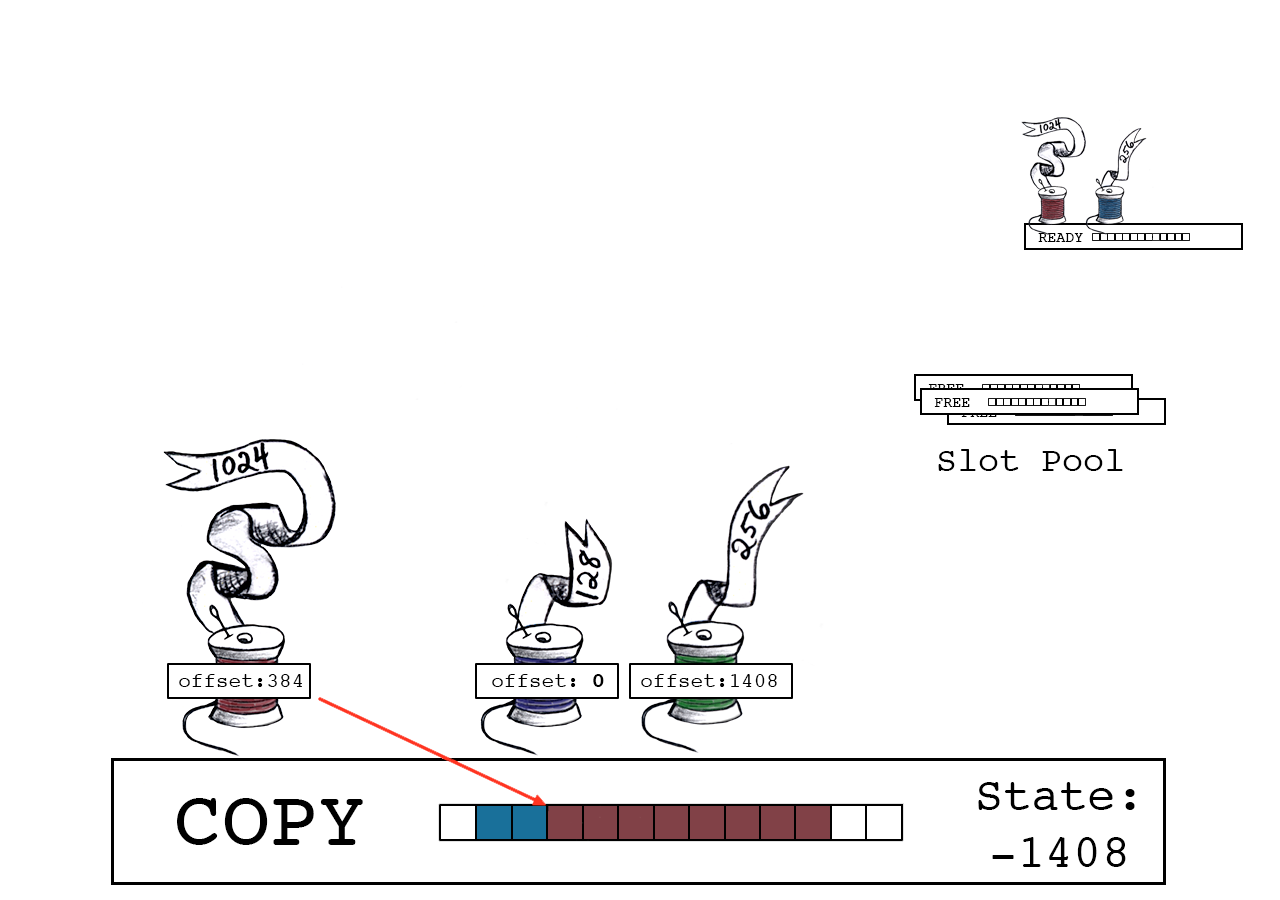
红色线程将其1024字节复制到偏移量384的位置。
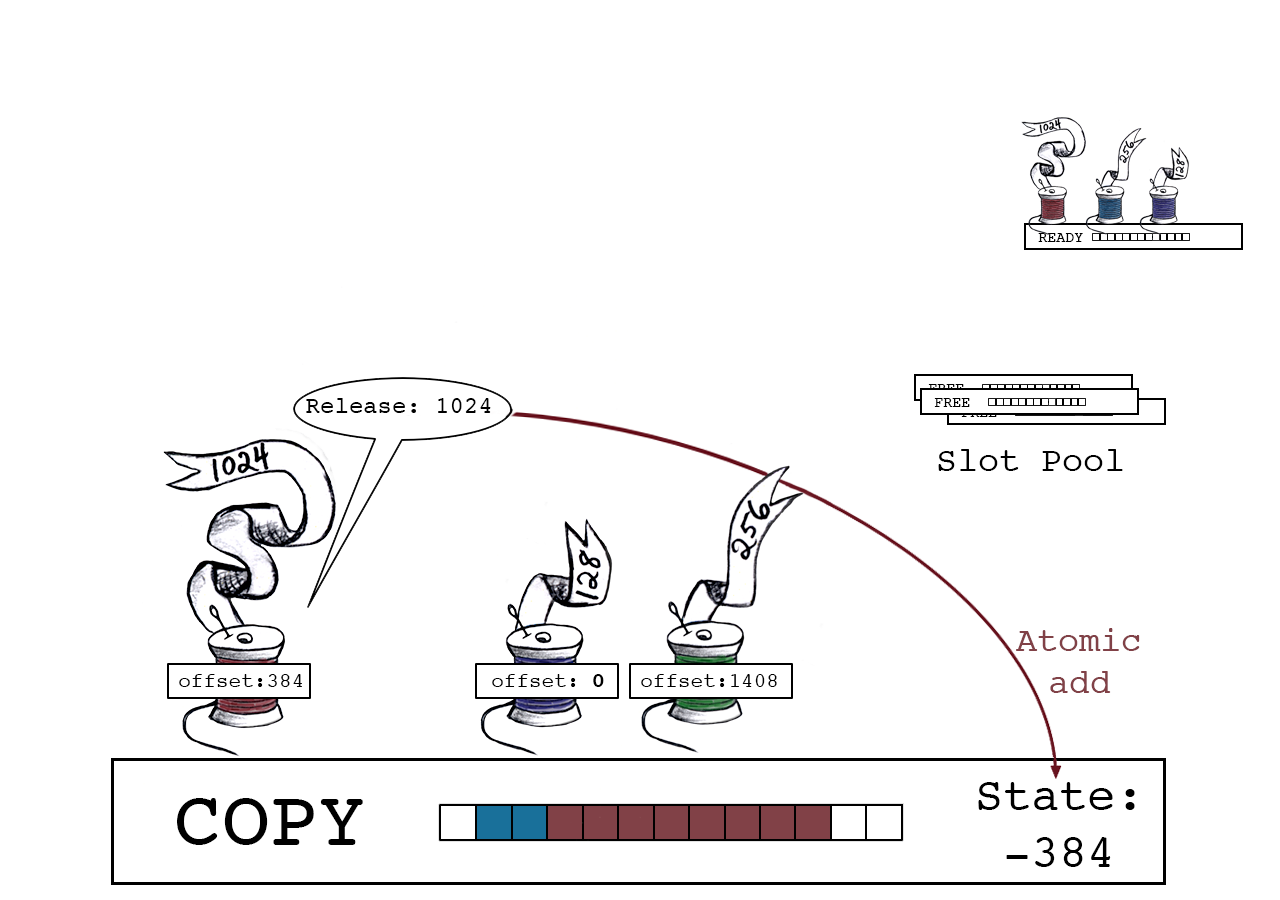
红色线程释放,使用原子操作将它的大小添加至slot_state。
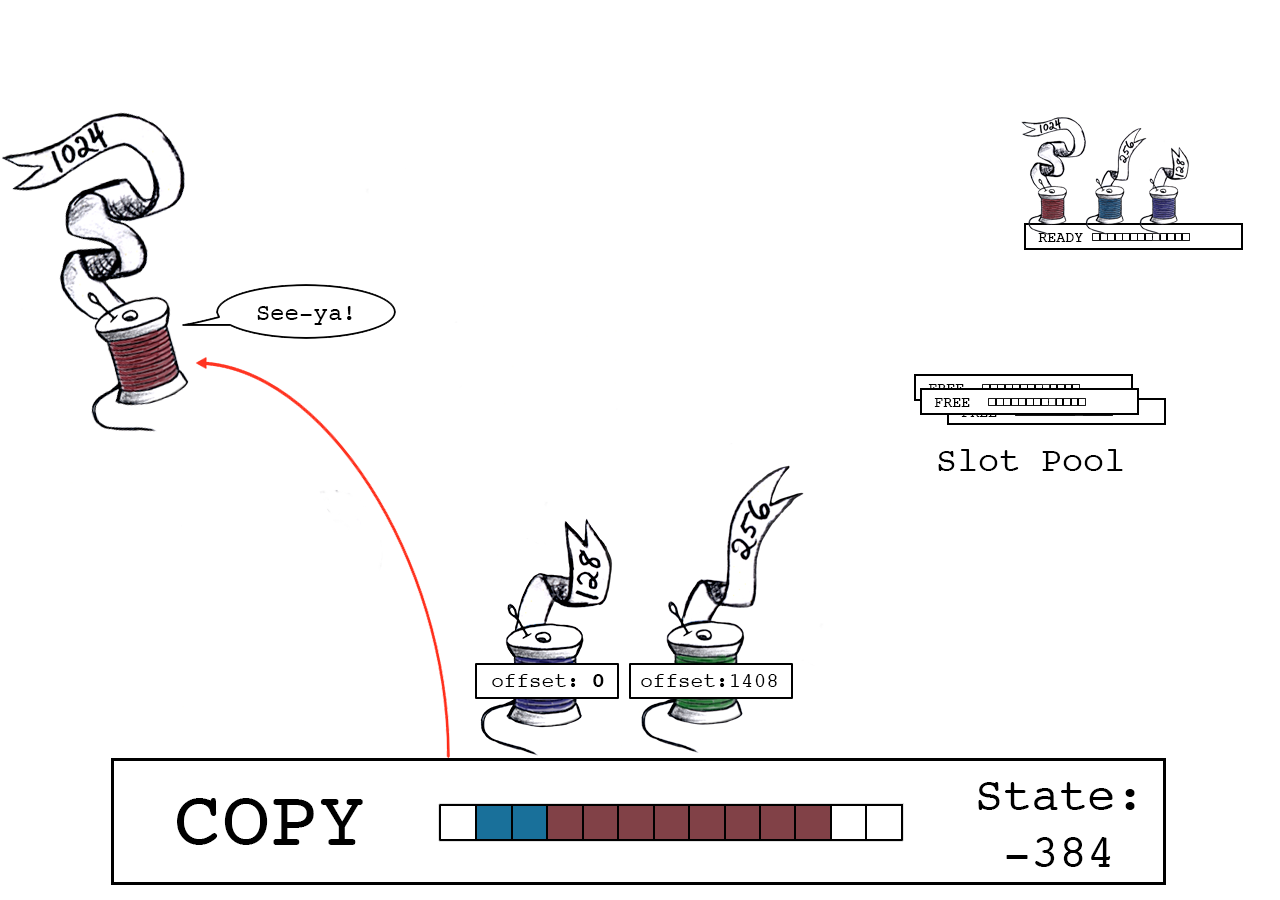
紫色线程将其数据复制到偏移量0的位置。
