 MongoDB中文社区
MongoDB中文社区
大数据问题
众所周知,数据量正在以无法估量的速度迅速增长。如果能对数据进行高效的利用,我们可以从中获得非常有价值的视角。而传统的技术,像关系型数据库管理系统,许多都是在40年前设计的,并不足以实现“大数据”大肆宣传下的商业价值。使用大数据技术的一个典型案例是:“客户的360°视图” -整合您所知道的、关于某个客户的所有信息来优化您与客户之间的参与度,从中获取收益,例如,准确决定在什么时间通过什么渠道向用户发送什么推广信息。
然而,其中非常大的问题在于:什么样的架构和解决方案将会帮助我们实现这些潜在的可能性。高级的关键功能需求至少包括以下几个能力:
1. 聚合跨信息孤岛的、流式和持久化数据
2. 管理数据读取
3. 根据需求转化数据
4. 聚合数据
5. 提供分析数据的工具
6. 数据报表
7. 将洞察与操作流程相结合
8. 在最小的总成本和响应时间内做到以上几条
数据湖(Data Lake)作为解决方案
许多企业正在调研一个被称为数据湖的架构,它是一个灵活的数据平台,可以在单一的[逻辑]位置聚合跨信息孤岛的[流式和持久化]数据,并且可以跨企业内部和第三方数据来挖掘和获取对未来情况的预知。使用Hadoop(包括Spark)作为数据湖有很多原因。它利用低总成本的商业硬件来进行水平拓展,允许读时模式(schema-on-read)(用于接收高可变的数据),开源,并且包含了SQL和通用语言的分布式处理层。此外,像Yahoo和谷歌之类的互联网公司都在早期使用数据湖成功解决了索引网页时碰到的问题。
Hadoop 中的数据持久化选项
经过上面的铺垫,接下来可以开始介绍数据湖的解决方案了。当你从一个更深的层次开始理解Hadoop是什么的时候,您会发现它其实是涉及到数据处理的不同方面、范围的一系列项目。当我们开始探究在使用Hadoop的数据湖中存储数据的方式时,有两个基本选择:HDFS和HBase。使用HDFS,您可以决定如何在只追加的文件中编码你的数据,从JSON到CSV,到Avro以及其它编码方式。当然,这完全取决于您,因为HDFS只是一个文件系统而已。相反地,HBase是一个数据库,有对数据编码的特定方式,已经为快速写入记录,和仅通过主键查询时相对快速读取进行过优化。
这里就是单独使用Hadoop的数据湖的迷人之处,与现实中的技术实现交汇之处,我们就可以开始基于上面列举出来的高级需求来评估Hadoop的能力了。您仍然可以利用Hadoop生态系统中的分布式处理层,像Spark和Hive,而不使用HDFS或者Hbase,从而选择与分布式处理层分离的持久层。例如,您可以查阅我之前 关于 使用Spark DataFrame和MongoDB数据进行读取和写入的博客。同样地,另一篇博客也展示了如何将MongoDB作为另一个写入或读取的Hive表。
索引依然重要
大部分熟悉关系型数据库管理系统的技术人员都意识到:富有表现力的查询能力和辅助索引加速查询是非常有价值的(虽然关系型数据库管理系统固定的模式、高总支出成本和有限水平扩展使其很难被用于数据湖)。如果我们只使用HDFS和HBase用于数据湖持久化,我们将获取不到我们希望数据库提供的特设索引所带来的优势,并且显然会受到一些局限:
1. ad hoc 切片 – 我们如何不借助辅助索引高效地分析由主键以外的其他东西才能代表的数据切片,例如:在那些花费超过X的最佳客户上运行分析?我们将会受到扫描数量庞大的数据以查找最佳用户这个过程的限制。
2. 低延迟报表– 如果我们没有灵活的索引,我们如何在秒级响应时间以内提供用户所需要的、所有有价值数据的报表?同样地,我们只能使用一个客户的账户号或者其它主键快速生成报表,而不是使用客户的名字、电话、邮编及花费等。值得注意的是,MongoDB刚发布了一个商务智能连接件(MongoDB BI Connector)用于任何基于SQL的报表工具与MongoDB集成工作。
3. 运营化– 同样地,在没有灵活索引的情况下,我们如何将有价值的洞察应用到运营型应用中?这些应用将在最大程度上影响公司和客户,以及影响我们提炼数据。想象一个客户服务代表(CSR)告诉一个客户他/她必须提供一个账户号来查找他们的所有信息,因为数据湖只支持一个主键,否则在所有数据中扫描他们的信息将会花费10分钟。
当然,也有解决这些问题的变通方案,但是它们会带来更高的总支出成本,需要更多的开发或运维投入,以及/或者更高的延迟。例如,您可以使用一个搜索引擎或物化视图来进行查询,而不使用主键,但是你就必须返回数据库,带上完整的记录,重新向主表发送一次请求,才能获取所有您需要的数据。除了延迟问题,它还需要更多的管理,开发投入,以及/或者基础设备来使用单独的搜索引擎来维护物化视图,还有将数据写到其它地方的带来的不必要的一致性问题。拥有我们习惯的、正常且灵活索引的同时,维持我们的设计原则不是很好吗?
