 MongoDB中文社区
MongoDB中文社区

本文是陈仕在“青芒话生长”MongoDB征文比赛的获奖文章,下面我们一起来欣赏下。
前言
偶然机会看到mongo中文社区办了场征文活动,觉得挺有意思的,虽说自己还在成为大佬的路上,但参与一下未尝不可。于是就有了这篇文章。
活动已规定了选题框架,我思索了小会儿,觉得从0到1+挺切合选题一,即聊聊如何由浅到深地学习MongoDB的核心技术。为什么是1+而不是1呢?因为我觉得0代表起点、原点,1代表走了一段路程,1+ 则代表在这方向上不断地走下去。毕竟学无止境嘛~
怎么聊这事呢?我本人是专职于database领域的,接触MongoDB却也不久,但有幸接触到要与内核打交道的项目,所以研究了一段时间,也略有所得,所以此篇文章中也必然会谈到学习MongoDB我们可以怎么做起。既然从0开始,也必然少不了谈Mongo的基本概念原理,由于它是分布式数据库,也得谈谈分布式技术的常见原理。这一趟下来,够有谈的了。当然单篇文章确实无法说尽全貌,我们不妨尽量地从high-level的角度来认识和理解根本的抽象性、原理性的东西,这样其实不管学什么数据库,我想会受益良多。
入门使用
毫无疑问,最有用的文档来自官方文档,相当丰富,够学一段时间了。但是若只是盯着文档看几周,估计用处不大,很容易忘。这种文档就适合边看边学,边看边做。
官方文档链接:https://docs.MongoDB.com/
有一个网站db rank,专门给各类database排名,MongoDB一直很靠前,说明自有其魅力。简单说,mongo是基于文档的NoSQL数据库系统,注意这里的文档可不是指word,excel那种概念的文档,专指JSON文档,{ k1: v1, k2: v2, … } 这个样子的。我们都知道,数据库可以在不同层面上进行分类,方便人去理解和对比。除了文档型,还有kv, columnfamily, graph等。那还有没有和mongo同处文档这一类别的呢?当然有,我以前接触过couchbase,Erlang写的文档型db,如果说要做性能比较,我倒觉得它们俩挺合适,虽然大家喜欢谈mysql跟mongo比较。
在这里还是推荐一本书《MongoDB in action》,书能帮我们系统地讲清概念,起到官方文档无法有的作用。书虽着重于较老版本 3.0,但我想与目前的4.2 在使用上也不会相差太大,等熟悉了使用和基本原理再换别的看。
在这里就不对各种命令使用做解析了,这个大家看文档看书都能get到。谈谈一些有体会的点。
schema-free
schema-free说的是没有schema或者schema很宽松,相对于关系型的relational schema。对database新手是不是对schema的概念也较模糊呢?我不知道中文是啥,很多词汇感觉就是英文表达顺口些。我摘抄了一个定义[1]:
A database schema is the skeletonstructure that represents the logical view of the entire database. It defineshow the data is organized and how the relations among them are associated. Itformulates all the constraints that are to be applied on the data.
它是一个骨架,数据库的骨架,定义了它的逻辑视图,即从外面看它长什么样子。包括数据是怎么组织的,是如何关联的,有什么样的约束等。因此它是一种descriptivedetail,应该说在db设计阶段就得有,帮助开发者建立mental view。
为什么要在这里着重说schema ? 因为确实mongo schema长得不一样,对习惯于关系型世界的人来讲看着有点别扭。其实也可以说它是schema-less,就好像没有schema似的,很随意,想怎么加field,加attribute都行,这样的能力很显然非常适用于不断动态发展的业务。初期你不知道你业务有哪些字段,你只希望在未来有需求时想加就加,此时mongo在这个层面上非常契合。然而,关系型schema若提供这样的能力代价就有些大了,相比于mongo。
适用场景
谈到这一点,恐怕做数据库的经常要回答的问题。一个用户过来问他的业务能不能接MongoDB,你该如何回答他?他问得很简单,可你答得却不能很简单,至少你得多问几个问题,因为他没有交待清楚。交待哪些呢?
