 MongoDB中文社区
MongoDB中文社区
在我们电商参考架构系列的前三部分中,我们主要讨论了在电商领域两个实用的MongoDB应用:产品目录和库存系统。这两个应用都是非常传统的用户案例,MongoDB在其中作为一个相对静止、直接的数据集合的记录系统。例如,在系列的第一部分中介绍了产品目录,使用MongoDB存储和检索产品和他们系列的库存。
今天,我们将介绍电商领域中一个非常不同的MongoDB应用,一个即使很熟悉MongoDB的人也许都会认为不适合的应用:记录大数据量用户行为数据以及运行数据分析。最后的用户案例展示了MongoDB如何能够允许可扩展的精准营销数据分析,包括为您的顾客提供推荐及个性化。
行为日志
在电商领域,维护一个每位用户的行为记录为一个公司提供了获取对用户行为有价值、有前瞻性精准营销数据分析的方法,但是这将产生一定的成本。对于一个有着成千上万或者无数顾客的电商而言,记录所有用户基础产生的行为将会生成大量数据,以一种有用、可理解的方式存储那些数据变成了一个非常有挑战的任务。实现这项任务的理由是:每位用户的每个行为都有可能对我们来说是有意义的,例如:
- 搜索
- 产品浏览、产品喜好,产品关注
- 购物车的商品增加/移除
- 社交网络分享
- 广告效果
即使是从上面这个简短的列表中,我们也非常容易发现:就需要的成本/存储量以及一个公司使用一种有意义的方式利用数据而言,生成数据量的快速增长将会成为一个问题。毕竟,我们正在讨论潜在的、每秒成千上万的写操作,这意味着从我们的数据集中获取任何精准的营销数据分析,都需要尝试高效地从消防水管中饮水。然而,潜在的好处还是非常庞大的。
通过使用这种类型的数据,一个电商可以获取许多知识,将会帮助预测用户的行为和喜好用于增值销售以及交叉销售。简而言之,任何电商越能够很好地预测他们用户想要的商品,他们越能够有效地地推荐一个顾客购买他们或许想要购买的额外产品。
需求
对于MongoDB而言,为了达到用户应用场景的要求,我们需要它能够满足下面的需求:
- 每秒成千上万的写入:一般说来,MongoDB执行随机存取的写操作。在我们的应用场景中,这有可能会导致太多数量的磁盘存储碎片,因此我们使用HVDF(后面将会有更详细的介绍)来在一个只做追加的形式下顺序地存储数据。
- 灵活的模式:为了最小化存储空间的需求量,被记录的每个行为模式都被存储为和接收到数据相同的格式及大小。
- 在可变字段上的快速查询及排序:二级B树索引保证我们大多数一般查询和排序能在毫秒级内执行。
- 旧数据的易删除性:一般说来,在MongoDB中删除大量文档是一个相对而言比较昂贵的操作。在使用HVDF将数据分割到集合之前,我们可以将删除整个集合作为一个不受约束的操作。
数据模型
正如前面提到的,我们解决方案中的需求之一就是灵活模式的使用,以保证数据使用和接收到的数据相同格式及大小进行存储。然而,我们仍然需要花点时间来设计一个通用的数据模型来记录每一个用户行为。
下面是我们想要从所有样本中获取到的一些属性的例子:
{ _id: ObjectId(),
geoCode: 1, // used to localize write operations
sessionId: “2373BB…", // tracks activities across sessions
device: { id: “1234", // tracks activities across different user devices
type: "mobile/iphone",
userAgent: "Chrome/34.0.1847.131"
}
type: "VIEW|CART_ADD|CART_REMOVE|ORDER|…", // type of activity
itemId: “301671", // item that was viewed, added to cart, etc.
