 MongoDB中文社区
MongoDB中文社区
前言
在上一篇文章事务与复制的几种实现模式中对事务与复制的一些问题进行了抽象的描述,本文将针对MongoDB数据库,对这些问题进行更加深入的探讨。事务和复制对于很多数据库来说是共性,但每一种数据库在这两个问题的细节之处都会有各自的考量,带来了各自的特性;围绕着对共性和特性的讨论,我们将得以还原设计的权衡与思量。
本文若不做特别说明,均以MongoDB4.0为例。需要注意的是,MongoDB在3.0后续的版本均有较大的更新,版本差异较大,这里无法一言蔽之,还请见谅。
Overview
针对不了解MongoDB的读者,这里先简单介绍下MongoDB是什么。
MongoDB是一个基于文档模型的,支持索引、复制、事务、分片水平扩展的数据库:
– 完整的索引支持,普通索引,复合索引,唯一索引,TTL索引,部分索引等等
– 复制协议类似Raft,但针对数据库的场景做了很大程度的改造;具备自动Failover、复制、Arbiter节点、NonVoting节点等能力
– 事务能力在4.0版本开始提供,目前仅在复制集的场景下支持,4.2版本将支持分布式事务
– 水平扩展基于Sharding,支持hash或者range进行分片,对用户透明
可以说,除了查询语言不是SQL以外,基本算得上是一个正经的NewSQL了。
首先是事务
首先是整个讨论的前提,MongoDB支持事务吗,它需要事务吗?
对于用户来说,在4.0版本之前,并没有事务的概念,MongoDB仅能保证单行操作的原子执行。在4.0的版本才有了事务支持,用户能够像传统的关系数据库一样,显式地begin, commit, abort事务。
但早在此之前,MongoDB在数据库内部其实已经支持了事务,其存储引擎WiredTiger本身也是一个优秀的事务引擎:
为什么需要事务
为何需要事务,我们先来考虑这个问题。
对于用户的一条insert({uid: 123, name: "wang"})操作来说,MongoDB需要做几件事情:
– 把{name: "wang"}写到KV存储引擎里,这时候会生成一个RecordId作为key,变成1 => {uid: 123, name: "wang"}
– 除此之外,每个文档默认会添加一个全局唯一的_id字段,这个字段也会写一条索引:_id: abcd => 1,由id指向RecordId
– 用户在uid建立了唯一索引,在name字段创建了非唯一索引;因此在存储引擎里还要写两条索引,uid: 123 => 1,name: wang => 1
– 不过没这么简单,uid是唯一索引,我们需要先检查这个key是否重复,所以需要先读一下索引是否存在,已经存在的话要返回异常
– name字段是非唯一索引,存储时需要在key上增加一个Record作为后缀:变成name: wang/1 => typeBits;把RecordId放到key里,Value不存储位置
| Key | Value |
|---|---|
| 1 | {_id: abcd, uid: 123, name: "wang"} |
| index_id: abcd | 1 |
| index_uid: 123 | 1 |
| index_name: wang/1 | 1 |
