 MongoDB中文社区
MongoDB中文社区
MongoDB最明显的优势之一就是文档数据模型。它在模式设计和开发周期中均提供了很大的灵活性。用MongoDB文档可以很容易地处理那些不知道之后会需要哪些字段的场景。然而,有些时候当结构是已知的,并且能够被填充或扩充时,会使设计简单得多。这就是我们可以使用预分配模式的地方。
为避免性能问题,内存通常以块的形式进行分配。在MongoDB的早期(MongoDB 3.2版之前),当它使用MMAPv1存储引擎时,一个常见的优化是提前分配所需的内存,以满足不断增长的文档未来会达到的大小。MMAPv1中不断增长的文档需要由服务端以相当昂贵的成本进行位置的迁移。WiredTiger的无锁机制(lock-free)和重写(rewrite)更新算法不需要这种处理。
随着MMAPv1在MongoDB 4.0中的弃用,预分配模式似乎失去了一些吸引力和必要性。然而,仍然会有一些用例需要WiredTiger的预分配模式。与我们在《使用模式构建》系列中讨论的其它模式一样,有一些涉及到应用程序的事项需要考虑。
预分配模式
这个模式只要求创建一个初始的空结构,稍后再进行填充。这听起来似乎很简单,但你需要在简化预期的结果和解决方案可能会消耗的额外资源中取得平衡。大文档会产生比较大的工作集,也就需要更多的RAM来包含此工作集。
如果应用程序的代码在使用未完全填充的结构时更容易编写和维护, 则这种方案带来的收益很容易超过RAM消耗所带来的成本。假设现在有一个需求要将剧院的空间表示为一个二维数组,其中每个座位都有一个“行”和一个“数字”,例如,座位“C7”。有一些行可能会有比较少的座位,但是在二维数组中查找座位“B3”会比用复杂的公式在一个只存储实际座位的一维数组中查找更快、更简洁。这样,找出可使用的座位也更容易,因为可以为这些座位创建一个单独的数组。

场所的二维表示,绿色为有效座位,可用座位以蓝色框作为标记
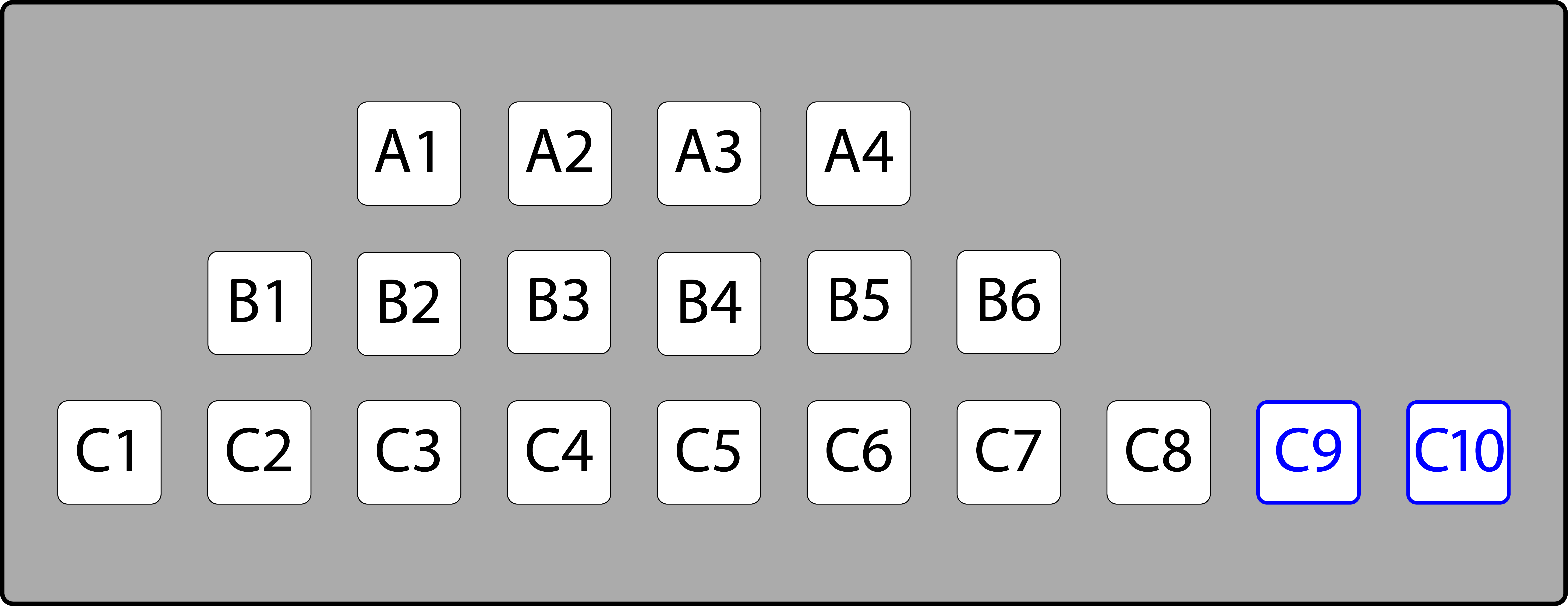
场所的一维表示,可用座位以蓝色框作为标记
应用场景示例
如前所述,二维结构的表示(比如场地)是一个很好的用例。另一个例子是预约系统,按照每天作为粒度,其中资源会被冻结或者预订。针对每个有效天使用一个单元格可能比保存一个范围的列表可以更快地进行计算和检查。

