 MongoDB中文社区
MongoDB中文社区

双11当天临近下班时间点,研发反馈出现应用定时JOB跑批任务卡死,导致数据没有及时计算出来,影响一次报表数据展示,这个功能跑了几个月基本上没有异常,双11业务增长几倍,数据量稍微有点大。主要包括如下内容:
- MongoDB集群架构以及读写分离策略
- 应用批处理异常时应用与数据库表现
- 数据库问题分析
- 如何规避与解决这个问题
MongoDB集群架构以及读写分离策略
MongoDB集群是基于3.6版本,其中底层是三个副本集的PSS架构+三成员的config+3个mongos组成.副本集都是设置tag,用于跑批程序到指定从节点计算数据,降低对主库的影响.其中一个副本集的当前配置如下:
shard2:PRIMARY> rs.config();{"_id" : "shard2","version" : 14,"protocolVersion" : NumberLong(1),"members" : [{"_id" : 1,"host" : "mongodb9.prd.db:31011","arbiterOnly" : false,"buildIndexes" : true,"hidden" : false,"priority" : 10,"tags" : {"usagep" : "production"},"slaveDelay" : NumberLong(0),"votes" : 1},{"_id" : 2,"host" : "mongodb10.prd.db:31011","arbiterOnly" : false,"buildIndexes" : true,"hidden" : false,"priority" : 9,"tags" : {"usages" : "reportsecond"},"slaveDelay" : NumberLong(0),"votes" : 1},{"_id" : 3,"host" : "mongodb11.prd.db:31011","arbiterOnly" : false,"buildIndexes" : true,"hidden" : false,"priority" : 1,"tags" : {"usagef" : "reportfirst"},"slaveDelay" : NumberLong(0),"votes" : 1}],"settings" : {"chainingAllowed" : true,"heartbeatIntervalMillis" : 2000,"heartbeatTimeoutSecs" : 10,"electionTimeoutMillis" : 10000,"catchUpTimeoutMillis" : -1,"catchUpTakeoverDelayMillis" : 30000}
【读写分离策略】
应用端15分钟多线程聚合一次数据,每次按照部门聚合,但是分片规则是基于单号hashed来做,每次40个线程同时跑(几千部门,数据分布不均衡),执行时间几十秒可以运算完成,但cpu瞬间能够达到60%-80%波动。为了降低对主库影响,读写分离策略经过三次变化:
- 第一阶段, 直接主库运行,但对主库有性能问题
- 第二阶段,采用readPreference=secondaryPreferred&maxStalenessSeconds=120参数,但MongoDB会将聚合任务下发所有备库进行执行任务,由于存在从库与主库共用机器的情况,cpu负载还是很高,对主库性能影响降低。
- 第三阶段,为了解决这个,双11扩容3个物理机器,每个机器跑独立实例,同时对副本集配置tag,将聚合任务分发特定tag实例,从而解决主库cpu高问题,同时能够控制聚合任务分发。MongoDB对外URL连接串如下:
mongodb://username:password@mongodb1.db.com:31051,mongodb2.db.com:31051,mongodb3.db.com:31051/exp?readPreference=secondaryPreferred&maxStalenessSeconds=120&readPreferenceTags=usagef:reportfirst&readPreferenceTags=usages:reportsecond&readPreferenceTags=&retryWrites=true
应用批处理异常时应用与数据库表现
【应用跑批异常】
根据研发反馈,11.11 17.11 跑批程序卡死(提前几分钟跑,其实是慢并没有真的卡死),于是手动kill应用程序,大约几分钟后,程序跑批成功,但是17.15跑批结果是丢失,主要在客户端用于生成曲线图,相当于少一个坐标点数据(影响不是非常大,但毕竟出现小异常)
【数据库端表现】
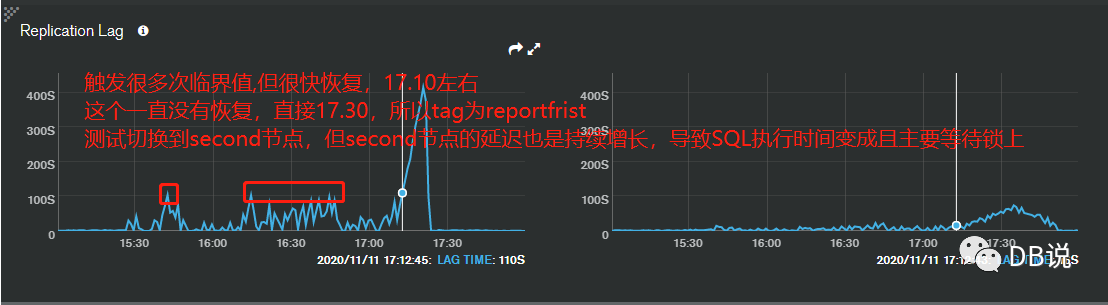
- 延迟分片节点监控信息(副本集中2个从库都有延迟,其中有1个延迟在120s,另外一个超过)