MongoDB是一个高效的数据湖必不可少的部分
我们从探究单独使用Hadoop是否能够满足数据湖的需求开始讨论,并且发现了至少三个缺点。我们是否可以向架构中增加另一个持久层,来填补这些缺陷并且与我们的设计原则(使用低总成本的商业硬件,开源模型,读时模式(schema-on-read)以及Hadoop的分布式处理层)保持一致呢?
我选择写这个主题,也是因为MongoDB是在单一Hadoop数据湖中填补这些缺陷的最佳数据库。如果您使用另一个开源NoSQL数据库,您将会发现他们大部分都没有辅助索引(即使有,它们也并不能与数据保持一致(例如,不同步)),它们在数据库中也没有group-by和聚合操作。您可以使用一些这样的数据库向数据湖中写入数据,但是如果您也希望根据业务需求使用辅助索引以灵活的方式并发读取,它将会达不到您的需求。如果您在数据湖中使用一个开源的关系型数据库管理系统,我们也已经提到过:它们固定的模式及昂贵的垂直扩展模型与数据湖的设计原则相违背。
因此,下面的图表是一个数据湖的推荐架构。
MongoDB整合到数据湖
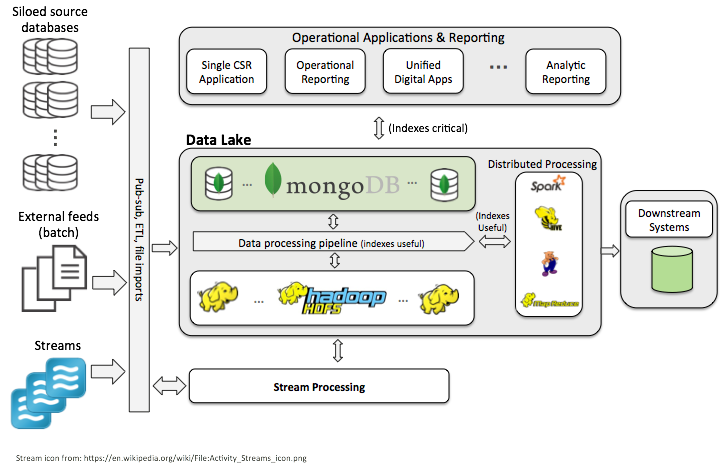
这个架构加入MongoDB作为一个持久层,可以用于存储任何因为以上提到的3个原因而需要索引,进而需要富于表现力的查询的数据集。我推荐使用一个控制函数根据来自客户的数据需求来决定是否将数据发布到HDFS以及/或者MongoDB上。不管您是否想将数据存储到HDFS或者MongoDB上,您都可以运行分布式处理工作,例如,Hive和Spark。然而,如果数据存储于MongoDB上,您可以在数据的ad hoc切片上高效地运行您的分析,因为可以直接将过滤原则推送到数据库中,而不像HDFS那样要在文件之间进行扫描。同样地,MongoDB中的数据也可用于实时、低延迟的报表,并且作为运营数据平台,为那些您可能会构建的互动系统及数字化应用提供服务。
我发现一些公司如今正在将他们的数据拷贝到Hadoop中,对数据进行转化,然后将数据拷贝到其它地方进行一些有价值的运算。为什么不直接在数据湖中直接获得大部分价值呢?通用MongoDB,您可以使数据的价值成倍增加。
总结
如果从短期和长期角度来看这些需求,数据湖是非常有价值并且可行的,并且它能够保证您使用基于核心Hadoop发行版以及基于整个生态系统(例如MongoDB)的最佳工具来实现这些需求。据我所知,有些公司已经开始通过花费一年的时间清洗它们的数据并且将其写入HDFS来启动数据湖,希望将来能够从数据中获取价值。然而,业务常常因为看不到价值而受阻,事实上,另一个批次层级存在于它们和客户之间。
您可以通过组合Hadoop和MongoDB保证您数据湖的成功,从而获得一个低的总成本、对所有用户而言最佳响应时间的灵活数据平台,包括数据科学家、分析人员、业务用户以及客户本身。通过数据湖,您和您的公司都可以期待从数据湖中获取独特的洞察,高效地与用户互动,提炼数据,提高您的竞争力。
观看Matt关于企业数据管理的报告以了解更多关于数据管理,必要功能集,和未来架构设计的常见挑战。
了解更多关于企业数据管理
关于作者- Matt Kalan
Matt是MongoDB 经验丰富的高级方案架构师,使用技术手段帮助各行业超过500个客户解决了业务问题。他最近专注于指导企业在快速变化的市场中,从包含噪音的数据中最大化企业数据管理(EDM)的商业价值。在进入MongoDB之前,Matt在北美开发了Progress软件公司的Apama算法交易和复杂事件处理(CEP)平台业务,接着销售了范围更广的运营智能解决方案。他之前还为Caplin集团销售过解决方案,主要用于在网络中流式化实时市场数据传送到FX和FI端口;他还为Sapient工作过,向全球2000强客户提供咨询服务。
翻译:周颖敏
审核:张耀星
原文链接:https://www.mongodb.com/blog/post/the-future-of-big-data-architecture



评论前必须登录!
注册