是什么样的业务?数据量多大?
读写比例如何?读写QPS多大?
读写有何特征,比如夜晚是低峰?
访问模式(access pattern) ?
and so on
一般说来,业务是应该给出这些信息,我们才好判断到底合不合适。毕竟市场上有这么多db呢,如果每个db都适用于所有场合,那整这么多db干嘛?大一统不香嘛。
可有些时候比如在公有云环境下,业务上下文可能还是秘密,不想告诉你,或者说他也不太清楚/不好预估,此时能不能接呢?不好说,最好还是在测试环境里跑跑workload。前几天看了TiDB前段时间分享的KeyViz,我有了点想法,如果有童鞋对这种 observability 工具有兴趣,可以一起讨论下。
据《MongoDB in action》里所说,以下场景可接入mongo:
web app
这个范围太广了。不过确实MongoDB在web应用里应用挺多,web应用特点本要求扩展性高,灵活丰富的查询,动态地添加字段等
敏捷开发
这里主要强调的是由于没有固定的schema的优势使得很适用敏捷开发方法论
分析型和logging
capped collection适合于放日志数据,至于分析型我倒见不多,莫非还可比dedicated OLAP db更好?
caching
可变schema
脚本搭建
个人建议呢,自己写一个搭建集群的脚本,方便一键生成,非常方便,而不要每次一个命令一个命令地敲。我的脚本供参考[7]
后面我会谈到在快速创建定制化集群的基础上用gdb调试内核。
分布式概念及原理
这一块领域太大了!
MongoDB属于分布式数据库,相比于单机数据库,节点之间有了网络距离,于是乎,各种不靠谱的事就会发生了(google一下”分布式系统里常见的8个fallacies”)。我根据mongo实际情况讲点皮毛 _^^_ 更多有趣的资料务必参考DDIA[6],这个是迄今最通俗的版本。
我非常简单地用自己的语言从背景、为什么需要它, Mongo怎么做的三方面来谈谈,谈到的词汇建议读者多多google。
共识协议(Consensus)
背景
简单理解就是要多方达到一致。稍微接触这块的都知道raft,这个Stanford 教授 John Ousterhout 和其博士生 Diego Ongaro 弄出来的,已经在多种分布式数据库上应用了如TiDB, PolarDB。
当然业界还有其它协议,Lamport的Paxos(被应用到Chubby),Zookeeper的ZAB,MongoDB的pv1。
为什么需要它
简单来看,当多个节点共同来做决定时,如果你说你的,我说我的,还怎么决定啊?就像一群人在房间开会,七嘴八舌,就是没统一,最后这会只能白开了。同理在分布式系统中,我们需有一套规则让各节点对事件以及结果达成一致,这样才能正常运转。这其实与现实世界模型是很吻合的。
Mongo怎么做的
mongo用的是MongoDB pv1 ,是一种类raft 协议,不过它进行了丰富的扩展,如rs.conf()中就可配置各节点的priority,hidden, vote等属性,有非常大的灵活性;增加了PreVote, DryRun等动作等。详细细节读者可参考相关文档。
隔离级别/一致性(ACID/Consistency/CAP)
背景
这几个概念有相似性,就放在一起了。貌似分布式系统里我们一般不谈ACID,这是在单机关系型数据库常用的词汇,且这里面的C 与分布式系统所说的Consistency不是一回事!
