 MongoDB中文社区
MongoDB中文社区
到目前为止,我们讨论的许多设计模式都强调省去JOIN操作的时间是有好处的。那些会被一起访问的数据也应该存储在一起,即便导致了一些数据重复也是可以的。像扩展引用(Extended Reference)这样的设计模式就是一个很好的例子。但是,如果要联接的数据是分层的呢?例如,你想找出从某个员工到CEO的汇报路径?MongoDB提供了$graphlookup运算符,以图的方式去浏览数据,这可能是一种解决方案。但如果需要对这种分层数据结构进行大量查询,你可能还是需要应用相同的规则,将那些会被一起访问的数据存储在一起。这里我们就可以使用树形模式。
树形模式
在以前的表格式数据库中,有许多方法可以表示一个树。最常见的是,让图中的每个节点列出其父节点,还有一种是让每个节点列出其子节点。这两种表示方式可能都需要多次访问来构建出节点链。
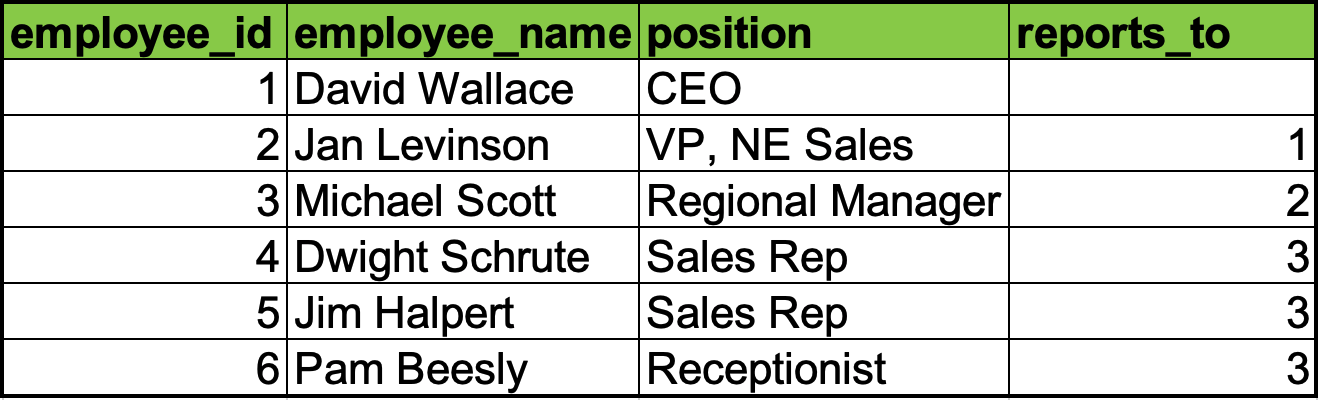
由父节点构建的公司架构
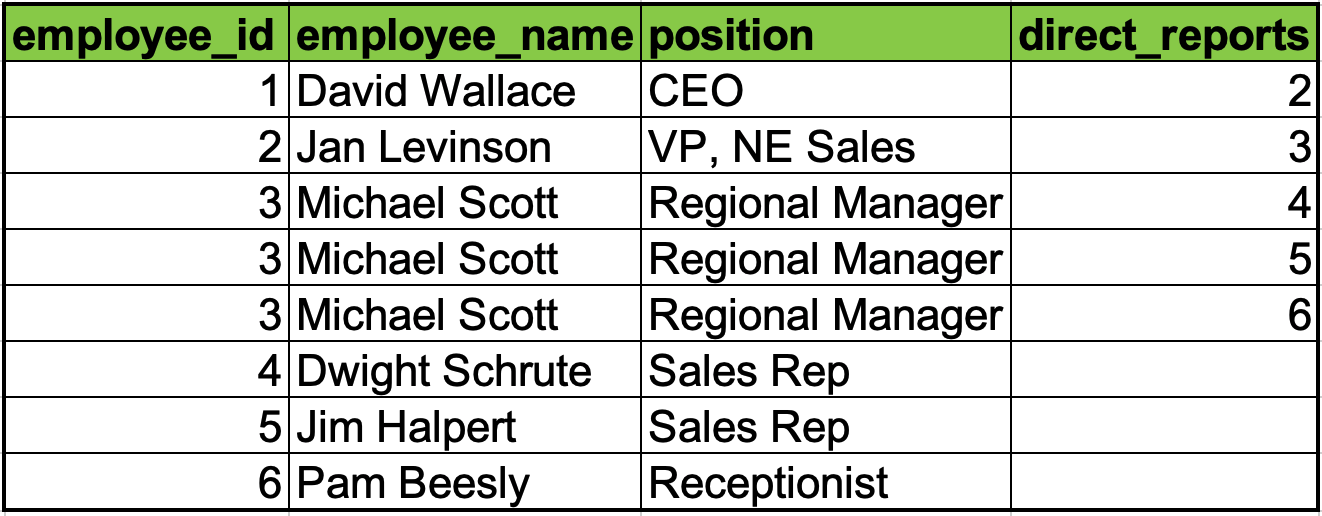
由子节点构建的公司架构
还有一种做法,我们可以将一个节点到层级顶部的完整路径储存起来。在本例中,我们将存储每个节点的“父节点”。这在一个表格式数据库中很可能是通过对一个父节点的列表进行编码来完成的。而在MongoDB中,可以简单地将其表示为一个数组。

如图所示,在这种表示中会有一些重复数据。如果信息是相对静态的,比如在家谱中你的父母和祖先是不变的,从而使这个数组易于管理。然而,在我们的公司架构示例中,当变化发生并且架构进行重组时,你需要根据需要更新层次结构。与不用每次计算树所带来的好处相比,这仍然是一个很小的成本。
应用场景示例
产品目录是另一个使用树形模式的好例子。产品通常属于某个类别,而这个类别是其它类别的一部分。例如,一个固态硬盘(Solid State Drive)可能位于硬盘驱动器(Hard Drives)下,而硬盘驱动器又属于存储(Storage)类别,存储又在计算机配件(Computer Parts)下。这些类别的组织方式可能偶尔会改变,但不会太频繁。

注意在上面这个文档中的ancestor_categories字段跟踪了整个层次结构。我们还使用了一个字段parent_category。在这两个字段中重复储存直接父级节点是我们与许多客户合作后发现的使用树形模式的一种最佳实践。包含“parent”字段通常很方便,特别是当你需要保留在文档上使用$graphLookup的能力时。
将祖先节点保存在数组中可以提供对这些值创建多键索引(multi-key index)的能力。这允许轻松找到给定类别的所有子代。至于直接子代,可以通过查看将给定类别作为其直接“父母”的文档来访问。我们刚刚说过有这个字段会很方便。
结论
在使用对于许多模式时,通常需要在易用性和性能之间进行权衡。对于树形模式来说,它通过避免多次连接操作可以获得更好的性能,但是你需要自己管理图的更新。
本系列的下一篇文章将介绍预分配模式(Pre-Allocation Pattern)。
如果你有任何问题,请在下面留言。



评论前必须登录!
注册