sku: “730223104376", //item sku
order: { id: “12520185", // info about orders associated with the activity
… },
location: [ -86.95444, 33.40178 ], //user’s location when the activity was performed
tags: [ "smartphone", "iphone", … ], // associated tags
timeStamp: Date("2014/04/01 …”) // time the activity was performed
}
这只是一个行为一种可能的形式。在这里,一个很重要的考虑就是只维护尽可能多的每种行为类型的必要信息,以最小化所需的磁盘空间。因此,每篇文档将会根据获取到的行为数据类型而变化。
大容量数据源(HVDF)
HVDF是由MongoDB的团队创建的一个开源框架,它能够使得在MongoDB中通过一个简单的REST API高效地验证、存储、索引、查询以及清除时间序列的数据变得非常容易。
在HVDF中,进来的数据由三个主要部分构成:
- 数据源:对应一个数据库。在我们的用户案例中,每个用户都有一个数据源来获取他们所有的行为。
- 信道:对应一个集合。每个信道表示一个行为类型或者被记录的来源。
- 样本:对应一个文档。每个被记录的用户行为都会被写入一个单一的文档中。
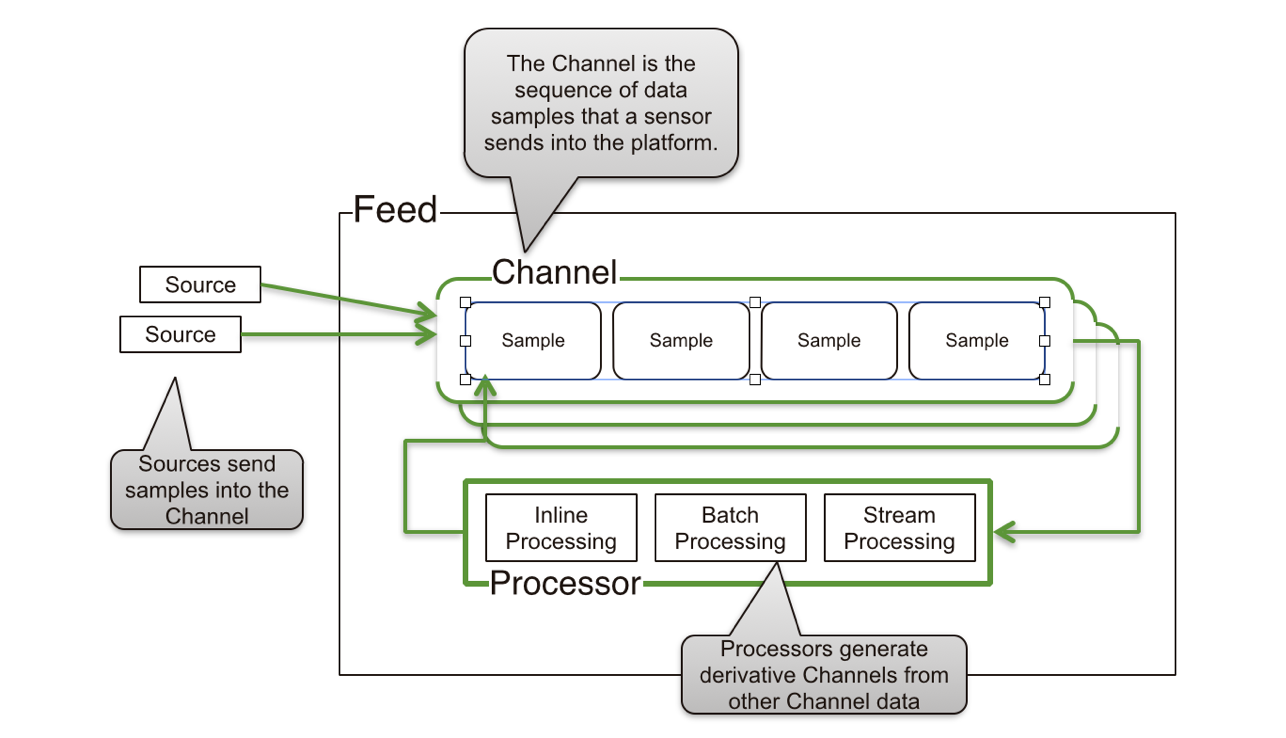
HVDF允许我们很容易地以追加方式来使用MongoDB。这就意味着我们的文档将会被序列化地存储,最小化了我们写入到磁盘时被浪费的空间。此外,HVDF还解决了大量配置细节,使得MongoDB对这种类型的大数据量存储更加高效,包括基于时间的分片以及禁止Power of 2 sizes 的磁盘分配策略。
有关HVDF的更多信息以及源代码可以在Github中获得。
时间分片
在我们的使用中,我们利用了HVDF时间分片的特性,通过在一个特定的时间间隔创建一个新的集合来自动根据时间对样本进行分片。这样做有四个优点:
- 顺序写入:由于一个新的集合是为每个时间间隔创建的,样本经常被顺序写入磁盘。
- 快速删除:通过将数据作为集合,删除本来就是无约束的。所有我们需要做的仅仅是删除这个集合。
- 索引大小:用户行为记录生成了大量数据。如果每个信道的所有样本都创建一个集合,那么这些样本的索引将会迅速变得非常庞大。通过将信道分片到时间间隔中,我们就能够使得索引足够小到能够放在内存中,这就意味着使用这些索引仍会非常高效。
- 为每个读操作进行集合优化:每个集合的时间间隔可以配置到与我们最有可能希望检索的时间间隔相匹配。一般说来,一个最佳实践是保持时间分片足够小,以保证它们的索引可以放入内存,但是足够大到能保证对给定的任一查询您只需要查询两个集合。
- 自动分片:HVDF在集合创建时自动为每个时间间隔创建一个片键。这就保证了对一个给定时间间隔的任意查询都是非常高效的,因为相同间隔的样本都被写到相同的分片中。

为了详细说明我们的数据如何基于时间的分片,我们简单地使用下面的语句进行我们的渠道配置:
{
"time_slicing" :
{
"type" : "periodic",
"config" : { "period" : {"weeks" : 4} }
}
}
在这个例子中,我们对HVDF进行了配置以实现每4周为每个信道创建一个新的集合。‘period’字段可以指定为年、周、小时、分钟、秒、毫秒或者是上述时间单位的任意组合。
设置_id
为了保证我们的查询非常高效,我们也需要对文档的’id’创建进行一定的思考。由于我们知道这些数据将会被用于执行有时限的用户分析,选择一个同时嵌入创建时间戳以及用户ID的’id’是非常合理的,HVDF使得这个非常简单。所有我们需要做的就是明确HVDF应该在信道配置时使用‘sourcetimedocument’ id类型的信道插件:
"storage" :
{
"type" : "raw",
"config" :
{
"id_factory" :
{
"type" : "source_time_document",
"config" : { }
}
}
}
```
This will give us an ‘_id’ that looks like this:
```
"_id" : {
"source" : "user457",