CAP是Brewer 92年就提出的词汇了,很多论文现在都不推荐使用这个词汇,因为它很有歧义;
在众多论文里,还有与一致性很多的词汇,如
– causal consistency,因果一致性,Mongo中有
– linearizability,线性一致性,针对于single object的,始终读到最新的数据
– serializability,串行化,强调多个事务操作多个object的,在关系型db属最强的隔离级别
– strict serializability,linearizability + serializability,在google spanner中有提到
– sequence consistency: 顺序一致性,比linearizability弱点,比如x86 CPU默认一致性是它,我们常在C++ Memory Model里见到`std::memory_order_seq`
在数据安全性方面,要有持久化的保证,一般常用技巧是定期做checkpoint,且有write-ahead log,这在WiredTiger引擎层有原生的支持。
为什么需要它
凡是有副本,有读写,就必然存在读能否读到最新数据的问题,这就属于一致性的问题。有的业务要求必须读到最新写入的数据,此为strongconsistency,但有些业务不要求,那数据库可以放开这种强约束,于是有最终一致性eventualconsistency,即意味着给定一定的时间,最终各副本数据都会一样的,这样的实现比起强一致复杂度要低很多。
Mongo怎么做的
关于一致性,我得谈谈当初自己存在已久的误解。原来mongo里的quorom 不是我们常说的那种quorum !
以前深入了解过Cassandra,和其C++产品Scylladb,它们的原型是amazon 的Dynamo,论文里谈到quorum模型:当有N个节点,如果写大多数,即 W > N/2,读也大多数 > N/2,则读一定可以读到最新写入的数据。然而mongo虽然也有majority的说法,但其内涵完全是另外一回事。
写mongo时,客户端只可能写主,不可能写从,这与leader-less 系统(无主系统,各节点都是对等的)就不一样了,从是从主拉数据过去的;主从节点都在维护着一个majoritycommitted 的时间点,当写已经到达大多数时,这个点就会向前推进;
当客户端指定 readConcern: majority 时,能不能读成功,就看发起操作的时间点是不是在majoritycommitted 时间点后面,如果是,则majority 读就是成功的;
Mongo事务支持快照隔离,即事务可读最近稳定的一个点,它可能是老数据,但是它与其它数据是一致的,这样就避免了读写冲突。
复制和故障冗余(Replication, Fault Tolerance)
背景
在分布式系统中,复制是提高可用性的重要、常规手段。在复杂分布式环境下,总有个别组件就会崩,卡住,不响应,此时为了不影响用户的请求,就需要将请求转到正常的节点上,那数据就得有多份,要不然怎么访问先前访问的数据呢?
故障冗余是个经典概念了,分布式里的故障千奇百怪,软件的,硬件的,人为的;在典型的单主系统里,主节点要是没有,就会影响用户的读写,所以在前一个的主节点没了的那很短的时刻就必须有新的主来替代它,完美的时候用户根本感受不到切主。
为什么需要它
正如前面所说保证系统可用性,数据安全性。
Mongo怎么做的
Mongo是单主系统,写只能写主节点,因此它有选举机制,靠的是前面的所说的类raft协议。这是保证故障冗余;
复制方面,从节点从主节点拉oplog,oplog就可理解为raft里的log,它反映了主节点的mutation,从节点将这在本地apply,就可达到与主节点一致的状态。
非常详细的说明见官方源码[12]。
内核
个人接触内核也没多久,在此抛砖引玉。
内核其实分Server层和Storage Engine层,由于Server接触不完备,暂只讲讲引擎层的事儿。
存储引擎
这里有一份由doxygen生成的文档[11],值得一阅。
引擎层技术可谓是数据库系统的核心技术,里面涉及了数据库的核心原理的实现。首先我们要明白,数据的组织可以是多种方式,究竟哪个方式好,在代码未实现出来之前,恐怕还没法说。
明显这里我们需要插拔的特性,数据库层(也就是干sql,cql,查询优化,执行计划等的)可以灵活接入多种存储引擎,这样最后谁好谁差,比一比就知道了。所以引擎层必须很独立,提供最原始的接口供上层调用即可,这也是计算机分层思想在数据库领域的完美体现。
MongoDB引擎从3.x开始就是WiredTiger了,官方似乎一直没考虑把RocksDB兼容性的代码放进去,所以MongoRocks是一个第三方的存在;当然还有一个in-memory引擎。
WiredTiger