2019年4月美国的工作日数组
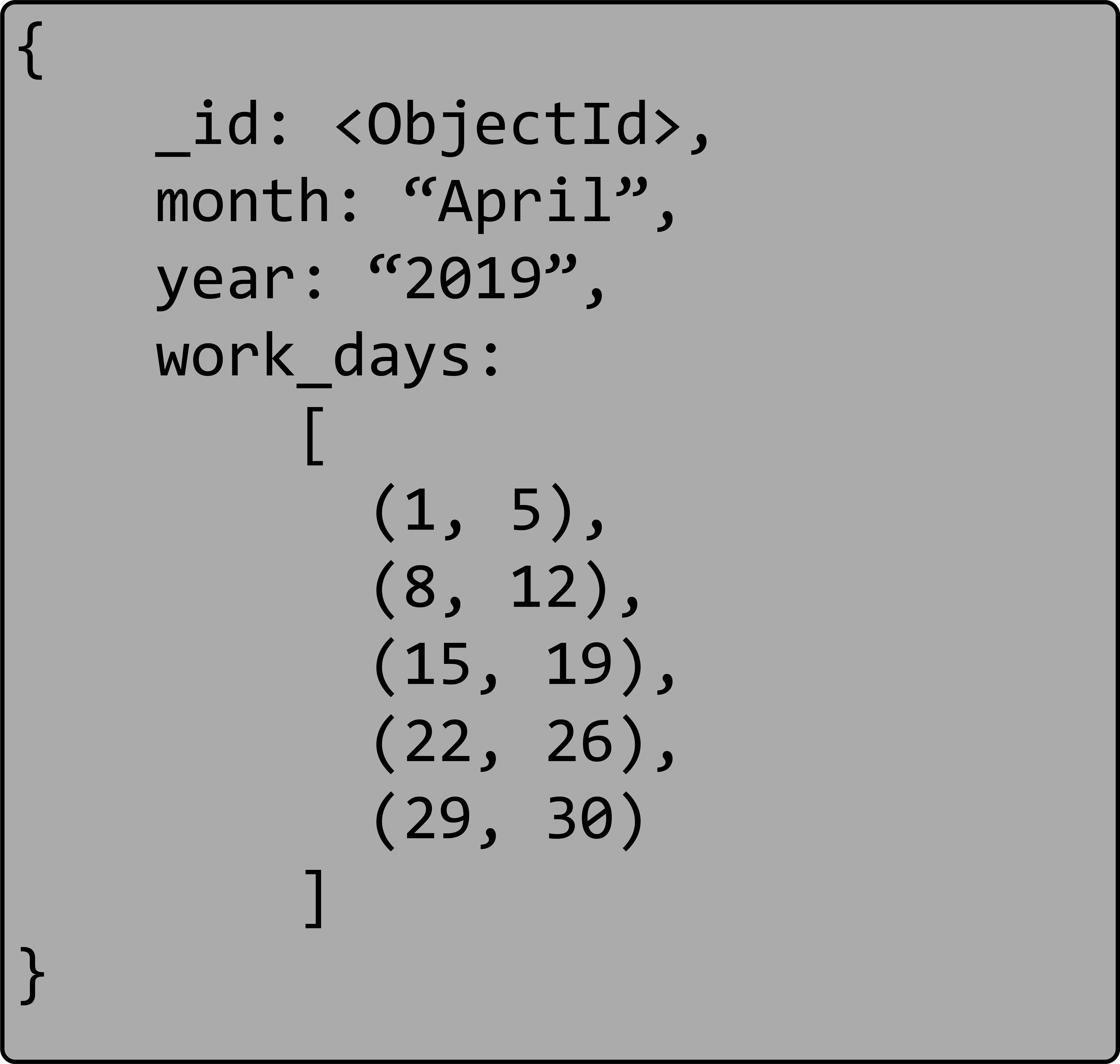
2019年4月美国的工作日范围列表
结论
在使用MongoDB的MMAPv1存储引擎时,此模式可能是最常用的模式之一。然而,由于这个存储引擎的弃用,它失去了一些通常的使用场景,但在某些情况下仍然有用。和其它模式一样,你需要在“简单”和“性能”之间做出权衡。
本系列的下一篇文章将介绍文档版本控制模式(Document Versioning Pattern)。
如果你有任何问题,请在下面留言。



评论前必须登录!
注册