也就是说,一条insert会变成多次KV存储引擎的读写;除此之外,其他的update、findAndModify等很多操作,事实上都是需要多次对存储引擎的读写操作的。由于一次用户更新会变成多次存储引擎的读写操作,显然是需要事务的支持,才能够保证索引和数据是一致的,否则会发生读到错误数据的情况。
单行事务&多行事务
而这里的事务,是不能用类似RocksDB里的WriteBatch + Snapshot替代的,因为缺乏冲突检测机制,做不到真正的隔离。
MongoDB的事务能力由WiredTiger提供,它是一个基于B+tree的,实现了Snapshot Isolation的事务引擎。在功能上,可以类比RocksDB的TransactionDB;但性能上,它们会在不同的workload下有不同的表现。
上面说的这种,用户发起一个单行的更新请求,称之为单行事务;而在4.0中用户可以进行交互式的事务,将多个操作放到一个事务中,获得ACID的能力。从实现的层面来看,它们的区别无非是一个由用户开启和提交,一个是自动在每一次请求中开启和提交。至于为何拖延到4.0才提供出来,其实主要在于分布式事务的实现差异。
在分布式事务的场景下,需要实现2PC,需要全局的Snapshot Isolation,需要一个分布式的时间戳方案;而同时要保证事务的性能不会下降,并非易事。因此直到接下来的4.2版本,才会有分布式事务的支持。至于具体采用哪种方案,还是可以期待一下;目前所了解到的是,它们的方案会区别于现有的分布式数据库。
复制
复制是分布式系统逃不开的话题,MongoDB也不例外。
RSM
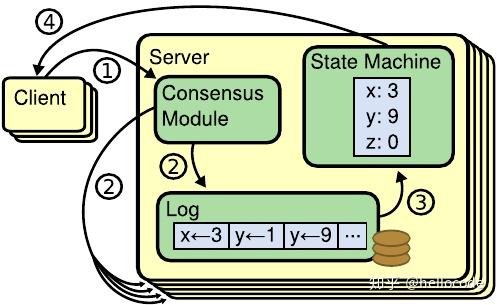
不过在讨论MongoDB的事务之前,我们先来看一下传统的RSM,这里以Raft为例(假定读者对Raft有基本的理解)。讨论Raft时,我们往往会从这几个角度考虑:
– 选主:Raft在选主的时候通过Majority Vote保证Leader Competeness,即选出来的Leader会持有所有Committed的Log
– 复制:Raft通过AppendEntries向Follower复制数据,这里会维护一个连续的Log,复制的时候带上prevIndex和prevTerm来校验日志的连续性
– Commit:raft通过维护一个commitIndex来维护log的commit状态,暗示了Log是串行Commit的
– 状态机Apply:当一个LogEntry Committed之后,即可Apply到状态机;raft维护了一个lastApplied,暗示了串行Apply
– 请求处理流程:结合上面的流程,一个请求会经历复制、Leader和Follower并行写Log、Commit、Apply这样的流程
关于Raft的基本原理差不多就这样,在实现的时候,还有另外一些点需要考虑:
– Checkpoint:Log不能无限增长,否则占据无限的磁盘空间以及Recovery时需要回放大量的日志,因此需要对状态机做Checkpoint
– 两个Log:状态机如果是一个存储引擎,往往还会带有自己的WAL,那么这里显然就造成了IO的放大;出于性能考虑可以去掉状态机的WAL,依赖Checkpoint来实现粗粒度的持久化
– 乱序Commit:按照经典的Raft是不能乱序Commit的,否则如何选主,如何保证Leader Completeness,Log Append-Only等性质;但现实场景中,如果不能乱序,则很有可能会增加排队延迟