这里简称为WT[8]。WT最初是一家由大佬 Michael Cahill 创立的,某一年被MongoDB收购,从此一直是mongo默认的存储引擎。我们可以在这儿[2]看到WT的基本介绍,挺丰富的,没事可多查阅。
WT首先是一个kv存储引擎,类别上与Rocksdb一致,不过名气确实小很多,原因可能是比较小众,貌似只有mongo用,且代码看着确实不太易读;
引擎索引实现是B tree,而不是B+ tree,这一点网上也有不少的讨论,至于为何用B tree,据我所知:
1.mongo着重于提高point query性能,而非range query,这样不像B+ tree那样每次都得去叶子节点拿数据,平均来看,走更短的路径;
2.优化读多写少的场景;
3.其他。
WT API的使用
WT在mongo使用,其实基本的调用就那么几个:
1.创建连接conn
wiredtiger_open(home, NULL,”create,cache_size=**, transaction_sync=**, checkpoint_sync=**,…”,&conn)
这在启动时就需调用,生成一个指向db的WT_CONN,它作为WiredTigerKVEngine的私有成员。
2.创建session
mongo里的操作都有session上下文的,文档里的session,其实就对应引擎层的WT_SESSION ; 代码里为了高效利用session,有个sessionCache供使用,不用每次都去open
conn->open_session(conn,NULL, “isolation=**”, &session)
3.创建表/索引
当mongo层执行createCollection/createIndex时,即有:
sesssion->create(session, “table::access”, “key_format=S,value_format=S”))
4.在session上创建cursor
session->open_cursor(session, “table:mytable”, NULL,NULL,&cursor)
5.支持事务时,在session上开启事务
session->begin_transaction(session, “isolation=**, read_timestamp=**,sync=**,…”)
6.用cursor set/get key/value
用户看到的json,mongo server层看到的BSON,其实在底层都转成了(key, value) pair
cursor->set_key(cursor,”key”)
cursor->set_value(cursor,”value”)
cursor->update(cursor);
7.提交/回滚事务
session->commit_transaction(session,”commit_timestamp=**, durable_timestamp=**, sync=**,…”)
session->rollback_transaction(session,NULL);
对于以上步骤,几点澄清:
·WT API调用就像那种风格,特别明显的是会有一参数char* config,里面就用a=b这种格式来指定各种配置参数。虽说挺原始的做法;
·有关时间戳的参数较为复杂,需要深入文档;
·参数含义还是得参考[2]。
时间戳机制
从官方文档和视频[14]中来看,从3.6开始引入 logical session,在WT 的update structure里添加timestamp field等这些动作都是逐渐在为支持事务、分布式事务为铺路。
我为熟悉MongoRocks对事务的支持接触过WT的时间戳一些概念,目前还不能很系统地论述各个时间戳之间是如何运作的。这方面可多多参考[2] ,我不在此讲了。
MongoRocks
听名字想必也能猜得到是与rocksdb有关,想到它也很自然,既然底层接kv engine,rocksdb又是kv型,完全可接啊,正如MyRocks那样。看源码[3] stars也有300+,最初由开发者 Igor Canadi 及其他实现了3.2, 3.4的MongoRocks版。项目被搁置一段时间,几个月前 Igor Canadi 接受了wolfkdy 对MongoRocks 4.0 的MR[16],我在其中参与了相关PR提交如[4]。
4.0 mongo-rocks 驱动层的实现主要集中于事务部分,正如 Igor 所说,3.6.x之后,mongo的内部事务跳跃性大,若正确实现4.0版需很大一部分精力[5]。
MongoRocks 4.0 刚出不久,因此还需更多时间来稳定,比如之前由我发现的oplog读取有空洞的问题[13],已被作者修复[15]。个人还是非常期待Rocksdb能接入到Mongo的,相信会有比WT更亮的点!在这方面个人应该会投入更多时间,期待有更多国内开发者加入!