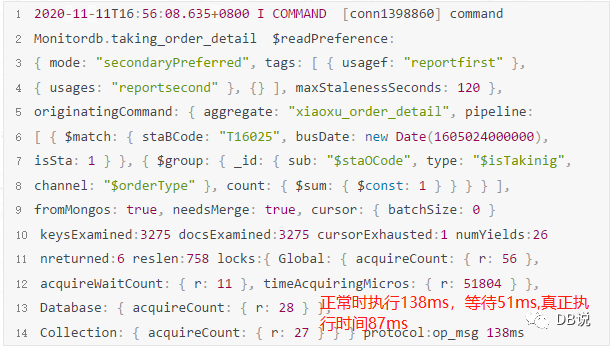
- mongod实例日志
备注:根据监控来看,tags等于reportfirst节点,在17.10延迟超过120s,所以跑批程序根据配置tag以及延迟时间120s自动切换reportsecond节点,但reportsecond也存在延迟,至少有20s到60s之间,出现应用跑批卡死了(应该不至于),查看SQL执行时间来看,正常执行100ms左右,变成24s,还有更慢的SQL,甚至超过几分钟的。所以应用端表现是卡死,因为后端执行慢。但SQL主要耗时在global锁等待上,而不是正在MongoDB执行时间上,这个是最主要原因(先分析表面的东西),从表现来看,就是延迟导致执行变慢,17点之前正常的。存在如下问题:
1、SQL执行被阻塞
【图一是tag等于frist节点日志】
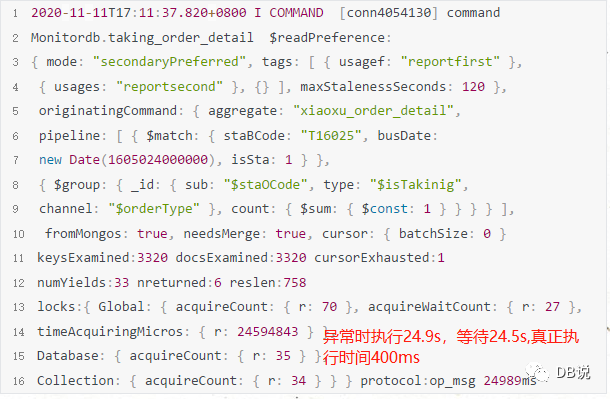
【图二是tag等于second节点日志因为切换到这个节点】
2、备库拉oplog日志一直失败且一直尝试切换数据源
【如下是tag等frist节点日志,一直拉取oplogs超时,因为second节点压力大,进行跑批操作,没有响应备库拉取oplog】


- mongod主库慢日志分析
备注:正常节点与异常节点,SQL执行时间基本上差不多,主要是执行次数不一样多。
【异常节点】

【正常节点】

数据库问题分析
【主从延迟原因】
根据官方解释主要包括如下:
- 网络延迟–同一套环境,环境环境相同,其他节点都没有这个问题,应该可以排除网络延迟问题
- 磁盘–从监控来,磁盘IOPS在40000-60000之间,所有机器性能差不多,没有特别大的异常,包括cpu都是相对稳定
- 并发–从监控来,17点到17.30出现连接翻倍的情况,这个可能会影响备库拉取oplog性能
- 写关注–应用采用默认策略,写入主库ack即可,所以这个不存在问题
备注:因为集群分片集合都是基于hashed,数据很均衡,没有出现分片节点数据差别很大的情况,所以目前主从延迟根因很难判断,主从延迟只是双11当天出现过,其他时间没有出现过。因为双11当天有限流,下午开始取消限流,可能导致数据库一瞬间波动造成的延迟(出现偶发的情况)
【SQL执行为什么会等待锁,被阻塞】
因为我们的聚合SQL对时效不是非常敏感,因为是多线程执行聚合,每一个线程按照部门等条件聚合的,有几百到几千部门,只是关注总时间,总执行时间在1分钟内(有的SQL都是毫秒级别),双11执行异常,分析具体慢SQL才发现很多主要等待在获取锁上,所以出现异常。查询官方文档以及mongodb官方博客,mongodb 4.0之前版本备库写会阻塞读,平时没有延迟所以备库阻塞读的时间非常短。