"ts" : NumberLong(324000000)
}
通过使用这种格式的’_id’,我们保证了对多数我们需要在数据上执行分析、最普遍查询的近似即时查询。
用户精准行销数据分析
既然我们已经了解了用户行为将会如何记录到MongoDB中,是时候真正介绍我们可以使用数据完成的工作了。第一件需要记住的事情是:正如前面提到的,我们正在尝试从消防栓饮水。获取这种类型的用户数据经常会导致庞大的数据集,因此我们所有的查询必须是有实效性的。幸亏有我们的时间分片,这不仅仅限制了每个查询涉及到的集合数目,也保证了被搜索数据的完整性。在处理TB级别的数据时,一个完整的表扫描根本是不现实的。
查询
下面是一系列我们可用于获取一些关于用户行为数据分析的简单查询,这些需要’userId’和’itemId‘的辅助索引:
- 一个用户最近的行为:
db.activity.find({ userId: “u123”,ts: {“$g”t:1301284969946, // time bound the query
“$lt”: 1425657300} })
.sort({ time: -1 }).limit(100) // sort in desc order
|
- 一个产品最近的行为:
db.activity.find({ itemId: “301671", // requires a secondary index on timestamp + itemId
ts: {“$g”t:1301284969946,
“$lt”: 1425657300} })
.sort({ time: -1 }).limit(100)
为了了解更多关于用户正在做的事情的精准分析,我们也可以使用MongoDB中的聚合框架:
- 用户最近的浏览数及购买数等
db.activities.aggregate(([{ $match: { userId: "u123", ts: { $gt: DATE }}}, // get a time bound set of activities for a user
{ $group: { _id: "$type", count: { $sum: 1 }}}]) // group and sum the results by activity type
|
- 一个用户最近的总购买量
db.activities.aggregate(([
{ $match: { userId:"u123", ts:{$gt:DATE}, type:"ORDER"}},
{ $group: { _id: "result", count: {$sum: "$total" }}}]) // sum the total of all orders
- 一个产品最近的浏览数及购买数等
db.activities.aggregate(([
{ $match: { itemId: "301671", ts: { $gt: DATE }}},
{ $group: { _id: "$type", count: { $sum: 1 }}}])
当然,这些查询的结果也许会告诉我们关于用户行为不同的方面。例如,随着时间的变化,我们也许可以发现相同的用户已经多次浏览了相同的商品,这就意味着我们也许可以在下次他们访问我们的网站时向他们推荐该产品。同样地,我们也许会发现由于一个降价或者广告促销某个特定的商品有一个销售量上面的突然上升,这就意味着我们也许可以更频繁地向用户推荐该产品以进一步推动销售。
在这里,曾氏销售也是一个非常大的机遇。例如,假设我们知道某个用户已经浏览了几个不同的低端手机,但是他们普遍的总销售量相对较高。在这种情况下,我们也许会推荐他们浏览一些在与他相似的用户中较受欢迎的、更高端的设备。
Map-reduce
使用MongoDB进行分析的另一个选择是使用map-reduce。与聚合框架相比,它对非常庞大的数据集而言是一个极佳的选择。这里有几个原因。以下面使用聚合计算所有单一访问者在过去一小时内某个行为的次数为例:
db.activities.aggregate(([
{ $match: { time: { $gt: NOW-1H } }},
{ $group: { _id: "$userId", count: {$sum: 1} } }],
{ allowDiskUse: 1 })
这里有几个问题:
- AllowDiskUse:在MongoDB中,任何包括超过100MB数据集的聚合都会抛出一个错误,因为聚合框架本来就是为在内存中运行而设计的。在这里, allowDiskUse属性通过强行将聚合在磁盘中运行来缓解这个问题,而正如你可以想到的,这种做法对一个非常庞大的数据集而言将会变得非常缓慢。