内核gdb调试
大型代码,如果用gdb单步着来学习肯定是不行的,单步只适用于调试bug的时候。我这里谈gdb调试用来干嘛呢? get runtimepath !
我一直认为,拿到一份大型C++项目,除了肉眼盯着代码看半天了解code flow之外,用gdb bt 更是一大利器!在server端加一断点,客户端发一个命令过来,然后一bt ,立刻知道server 走的核心路径,很方便!
划重点:请用 >= 8.x 版本的gdb。好处是bt自带颜色显示,看着比以前舒服多了。
以下聊聊一般怎么用。
首先启动一副本集或分片集群(取决于你关注哪个),对主进行以下设置:
cfg=rs.conf();cfg.settings.heartbeatTimeoutSecs=3600; cfg.settings.electionTimeoutMillis=3600000;rs.reconfig(cfg)
这里假设我们要调试主。为了防止调试时,默认的时间内就failover了,所以增大heartbeat,election的超时,这样主就一直仍是主(当然若想调试主从代码的code,就不要这么做了)
当我们想看看insert命令的请求路径时,
随便看看代码,去搜索一下insert关键字,相信不难发现有CmdInsert这样的字眼。再仔细一看,发现它继承一个基类,它还有个run方法,有感觉的开发者其实这时就能猜一猜了:断定server收到insert请求时,很可能run要被调用!
于是乎可在run处加个断点,或者我们在grep中发现了insertRecords的字眼,更能判定插入文档时很可能走了这里,于是有了这样:
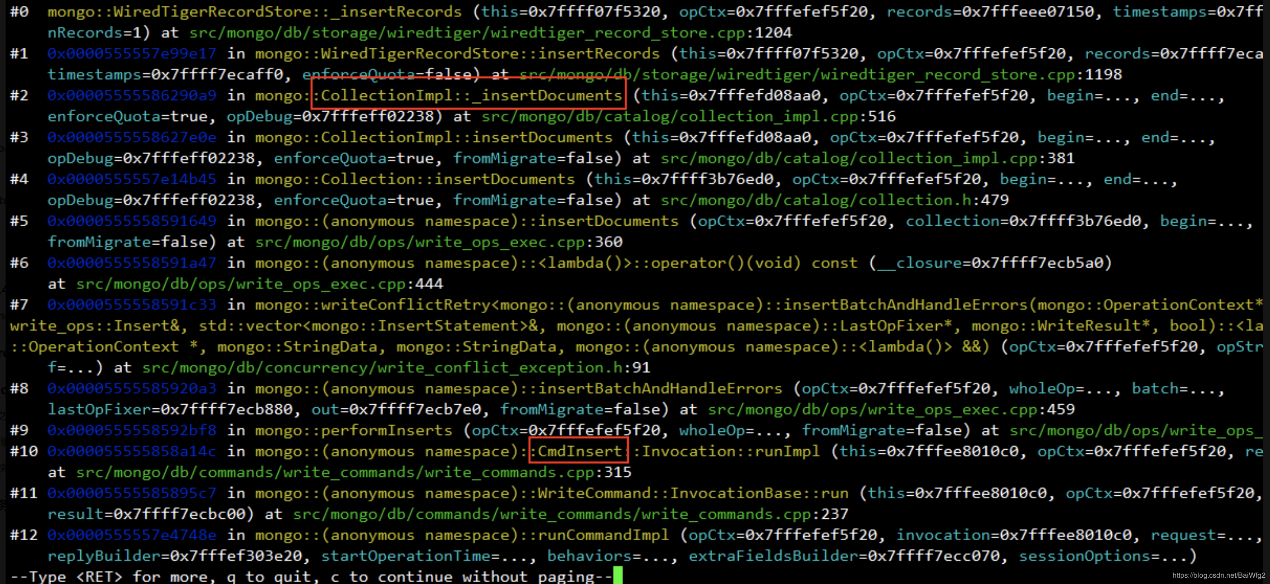
可以继续enter,这个路径从libc.so start_thread 到run,到insertRecords 很长的,这一段路径够我们分析是怎么走的了。
同样,对于find, update,delete都是类似手段。
对于事务操作,可以去grep transaction字样,也会发现可以被作为断点的函数,遇到begin_transaction,commit_transaction, rollback_transaction其实是很熟悉的函数名称,适合加上断点。
结语
MongoDB技术浅谈在此,这方面知识量非常庞大,确不是由一篇文章能道尽的。对我自己而言,其内涵本身是迷人的,因为它是数据库,它是分布式系统,它还有许多毛病。尽管Mongo官方缩紧了协议,一些云厂商没法玩高版本了。但我想,只要它还是开源的,只要它代码还是真的,对工程师而言这仍然是一件欣慰的事吧。由浅入深,从此刻开始!