– 乱序Apply:这里的状态机可能是一个复杂度不亚于Raft的东西,仅仅是串行Apply整个复制组内的吞吐会受限;能否用多个复制组?或者并发Apply
– ReadOnly 优化:如果不做任何优化,只读操作也需要走一次复制,即便是在Leader节点;因为网络分区的情况下旧的Leader会读到过期的数据;现在比较常见的做法是,用ReadIndex或者Lease的方法来进行优化,省去复制的IO
MongoDB的复制
MongoDB的复制协议在很多地方和Raft很像,但更多的地方它们大相径庭。首先面临一个问题,原本的单机事务引擎没有可以用于复制的日志,如何实现复制?
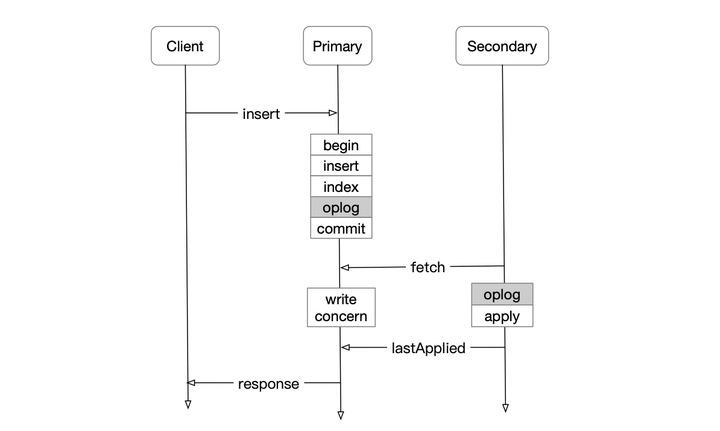
如图所示,和很多数据库一样,它选择在事务的基础上,再写一个oplog用于复制;当oplog复制到Majority节点之后,方可认为Commit:
– oplog写在一个数据表local.oplog.rs中,并非一个物理的日志文件
– 因此,oplog的写入和原本的数据、索引的写入,仍然会用一次事务提交;从IO放大的角度来看,吞吐上会有所放大,但次数不会放大太多
– 区别于上面提到的RSM模型,这里其实是先Apply,再Replicate + Commit,客户端可以选择等待一次请求Commit之后再返回响应,这个等待的过程称之为write concern,具体等待几个节点写入可以由用户控制
– 由于是先Apply再复制,Primary上可以并发Apply,为了匹配复制速度,在Secondary其实也是并发Apply的
基于以上,可以认为MongoDB的复制协议是并发Apply、顺序Commit。在Primary和Secondary都能做到乱序/并发Apply,给用户带来了很好的性能体验;但实现层面,同样也带来了巨大的复杂性。纵观其他数据库,能够很好地解决这一问题的也屈指可数。接下来便围绕这个乱序来一探究竟。
乱序
前面讲到了乱序,既然是乱序,首先我们应该定义一下顺序:
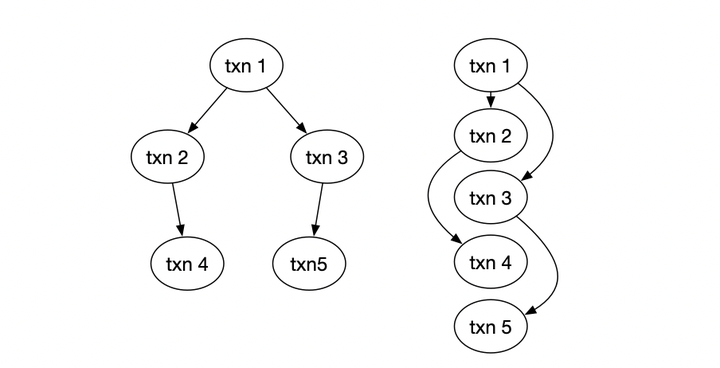
根据事务串行化的理论,事务之间的顺序由事务冲突来定义。例如这里的txn2读了txn1写的数据,因此他们之间产生一个依赖关系;通过具体的并发控制手段可 以得到事务之间的依赖关系,组成一个偏序集合。基于这个偏序集合,我们可以定义一个全序,例如右边的1、2、3、4、5,就是满足这个偏序关系的一种顺序。
实际在数据库中,所谓的WAL顺序其实就是一种合法的顺序,满足了事务冲突的偏序关系。而这里的oplog,其实也需要满足事务冲突的偏序关系,否则会破坏数据库的Consistency,在上一篇文章事务与复制的几种实现模式举例说明了这种异常。不过很有意思的一点是,oplog的顺序未必要和WAL的顺序一样,仅仅需要满足事务冲突的偏序关系即可。
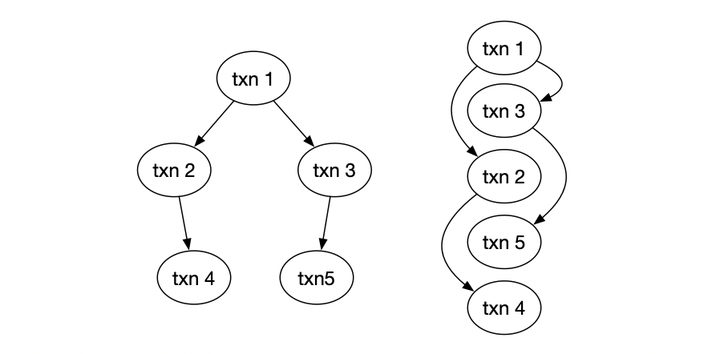
在MongoDB中,oplog的顺序和WAL的顺序显然也是不一样的,oplog的顺序由时间戳OpTime来表达,而WAL的顺序则由WiredTiger存储引擎来维护。那么,这里就引出了乱序的问题,即如果把所有事务按照oplog的顺序排列,会发现事务并不是按照oplog的顺序来提交的,而是中间存在空洞:
顺序复制
在存在日志空洞的情况下,我们要如何进行复制?如何判定Commit?如何维护原有的冲突约束?