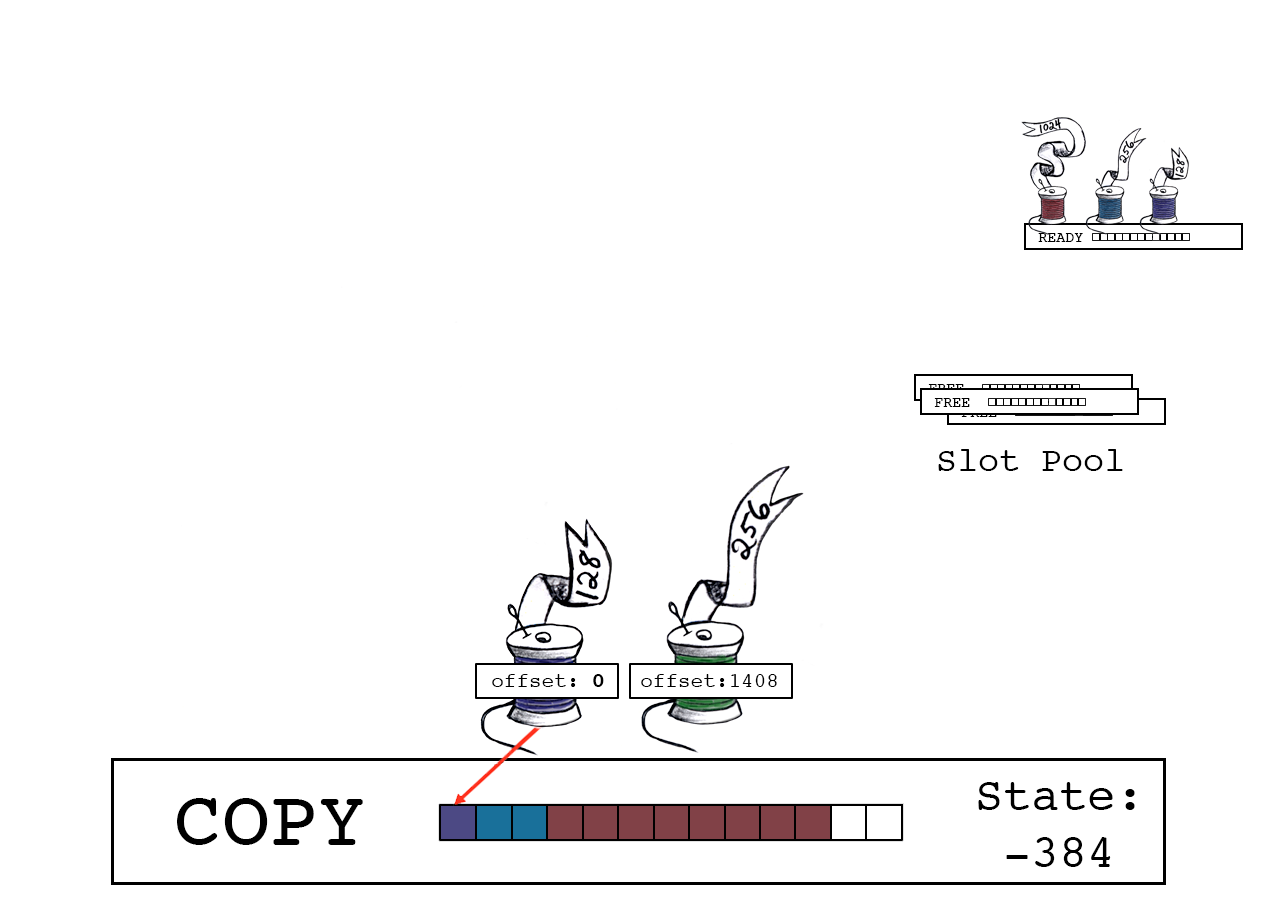
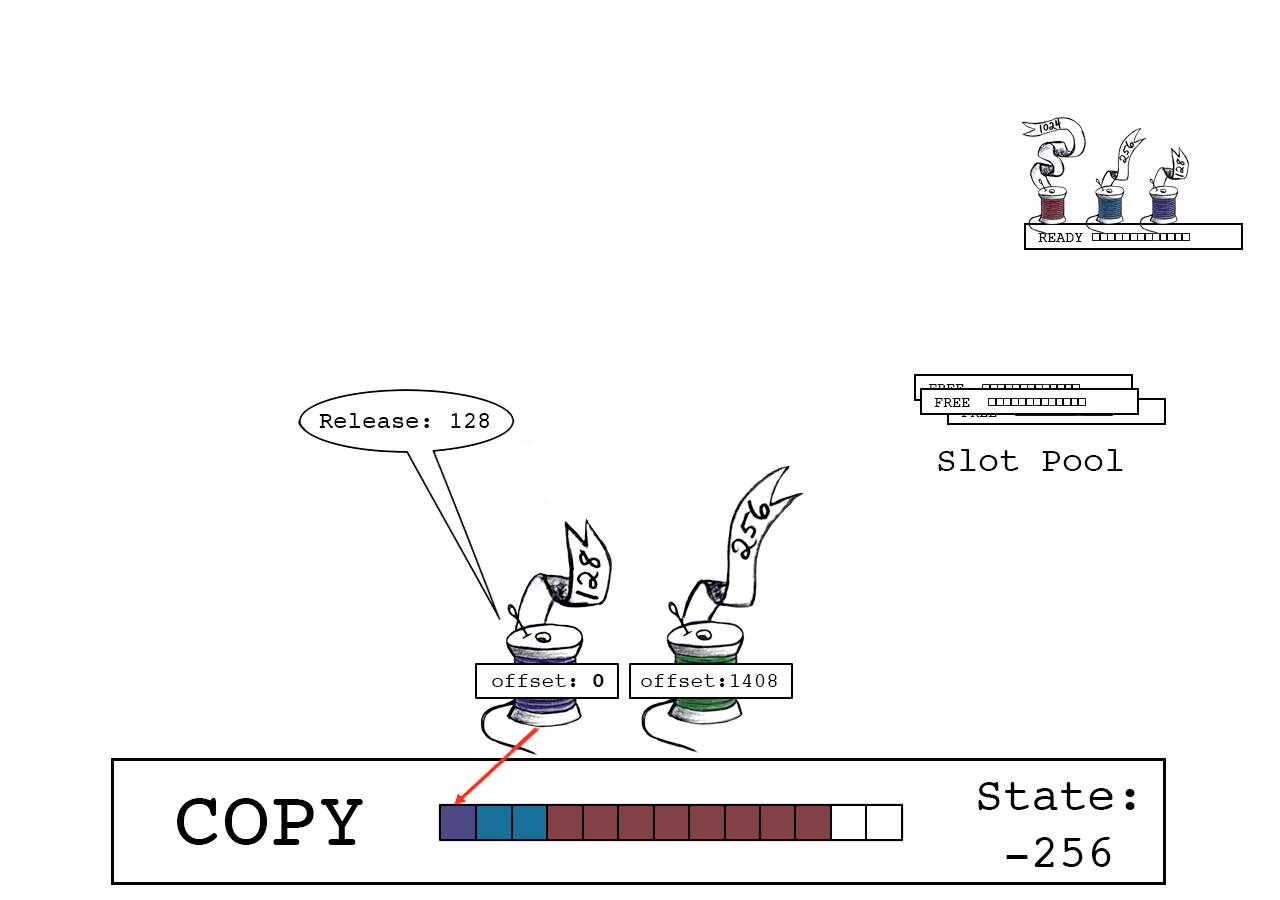
紫色线程释放,将slot_state变为-256。
绿色线程将其数据复制到偏移量1408的位置。
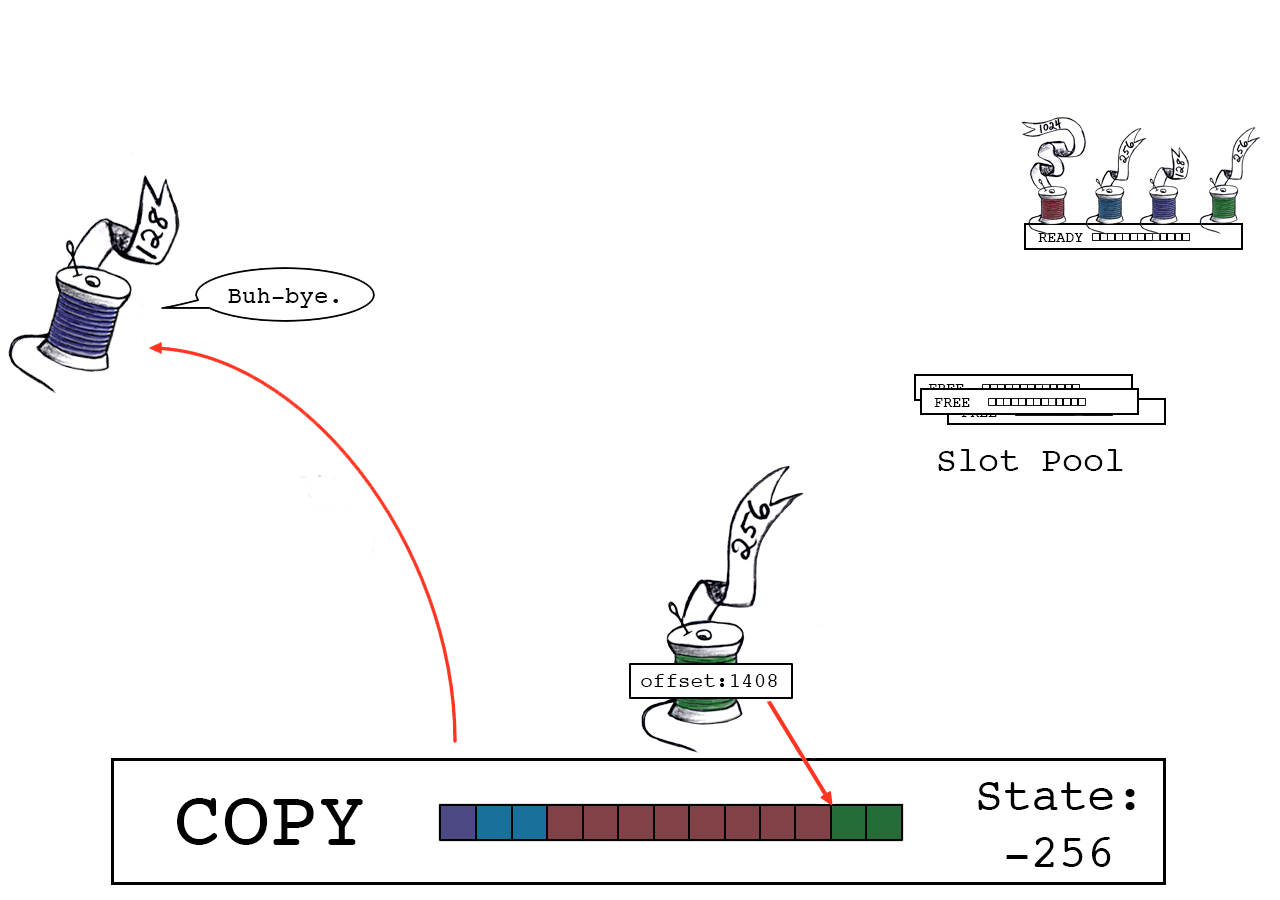
绿色线程释放,将slot_state变为0,这意味着其处于“DONE”状态。

