 MongoDB中文社区
MongoDB中文社区
本文节选自华为云DDS数据库架构师崔鑫在2020年MongoDB中文社区年终大会上的分享。
今天给大家分享一下MongoDB内核源码在分布式事务上的一些表现。
1. MongoDB作为现代数据库的High-Level Design设计,包括复制,分片,分布式事务,逻辑时钟,以及MongoDB在这些方面的设计和选择。
2. 主要介绍计算存储分离架构,也就是GaussDB(for Mongo)特性、方案和优势。
3. 主要讲华为云DDS团队在MongoDB社区源码上的优秀实践和对社区的贡献。
High Level Design:分片、复制、事务和分布式事务
对于分片集群来说,在分片系统中,每一个节点的时钟都不一致。在各个节点的不一致的时钟,如何实现ChangeStream,让ChangeStream在全局上作为一种可能?

先考虑一下这种比较极端的场景:有两个分片,
Shard A的物理时间戳可能是11:30,
Shard B的物理时间戳可能是12:30。
插入序是在Shard A上插入了一次Oplog,再插入了一条记录,OplogTime是8000。
再在Shard B上去插入一条它的OplogTime,因为它是晚一个小时的,它可能是10000。
这种情况下,Shard A上再去插一个8001,Shard B上再去插一个10001
我们真实的插入序实际上是8000,10000,8001,10001。但在ChangeStream这种场景下,在ChangeStream的全局来看的话,它是有8000, 8001, 10000和10001,这是一种错误的时序在这种时序下的话,我们的全局ChangeStream实际上是不可用的。所以对于整个分布式系统来说,我们需要一个时钟同步机制来保证各个Shard之间的时间点是一致的。
以上问题有两种方式可以解决:
一种是采用全局授时的方式,比如我们可以采用GPS时钟或者是NTP服务这种全局授时点;
另一种方式,也就是我们采用一种局部的时间戳的方式去演进,这个就叫逻辑时钟。
在分布式事务中,逻辑时钟的话,可以将发送节点和接收节点的时间产生一个联系。比如,在逻辑时钟中,要求每一个时间点,开始的时间戳都是0。当节点发生在内部的时候,时间戳会向上加1。当节点发生在发送和接收的时候,发送的时候将发送的时间戳带上并且发送到接收时间处,接收时间戳一定要大于发送的时间戳,也要大于本地的时间戳,以此来保证我们可以满足C1<C2。这样的话,在整个的分布式事务的逻辑时间戳上我们可以保证如果他们的发生顺序是有序的,他们的这个逻辑时间戳的顺序必然也是一个有序的方式。
实际使用中,逻辑时钟过于抽象了,例如逻辑时钟 1,2,3,4只能代表一个顺序的大小,他并不代表整个事务实际发生的时间点。它丧失了11:30或者12:30这个物理时间的含义,所以在真实使用的过程中,我们对逻辑时间戳实际上是采用一种混合逻辑的处理方式,我们称之为混合逻辑时钟。

在这个混合逻辑时钟中,将物理时钟和逻辑时钟混合起来做一个全局的时间出来处理。如上所示,我们的混合逻辑时钟会采用一种本地的推进方式,这个就是刚才说的一个接受的时候,他会比较本地的时间戳,然后在本地时间戳、本地真实的物理时间和收到最短request的时间,三者取最大的时间,作为本地时间的一个推进,需要说明的是,这个时间戳的分配是取决于oplog的时间戳。只有当oplog真正写入数据的时候,本地的逻辑时钟才会向前推进。在整个混合逻辑时钟,在整个集群中采用动态推进的方式,每一条发送和接收的请求,都会依据请求中的时间来推进本地的时钟,这样在全局的情况下,每个节点的混合逻辑时钟最终会趋同,趋向同一个地址,趋向同一个时间。这样的话,刚才说的时间偏差就已经不存在了,才可以在集群中做分布式事务。
MongoDB是基于Raft协议去做的一个复制集的数据复制和选主操作。Raft的论文如这个链接:
In Search of an Understandable Consensus Algorithm:
https://raft.github.io/raft.pdf
Raft基本上规则
在Raft协议中,我们会有一个主节点,用来响应client的请求。client的所有请求发送到主节点,主节点首先会将他的请求作为日志落到自己的日志系统中。
与此同时,主节点还需要将自己的日志分配到所有的从节点。然后他会等待从节点对日志进行复制,一旦发现大多数从节点对这个日志进行了复制,它才会把这个数据响应到状态机里,并且返回到client。
MongoDB实现细节
但MongoDB并不是严格的遵循了这个Raft的实现方式,实际上MongoDB在readConcern等于1的时候,数据是优先于Raft去提交的。因为MongoDB提供了多种readConcern的功能,在readConcern等于1的时候client发送给主节点,主节点只要将自己的日志落到自己的存储引擎里,它就会直接反馈client告诉提交成功,在这种情况下,一旦这个数据库发生了异常,主节点就需要回滚状态机的数据,对于MongoDB来说,它是需要回滚MongoDB的存储引擎的数据。
新旧的版本差异:
在这种存储引擎的数据恢复里面,MongoDB在3.0和4.0版本里采用了不同的方式。
在3.0的系统里,MongoDB的rollback方式是采用的是rollback refetch的方式。
它首先找到了本节点的oplog和新主节点的最近公共祖先,并通过undo操作将数据回滚到最近公共祖先。例如这条oplog是插入,那就删除掉。如果这条oplog是删除,那就从远端把这条信息拿出来。回滚到公共节点以后,后续操作就是走网络拉新主节点的最新的oplog进行回放,并且覆盖老的记录。它是一个比较复杂的操作,首先它需要回滚操作,回滚的话,因为oplog不是一个全量记录,所以在一些删除数据或者删除DB的情况下,回滚操作的动作会比较大,损耗也比较大。
在4.0系列,MongoDB 的回滚方式是recover to stable timestep。
在这种情况下的话,回滚操作我们仍需要找到本节点的oplog与新主节点oplog的最近公共祖先。但找公共祖先的过程实际上是WireTiger可以支持回滚到Raft协议的那个stable common point,将数据回滚到这个点以后,我们再去应用后续的oplog,这样两步就可以做到回滚操作。
关于MongoDB的复制与回滚的操作的具体的文章,可以看以下的这两个相关的介绍:
https://github.com/mongodb/mongo/blob/master/src/mongo/db/repl/README.md
https://mongoing.com/archives/72571
MongoDB事务开发历史上也是经历了两个阶段:
第一个阶段:wiretiger基于事务id做的事务的实现,我们称之为CSI。
第二个阶段:基于时间戳去做的一个事务的实现,我们称之为GSI。
CSI和GSI的差别:
CSI,它是选取当前系统中快照列表里的那个最近时间点作为它的读取快照去进行事务的一个提交。在这种情况下,它可以减少写事务冲突发生的概率,并且提供读事务读取最新数据的能力,但是它不提供去读取历史事务的能力。
GSI,它采用了历史快照列表,我们可以将事务读快照能力适当的往前提。这样的话,虽然说会提高一点点写冲突的可能性,但是它可以采用MVCC的方式去读历史的一个时间点,在有oplog空洞产生之前去读上一个无空洞的时间戳,这个是以前基于CSI的事务无法做到的。在GSI的情况下,这个read timestamp由mongo层去确定的时间戳,在这种情况下我们可以使用一个无空洞的时间戳去读取数据,释放pbwm锁去提升整个数据库的性能。
MongoDB事务相关代码实现
MongoDB同时采用事务的事务id,和时间戳两种方式,以此来实现一种GSI隔离级别。
基于时间戳的一个核心点是,这个混合逻辑时钟作为oplog的一个ts,在整个事务里体现。因为每一个读写操作都会去写入oplog,所以的话,oplog的这个ts,也就是整个事务的ts。整个事务的一个commit的ts,然后用来去做事务之间的可见性判断。