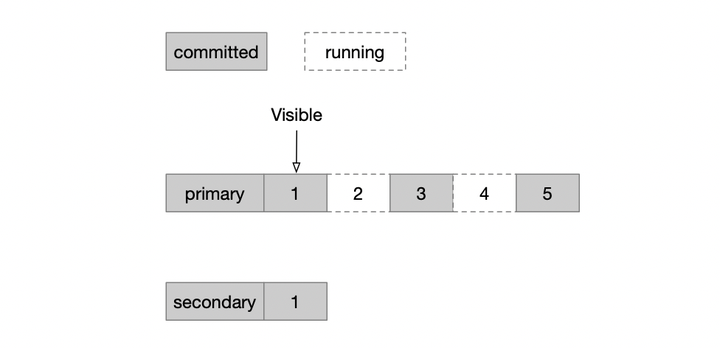
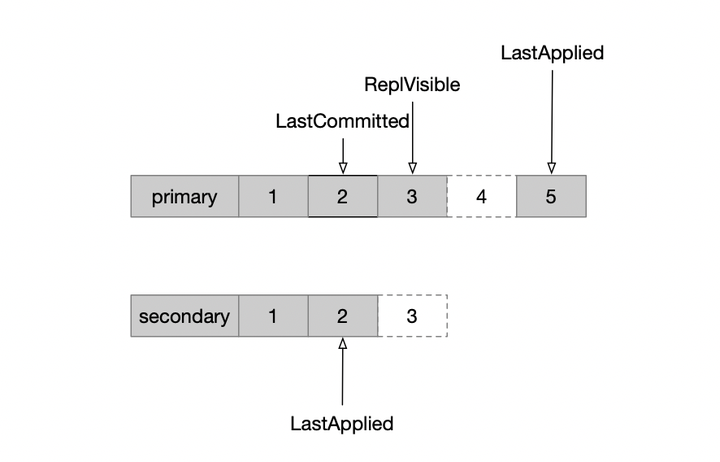
MongoDB的解法就是,把它变成顺序复制。如图,在Primary节点上会维护oplog的可见性,只有小于某个点的事务全都提交了,这里的oplog才可见,才可以复制到secondary节点。
实现层面并不复杂,在4.0之前仅仅是通过一个顺序插入随机删除的链表,按照OpTime顺序插入到链表中,当事务提交时从链表中删除;由于事务的上下文中持有了链表的节点指针,即可实现随机删除;那么这个链表即表示了所有未提交的且按照OpTime排列的事务,而链表头上即最小未提交的事务。复制时,小于链表头的Oplog即认为可见,即可复制。在上面的图中,链表维护的就是白色的running状态的事务。
有了上面的顺序复制机制之后,MongoDB便可以像Raft一样来定义Commit了:
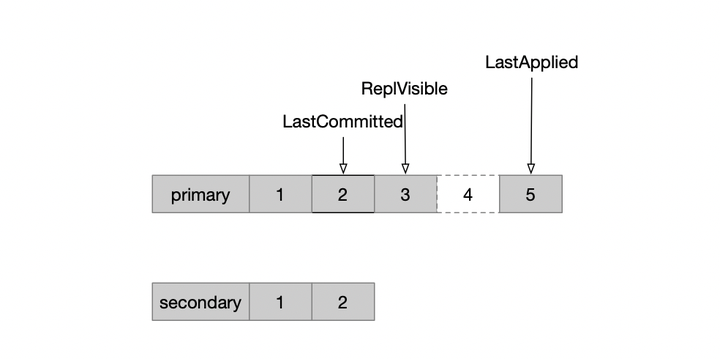
– secondary从primary拉取日志,写到本地并回放完之后,通知给primary;(这里在理论上写完本地即可通知primary)
– 类似于raft里的matchIndex,在primary节点也会维护每个secondary的oplog位置,而复制到多数节点的oplog位置,记为LastCommitted
– 另外会维护LastApplied,这是最新提交的事务,这个点的数据是可读的
并发应用
上面提到了在primary节点是并发apply的,而节点之间是顺序复制,那么,复制到secondary节点之后,如何apply?