slot_state == 0 说明绿色线程是最后一个释放的线程。

绿色线程将slot缓冲区写入操作系统。完工!

不匹配条件2:线程数量大概与核数差不多
原始的算法很优雅并且工作得很好……只要每个核的线程不太多。这是我在最初设计中所做的另一个假设,基于这样的预期:WiredTiger将被嵌入到专门的应用中,而不是一个通用数据库中。
对于那些等待将记录复制到缓冲区的线程来说,核的可用性是很重要的,因为它们必须忙等待(busy-wait)slot_state更改,而这会消耗CPU周期。因为我预期状态会很快更新,并且有足够的CPU可供检查,忙等待是安全的(在我完成这个设计的时候)。但是MongoDB对每个客户端连接使用不同的线程。有些工作负载,比如那些执行大量微小的写入操作,会创造出比核数多得多的线程。
瓶颈
单独而言,任何一个条件不匹配都不会造成灾难。但是在有大量线程和很少的核的情况下,当大多数线程忙于等待状态更新时,我们会得到一个经典的优先级反置(priority inversion)案例。负责管理slot_state和slot池的线程应该是优先级最高的,但是所有加入slot并等待slot_state更改的线程已经使CPU不堪重负。这些线程确实调用了sched_yield,但这对Linux的调度器没有太大帮助。
敬请期待全新的方法
我们不能将其替换为互斥体,因为这样会严重影响任务的性能。我们需要考虑基于这些新条件的新优化方式。最后是Bruce打破了僵局。当我还在现有代码的框架内进行优化时,Bruce跳出框架并进行了试验。他没有受原始设计的影响,尝试了一种完全不同的方法。他提出了一个独立的原型,有希望对“no-sync”带来巨大的改进。这个方案极其简单——它甚至没有使用任何MongoDB或WiredTiger代码——但它是如此激动人心,以至于我不得不去尝试一下。
继续我们的旅程,让我们在下篇中打破logjam!



评论前必须登录!
注册