- 单一分片的最终分组:对任何系统而言计算是非常困难的,但是聚合框架有一个特殊的地方将会使得效率非常低。在一个分片的MongoDB实例中,我们的聚合必须在首先在每个分片中执行。接着,结果将会在主分片中重新组合,重新运行聚合以删除分片间的冗余。这对于一个非常庞大的结果集而言是非常昂贵的,特别是如果数据集大到需要使用磁盘来聚合的情况。
基于这些原因,尽管map-rduce并不总是一个比聚合框架更高效的选择,对于这个特殊的用户案例而言这是一个更好的选择。此外,这种实现非常简单。下面是一个使用map-reduce 运行的相同查询:
var map = function() { emit(this.userId, 1); } // emit samples by userId with value of 1
var reduce = function(key, values)
{ return Array.sum(values); } // sum the total samples per user
db.activities.mapreduce(map, reduce,
{ query: { time: { $gt: NOW-1H } }, // time bound the query to the last hour
out: { replace: "lastHourUniques", sharded: true }) // persist the output to a collection
在这里,我们可以在结果集合上执行查询:
- 某个用户在过去一小时内的活动数
db.lastHourUniques.find({ userId: "u123" })
|
- 过去一小时内的总数
db.lastHourUniques.count() |
交叉销售
现在,将所有内容整合。我们的分析最有价值的特性之一是能够为用户提供交叉销售产品的能力。例如,假设某个用户购买了一个新的iPhone。那么这里就有大量相关的、他也许有可能想购买的产品,例如保护套、屏幕保护膜以及耳机等等。通过分析用户的行为数据,我们可以真实地了解到哪些相关产品通常会被一起购买,然后将它们展示给相关用户以推动额外产品的销售。下面是我们如何实现的。
首先,我们计算某个用户购买的产品:
var map = function() { emit(userId, this.itemId); }
// emit samples as userId: itemId
var reduce = function(key, values)
{ return values; } // Return the array of itemIds the user has bought
db.activities.mapReduce(map, reduce,
{ query: { type: “ORDER”, time: { $gt: NOW-24H }}, // include only activities of type order int he last day
out: { replace: "lastDayOrders", sharded: true }) // persist the output to a collection
这将会返回一个包含了类似下面的文档输出集合:
{ _id: "u123", items: [ 2, 3, 8 ] }
|
接下来,我们在输出的‘lastDayOrders’集合上运行一个辅助map-reduce工作,以计算每个产品对的出现次数:
var map = function() {
for (i = 0; i < this.items.length; i++) {
for (j = i + 1; j <= this.items.length; j++) {
emit({a: this.items[i] ,b: this.items[j] }, 1); // emit each item pair
}
}
}
var reduce = function(key, values)
{ return Array.sum(values); } // Sum all occurrences of each item pair
db.lastDayOrders.mapReduce(map, reduce,