首先明确的一点是,secondary节点也需要并发apply,否则无法匹配primary的速度,会给primary节点拖后腿。
接下便是secondary节点的并发Apply,包含这几个问题:
– 以什么粒度并发Apply,如何保持事务的冲突顺序
– 并发写oplog:并发写oplog过程中如果发生crash,oplog会造成空洞,如何处理
– 并发apply:并发apply过程中如果crash,如何恢复状态机呢
– 乱序apply的同时如何处理读请求,毕竟在apply过程中,状态机并不是一个Consistent的状态
第一个问题,secondary节点在拉到一批oplog之后,会按照表名和文档id进行hash,将没有冲突的操作hash到不同的线程进行apply。对于CRUD之外的操作,则需要串行执行。
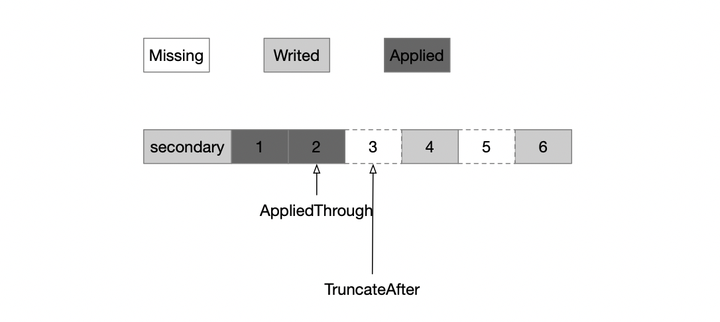
第二个问题,MongoDB将oplog的本地写和apply分成两个阶段,先并发写oplog到本地的表中,再并发Apply这批oplog。为了解决oplog的原子写入,显然也不能用事务;因为一批oplog可能比较大,超出事务的大小限制。因此在写入之前,记录truncateAfter为batch的开始,在写完之后删除truncateAfter记录;如果在此过程中发生crash,那么重启之后把truncateAfter之后的oplog截断即可。如图所示,truncateAfter点之后oplog还有两种状态,一种是已经写完的,另一种是还没写的,通过记录truncateAfter即可实现原子地写入一批oplog。
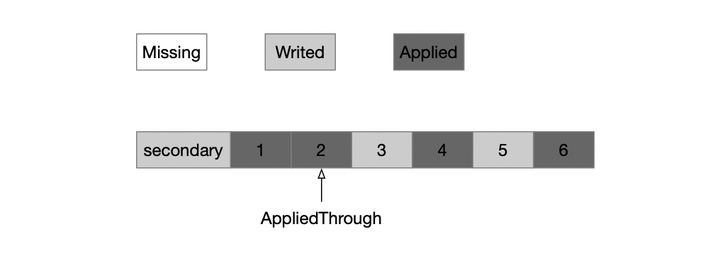
第三个问题,如何并发apply。并发Apply的过程中,oplog将会一部分处于Writed,另一部分处于Applied状态。通过记录一个AppliedThrough,可以识别出状态机的Consistent位置,只有当一批oplog应用完之后,才更新AppliedThrough。当发生Crash之后,状态机并不是Consistent的,因此需要从AppliedThrough位置重放oplog到末尾;这里基于一个前提,oplog apply是幂等的,具备REDO的性质。
第四个问题,在此过程如何读数据。对于有空洞的oplog是不能读的,因此此时的状态机并不是一个Consistent的状态。为此,在4.0之前,MongoDB干脆用了一个很粗暴的方式,加一个称之为ParallelBatchWriteMode的锁,阻塞并发的读请求;4.0版本对此进行了优化,基于存储引擎的多版本读的能力,维护一个LastApplied的快照,因此在Apply过程中数据并不可见,只有在一批oplog Apply结束之后才更新这个快照点使得数据可见。
Recovery
解决了secondary节点的并发apply之后,顺便讲一下Recovery的问题。这里包含两种Recovery,startup recovery和rollback recovery:分别是启动时的crash recovery,把数据库恢复到Consistent的状态;另一种是主从切换场景下可能造成的日志回滚。
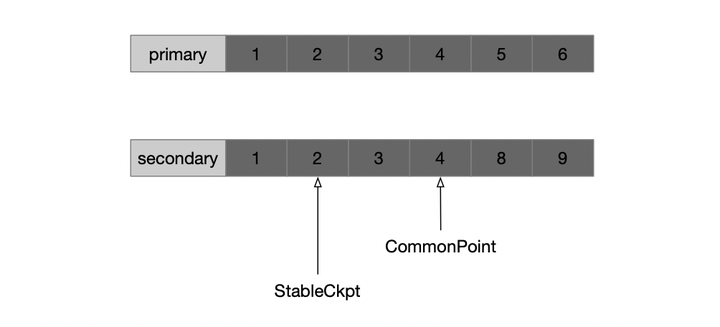
对于startup recovery来说,是通过checkpoint的方式。启动时,首先把oplog截断到truncateAfter之后,获得一个连续的oplog;然后把状态机回滚到checkpoint;再从checkpoint回放所有oplog即可。这个checkpoint有个名字,叫stable checkpoint,之所以称之为stable,因为它和rollback recovery有关系。
对于rollback recovery,其场景是主从切换。在切换过后,新的primary的oplog可能会和旧primary发生分叉,即新的primary原本落后于旧primary,它又继续写了一些oplog。在这种情况下,旧的primary需要截断自己的日志,保持和新的primary一致。