作者:陈仕
一名热衷和专职于数据库、分布式、存储技术的技术人,对linux内核、微处理器架构也颇有兴趣。工作初接触redis/couchbase/scylladb等NoSQL数据库,现在腾讯做mongo云数据库开发。业余时间喜欢爬山,研究论文,学习人文。
References
[1]https://www.tutorialspoint.com/dbms/dbms_data_schemas.htm
[2]http://source.wiredtiger.com/
[3]https://github.com/mongodb-partners/mongo-rocks
[4] https://github.com/mongodb-partners/mongo-rocks/pull/153
[5]https://github.com/mongodb -partners/mongo-rocks/issues/145
[6] MartinKleppmann DDIA: Designing data-intensive Applications
[7]https://gitee.com/cshi/codes/dbzrmhvy4s87lnt60uc2f46
[8] https://github.com/wiredtiger/wiredtiger
[9]https://www.cnblogs.com/williamjie/p/10416294.html
[10] 4.0事务浅析:https://mongoing.com/archives/6102
[11] 存储引擎API:https://mongodbsource.github.io/doxygen/index.html
[12] 源码对复制的详细解释:https://github.com/mongodb/mongo/blob/d8caa7410ce2642d1c67f31c330f6d82ba384495/src/mongo/db/repl/README.md
[13]https://github.com/mongodb-partners/mongo-rocks/issues/154
[14]https://www.youtube.com/watch?v=mUbM29tB6d8
[15]https://github.com/wolfkdy/rocksdb/commit/5eb8a67f955b4035d6c034e00f1bb7c6bb6f47d4
[16]https://github.com/mongodb-partners/mongo-rocks/pull/149
感谢国内领先的数据库(MongoDB)及出海CDN(Akamai)服务提供商上海锦木信息技术有限公司对本次征文的大力支持!
Mongoing中文社区( Mongoing.com)成这立于2014年,是大中华区获得官方认可的中文社区,经过社区志愿者们的不断努力,目前已经有超过2万的线上及线下成员。中文社区由博客、线下活动、技术问答、社群、官方文档翻译等版块组成。截至2020年社区已成功举办数十场人数超百的线下活动,发表关于MongoDB应用优质文章百余篇,相关合作单位已达20多家。
中文社区的愿景是:为广大MongoDB中文爱好者创建一个活跃的互助平台;推广MongoDB成为企业数据库应用的首选方案;聚集 MongoDB开发、数据库、运维专家,打造最权威的技术社区。
Mongoing中文社区公众号: mongoing – mongoing
Mongoing中文社区http://mongoing.com/
上海锦木信息技术有限公司是国内领先的 MongoDB数据库服务提供商,是 MongoDB厂商官方合作伙伴。
锦木信息始终坚守在数据技术领域扎实地实昽和前行,成为国内 MongoDB领域的新兴技术力量。服务的客户广泛分布于金融、电信、零售、航空等行业,助力用户完成从传统IT架构向互联网架构的顺利转型。
2018年起,锦木信息与MongoDB中文社区建立了良好的合作关系,致力于共同创建繁荣的 MongoDB生态环境。
上海锦木信息技术有限公司http://www.jinmuinfo.com/



评论前必须登录!
注册