{out: { replace: "pairs", sharded: true }) // persist the output to a collection
这将会返回给我们一个包含了每个产品集被一起订购的次数统计输出集合。这个集合包含了类似于下面的文档:
{ _id: { a: 2, b: 3 }, value: 36 }
|
在这里,所有我们需要做的就是在每个产品和它们的计数上创建一个二级索引,例如:.{_id.a:”u123”, count:36}.。这将确定哪些产品用于交叉销售变成了一个检索这些最经常被一起订购的产品的简单查询。在下面的例子中,我们只检索那些和itemId为u123一起被订购次数超过10次的产品,然后使用降序进行排列:
db.pairs.find( { _id.a: "u123", count: { $gt: 10 }} )
.sort({ count: -1 })
我们也可以通过在一个单独的集合中对最受欢迎的产品对进行分组来使得数据变得更加紧密,例如:
{ itemId: 2, recom: [ { itemId: 32, weight: 36},
{ itemId: 158, weight: 23},
… ] }
Hadoop集成
对于许多应用而言,使用聚合框架用户进行实时数据分析和在MongoDB中对庞大数据集使用map-reduce功能用于不那么频繁的处理都是很好的选择,但是无疑地,对于真正大数据集合的复杂数值运算而言,Hadoop将是一个重要的工具。基于这个原因,我们已经为MongoDB创建了一个Hadoop连接件,使得在Hadoop的一个MongoDB集群中处理数据变成了一个非常简单的工作。下面是一些特性:
- 从MongoDB或者是导出的BSON中读/写
- 与Pig,Spark,Hive,MapReduce以及其它工具集成
- 与Apache Hadoop,Cloudera CDH以及Hortonworks HDP一起运行
- 开源
- 支持MongoDB查询、认证、从复制集标签中读取以及更多操作的过滤
如果想了解更多关于MongoDB Hadoop连接件的信息,您可以查看GitHub上的项目。
概要重述
不管是实时还是增量运行用户分析都不是小任务。如果希望系统能够很好地运行,这个过程中的每一步:从获取用户数据,到数据存储,到数据读取,再到数值计算都提出了需要有效计划的挑战。幸运的是,不管是单独使用还是与Hadoop之类的其它工具一起使用,MongoDB和HVDF是一个实现这些类型任务的优秀工具。
以上就是我们在电商参考架构系列四个部分的所有内容。在过去的四篇博客中,我们介绍了如何使用MongoDB实现大型电商一些最普遍、最复杂的需求,包括产品目录、库存以及查询优化。如果您想了解更多关于MongoDB的工具和案例,请查看我们的Github。
了解更多
为了进一步了解如何使用MongoDB重新开启你的零售商之旅,请阅读我们的白皮书。在这篇文章中,你将会了解新的零售挑战以及MongoDB如何解决它们。
为了了解MongoDB的咨询团队如何可以帮助您的应用更快起步,探索我们的开始启动指南。
翻译:周颖敏
审稿:TJ



mongodb 在电商里面的使用,可以参看下fecshop,是mongodb+mysql双数据库的电商系统。
Fecshop 全称为Fancy ECommerce Shop,是基于php Yii2框架之上开发的一款优秀的开源电商系统,遵循BSD-3-Clause协议(和Yii2框架一样的开源协议), Fecshop支持多语言,多货币,架构上支持pc,手机web,手机app,和erp对接等入口,您可以免费快速的定制和部署属于您的电商系统。
详细参看地址:Fecshop介绍
Fecshop 官网:http://www.fecshop.com ,您可以在这里提交bug,问题咨询等等。
Fecshop PC Demo:http://fecshop.appfront.fancyecommerce.com/
Fecshop Mobile Demo:http://fecshop.apphtml5.fancyecommerce.com
Fecshop 后台演示地址:加QQ群,在群公告里面有后台演示地址,账号密码等信息
Fecshop QQ群:186604851 ,入群验证:fecshop
Fecshop 作者QQ:2358269014
FecShop Email:2358269014@qq.com
Fecshop Github地址: https://github.com/fancyecommerce/yii2_fecshop