在raft中是通过AppendEntries实现这个功能,它的语义是先截断日志,再追加。这里的所谓截断,其实就有回滚的语义,因为仅仅截断日志是不够的,还要把状态机回滚到截断点之前的Checkpoint。
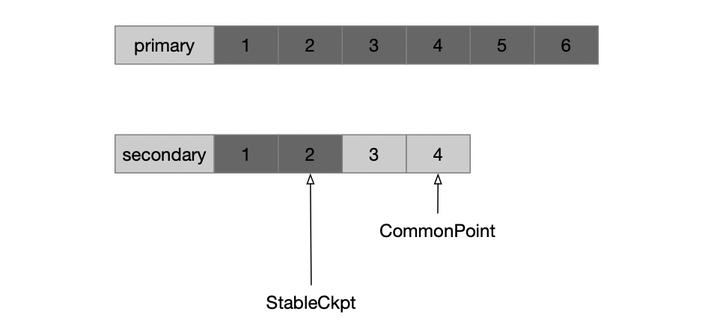
MongoDB在实现这个功能时,也是基于pull的。secondary会找到两个节点的Common Point,把在此之后的oplog截断,重新拉取。截断之后,仍然是回滚到stable checkpoint,然后回放oplog。而stable的特殊之处在于,这个点一定是majority commit的,因此无论是start recovery还是rollback recovery,都不可能回滚到这个点之前。而stable checkpoint功能,也是基于WiredTiger存储引擎来实现的,每次LastCommit更新之后,通知存储引擎进行Checkpoint。
Primary catchup
到这里复制协议就讲的差不多了,剩下的一个是锦上添花的功能。在Raft里面类似的场景是Leadership Transfer,即手动的主从切换。
在Raft中,RequestVote时通过比较每个节点的Log Tail,来找出满足Majority Committed的节点,它具有几个性质:
– leader completeness:每个term的leader一定持有所有已经commit的log
– leader append only:leader只会追加,不会尝试从follower节点拉取日志
– state machine safety:根据RSM的原理,每个state machine需要在同样的Log Index处应用同样的Log Entry
MongoDB的复制协议同样满足第一点,因为它也是基于Majority Vote进行选主;至于第二点则有所差异,它会进行一个catchup的过程:
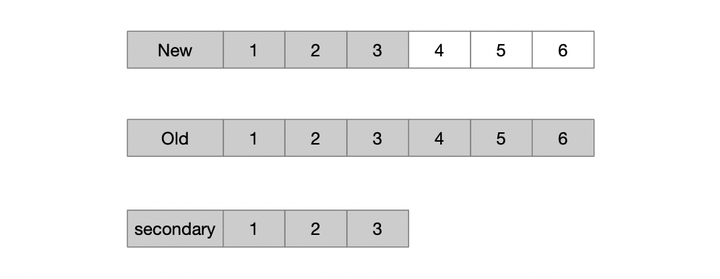
这里选出的新主,比旧主少了一段oplog,但仍满足第一条leader completeness性质;不过它会尝试从旧的节点去拉取oplog,尽量回到和旧的primary一样的日志。带来两个好处:
– 在手动主从切换的场景下,且客户端选择不等待commit就返回,可以减少丢失数据的概率
– 旧的primary不需要进行rollback,毕竟这是一个代价较大的操作
Read Concern
以上对复制协议的讲解忽略了一个重要的东西,如何读数据?毕竟,Raft中读请求只是作为一种优化,依然要保证安全性。
不过MongoDB相对任性,直接将选择交给了用户,提供了一个称之为Read Concern的东西:
– Local:读最新写入的数据,可能会丢失;这里对应了前面复制协议的LastApplied点
– Majority:读Majority Commit的数据,但不保证Committed都能读到;对应了复制协议中的LastCommitted点
– Linearizable:倒是能够保证Linearizability,即读到的都是Committed,先于读请求Committed的也都能被读到;实现中通过提交一个Noop来实现,性能堪忧
总结
本文总结了MongoDB从事务到复制的基本原理,特意屏蔽了对代码细节的展示,试图给读者一个更加直观和零基础的讲解。在上一篇文章事务与复制的几种实现模式的基础上,结合数据库的具体应用,展示了特定场景下的复制协议如何实现。这里的讲解更多的是客观视角,点评较少。MongoDB的实现自然也是槽点诸多,甚至令人发指;但从系统视角来看,这只是在具体的场景下权衡利弊的结果。
不过关于MongoDB或者说是WiredTiger的事务实现,这里只是一语带过,至于具体的事务隔离、持久化、多版本并发控制、时间点快照读,再到多版本的垃圾回收,Checkpoint等诸多内容,一言难以蔽之,且听下回分解。



写的太好了,纯干货