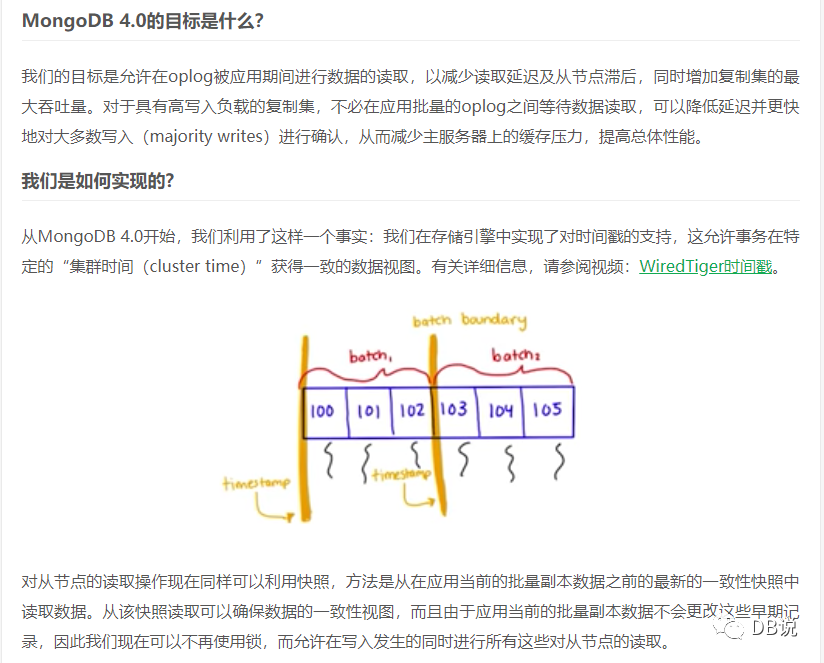
《https://www.mongodb.com/blog/post/secondary-reads-mongodb-40》
《https://mongoing.com/archives/13473》
【备库拉取oplog失败】
4.4版本之前都是备库主动去同步源获取日志,如果主库忙、网络出现问题,会导致拉取失败的,从而导致从库不能及时应用日志,如果开始级联复制(默认开启),那么此时备库可能从其他备库拉取日志,如果数据源也延迟,那么备库延迟概率与延迟时间会增加,我们此次遇到延迟,就是级联复制影响,从失败日志里面看虽然一直尝试切换同步源,最终还是选择的都是同一个同步源备库,根本没有切换到其他数据源,是否切换数据源(存在一些判断条件),如果主备都满足候选同步源时,此时选择的备库作为同步源,其中有一个参数maxSyncSourceLagSecs来触发再次选择同步源,这个值是30s,从监控来看17.20分,同步源本身延迟超过30s,最终将同步源切换到主库(原同步源被标识为invalid),延迟很快恢复。4.4版本采用stream replication,主动推动oplog。相对从库主动拉取能够提高效率,降低复制延迟。
如何规避与解决这个问题
4.0之前版本如果主库压力不大,不建议读写分离,因为写会阻塞读,除非对响应时间不是非常关注(备库可接受范围内)以及读取延迟数据(接受一定时间延迟),本次版本是3.6集群,我们是跑批业务且平时延迟很小,所以目前来看,读写可以接受。考虑明年升级到4.4版本。
【备库延迟问题】
- 做好主从延迟监控告警,及时发现潜在的性能问题,比如磁盘、主库性能等问题;
- 如果开启级联复制(默认开启),级联数据源压力比较大,那么也会导致拉取日志失败从而造成延迟,根据实际情况是否调整级联复制;
- 升级到4.4版本,开始支持streaming replication,变成主动推oplog,那么复制效率会提升。
作者:徐靖
物流快递行业数据库运维与技术研究,主要是Oracle,MongoDB,Mysql技术。




MongoDB中文手册翻译正在进行中,欢迎更多朋友在自己的空闲时间学习并进行文档翻译,您的翻译将由社区专家进行审阅,并拥有署名权更新到中文用户手册和发布到社区微信内容平台。
更多问题可以添加社区助理小芒果微信(mongoingcom)咨询,进入社区微信交流群请备注“mongo”。

长按二维码关注我们



评论前必须登录!
注册