 MongoDB中文社区
MongoDB中文社区

简介
GaussDB(for Mongo)是华为云自主研发兼容MongoDB4.0接口的文档数据库。
GaussDB(for Mongo)近期发布了一个新特性:时间漫游读能力。对于MongoDB的Find操作,用户可以指定 一个readAt参数,指定读取数据库历史上的某个时间点的数据。这个特性的用途有:
- 对历史数据做报表,省去了用户自己按时间分库分表的麻烦
- 在不影响业务读写的情况下,对数据做Point in Time的备份
该特性使用户可以在一个数据库实例,甚至同一个表空间上,管理多个历史时态的数据。时态数据库的概念,在SQL2011中被正式定义,主流数据库,如Oracle/MSSQL都支持该功能,MongoDB官方社区版/企业版目前还不支持这一能力。
用户接口
创建快照命令
mongos> db.runCommand({snapshot:1, op:"create", name:"s1"})
该命令创建了一个名为s1的快照。
通过快照查询Point In Time 的数据
mongos> db.runCommand({find:"foo",readAt:"s1"})
在find命令中,指定readAt : s1,表示从s1这个快照中读取数据。如下所示,在s1创建之后,我们插入的 {a:3,c:3}这条记录对用户是不可见的。
mongos> db.foo.insert({a:1, c:1})
mongos> db.foo.insert({a:2, c:2})
mongos> db.runCommand({snapshot:1, op:"create", name:"s1"})
mongos> db.foo.insert({a:3, c:3})
mongos> db.runCommand({find:"foo",readAt:"s1"})
{"cursor" :{"firstBatch":
[{"_id" : ObjectId("5dd75662b9c50d4bdca52721"), "a" : 1, "c" : 1},
{"_id" : ObjectId("5dd75687b9c50d4bdca52723"), "a" : 2, "c" : 2}]}}
与MongoDB4.0/4.2提供的readAtClusterTime 能力不同的是,GaussDB(for Mongo)的时间漫游读提供的快照是持久化的,可以长期保留在系统中。用户可以通过命令删除快照,删除后快照会被自动清理。
删除快照命令
db.runCommand({snapshot:1, op:"delete", name:"s1"})
实现思路
概括而言,MongoDB的每个读操作都attach在特性的readSource上面,这部分逻辑在RocksRecoveryUnit::_txnOpen中。
一个readSource可以理解为是一个数据库快照。在一般情况下,MongoDB的快照如下:
- kMajorityCommitted,从Raft Common Point快照读
- kLastApplied,从系统最新快照读 allCommitTs,从没有oplog空洞的快照读
时间漫游读的能力,就是将readSourceattach在用户创建的快照上。
GaussDB(for Mongo)使用RocksDB作为底层存储引擎。RocksDB中,每一个快照可以用一个SequenceNumber来标识,用户创建的快照作为一个键值对存储在RocksDB的元数据文件中。
Map<String,SequenceNumber> // snapshotName <-> SequenceNumber(aka snapshot)
当进程初始化后,持久化的快照被加载到内存中,在RocksDB的GC(CompactionIterator)流程中,每个key的多个版本被快照分割为若干区间,每个区间只保留最大的版本。
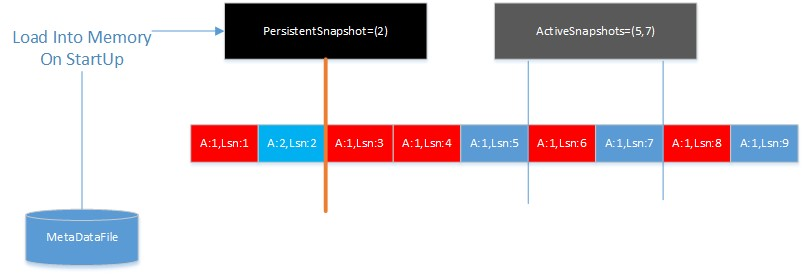
上图中,userKey=A的数据有9个版本,分别由9个LSN标识。系统中有两个活跃快照(5,7)。活跃快照将数据分成[lsn=1…lsn=5],[lsn=6…lsn=7], [lsn=8…lsn=9(current)]三个区间,对于每个区间,只有最大的版本是可见的,因此RocksDB做完GC后,会保留A的Lsn=(5,7,9)三个版本的数据。
假设用户的时间漫游快照为”s1″ -> (lsn=2),RocksDB的GC流程不仅需要考虑ActiveSnapshots,也需要考虑时间漫游快照需要Pin住对应版本的数据。

上述是时间漫游读的思路。在具体的工程实践中,还有很多细节需要考虑,比如如何保证集群中多个Shard的快照一致性,如何防止过多的时间漫游快照影响性能等等。
案例介绍
某政企用户使用MongoDB存储TB级别的地图块的瓦片信息(tiles),瓦片信息相对静态,用户每隔一周更新部分地图块。在更新的过程中,业务不能看到部分是新数据,部分是老数据。
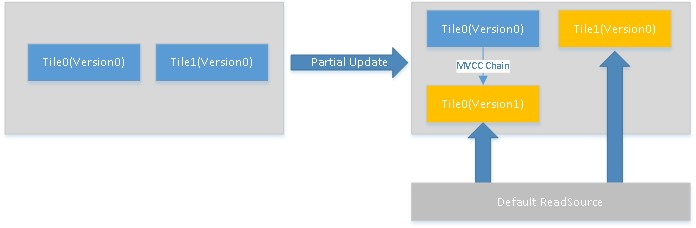
如上图,由于Update的过程漫长,持续几个小时,业务在遍历Tiles的过程中,会读到Tile0的Version1和Tile1的Version0,然而业务想要访问的是Tile0的Version0和Tile1的Version0。
用户有考虑过MongoDB的多文档事务自带的快照隔离能力,然而用户的更新过程很长,一次要达到2-3个小时,MongoDB的多文档事务无法满足要求(一分钟的事务时长限制)。
在分析完业务的诉求后,华为云工程师为用户提供了时间漫游读的方案,在用户做批量更新之前,先为当前数据库做一个时间漫游快照,业务从时间漫游快照读数据,如下图:

当用户漫长的Update执行完成后,释放掉时间漫游快照,MongoDB又会从当前最新快照读数据,如下图:

试想如果没有时间漫游读能力,用户需要先把全量数据拷贝到另一张表,对部分数据完成更新后再Rename回来,操作复杂,且浪费IO容易造成业务受损。时间漫游读能力简化了用户的操作,降低了用户的运维成本。
总结
GaussDB(for Mongo)时间漫游读功能提供了历史时间点的快照读能力,用户不需要担心快照时间驻留过长而被Abort掉。API简单灵活,用途广泛。欢迎有类似需求的DBA进一步交流。
作者:高强,华为云GaussDB(for Mongo)研发负责人,十年数据库内核研发与运维经验,致力于做最好的云原生文档数据库。



评论前必须登录!
注册