对于MongoDB事务的相关介绍,我这里也推荐两篇文章:
https://mongoing.com/archives/38461
https://mongoing.com/archives/72571
MongoDB的分布式事务是基于两阶段协议。

第一阶段就是prepare阶段,在prepare过程中,所有的coordinator会向所有的节点去发送prepare命令,所有的节点收到了这个命令以后会返回自己的prepare timestamp,然后由协调节点去决定选取一个最大的prepare ts作为commit timestamp。
coordinator和所有的shard之间的通讯会促使所有的事务参与者得到一个协调一致的HLC。在这种逻辑时钟一致的情况下,commit timestamp就是全局顺序一致的。
第二阶段的话就是提交阶段, coordinator会将刚刚的committed ts作为commit timestamp的时间戳,然后向所有的节点去广播。
需要关注一点,就是在对具有prepare timestamp的事务进行读取的时候,如果当前的事务是处于prepare状态的,并不确定自身的读时间戳和prepare状态的大小的话,需要去一直等待这个事务,等到事务提交或者abort以后才去会处理,这个就是刚才所说的,MongoDB在代码实现的时候,为什么会有wiretiger prepare conflict retry这个逻辑的原因。
华为云在存储计算分离架构的GaussDB(for Mongo)中的一些功能上的优势
1. GaussDB(for Mongo)可以秒级添加从节点。社区版的添加是需要同步数据的,但是存储集中的话这个添加是不需要同步数据的。
2. 主从同步是基于WAL复制,从节点是没有写IO的。社区版从节点对底下的磁盘是有同样流量的写IO的。
3. 主从节点之间任何数据lO交互的,因为所有lO都落在了存储上,类似于oplog复制同步等耗时操作,在存算分离架构上是不存在的。如果从节点对主节点没有这种oplog的压力读取的话,理论上从节点的个数是无上限的,就是说从节点增加实际上并不影响主节点读写负载。因为主节点不需要对从节点做任何损耗性的操作。在这种情况下,我们可以支持百万级的ops的读能力。
4. 存算分离架构是基于RocksDB的。在这种架构的情况下, compaction可以卸载lO 负载到从节点。在这种情况下主节点,包括主节点自身的cpu和存储的消耗都是会被降低的,可以更进一步的为客户读写IO服务。
基于共享存储的分片集。在chunk的分裂就是数据分裂和迁移,即split chunk和move chunk这两种操作下, 不引起真实的IO,只更新config节点的原数据操作,就可以做到秒级的分裂和均衡。这种情况下对整个分片集的分片添加是很有好处的,因为基于分片的添加都涉及到rebalance或者是move chunk操作。而对于存算分离的架构来说,只需要按需的去添加shard或者缩减shard,秒级的分裂均衡,买的资源很快就可以上。
DDS在MongoDB源代码上的实践
因为MongoDB自4.0版本后修改了开源协议,未来我们将选取RocksDB作为 wiredtiger存储引擎替代,基于MongoDB 4.0版本继续开发独立演进的产品,未来除能兼容MongoDB 4.2和MongoDB 4.4的特性,同时会基于RocksDB开发新的独有特性,满足客户细分场景的诉求。
集群模式多文档事务支持
社区版MongoDB 4.0系列,只有副本集部署模式才支持多文档事务。华为云MongoDB内核团队打破了这一局限性,使得集群部署模式下也支持多文档事务。为了实现这一功能,mongos上增加了对Session的支持,mongos侧的Session对象跟踪事务执行的状态并路由到对应的Shard上执行。
集群模式下的事务使用方式与副本集上完全一致。相关的wiki可以参考DDS Cluster Multi-Doc Transactions,与该功能相关的提交可以参考mongos session。
DDS后续会基于此实现MongoRocks引擎的分布式多文档事务。
中文全文检索
国内用户使用MongoDB的痛点之一是,社区版MongoDB对支持拉丁语系的全文检索有比较好的支持,但是它不支持中文全文检索。在3.X系列MongoDB企业版支持中文全文检索,但是到4.X系列中文全文检索功能被官方移除了。DDS 已经实现并开源了此功能。
操作审计功能
MongoDB社区版并不提供操作审计的功能。然而操作审计是数据库安全领域的一个重要功能。DDS内置了操作审计功能,用户可以通过YAML配置审计的规则,也可以通过MongoDB的命令,在运行时动态修改审计规则。
对操作审计的更详细的说明可以参考操作审计wiki。
查询内存限制
MongoDB的内存消耗分为引擎层消耗和Server层消耗。引擎层消耗指RocksDB的BlockCache或WiredTiger的Cache消耗。可以通过storageEngine.wiredTiger.cacheSize或storageEngine.rocksdb.blockCache进行配置。但是Server层却没有类似的全局内存限制,因此在并发执行复杂查询时,容易OOM导致进程被kill掉。
DDS加了一组参数,可以限制Server层查询所耗费的总内存上限。
internalQueryStageMemUsageSwitch // 功能开关
internalQueryStageMemUsageMax // 查询计划可使用最大内存量
internalQueryStageMemUsageMin // 在内存满后,让一些小查询不受影响的最小内存使用量
用户可以通过serverStatus()命令监控到当前所有查询使用的内存量
> db.serverStatus()["Total Stage Memory"]
{
"AndHashStage": {
"ObjectCount": NumberLong("10"),
"StageMem": NumberLong("321443133"),
},
"OrStage": {
"ObjectCount": NumberLong("32"),
"StageMem": NumberLong("2143399881"),
},
...
}
数据库物理热备
根据MongoDB的官方手册,MongoDB支持基于mongodump的逻辑备份,以及基于文件系统(比如LVM)的物理备份。MongoDB 4.2企业版支持数据库层面的物理热备,和基于LVM的物理热备类似,但是相比于LVM,降低了使用复杂度。DDS 4.0也支持数据库物理热备。
总结
2021年的话我们要继续基于RocksDB存储引擎为主, 在存储架构层面,同时发展计算存储分离和计算存储混合两种产品形态。
在上层的事务阶段,我们要继续优化单shard事务的能力,适合于wiretiger和RocksDB引擎。在分布式事务上,主要是基于RocksDB去做分布式事务的开发。
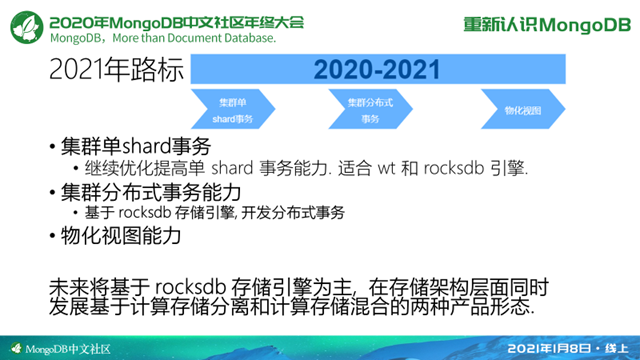
今天的分享大概就到这里。可以看到我们今年的这个路标实际上是也是很有挑战的,就是我们整个团队要去做这个分布式事务,然后基于全新的引擎去做这个事情,实际上我们也是求贤若渴,如果在座的各位同学,有哪些对数据库开发,尤其是这些底层的设计比较感兴趣的话也可以通过小芒果(WeChat ID:mongoingcom)联系我们。
分享嘉宾:
崔鑫,华为云DDS数据库架构师,十二年存储与数据库研发与运维经验。目前在华为云DDS团队领导GaussDB(for Mongo)和DDS的内核创新/研发/运维。
扫描下方二维码或点击链接:http://www.itdks.com/Home/Act/apply?id=5533 即可查看2020MongoDB中文社区线上年终大会更多嘉宾分享

关注社区公众号回复任意消息可获取大会PPT资料包




{kind=link}
评论前必须登录!
注册