 MongoDB中文社区
MongoDB中文社区
原文链接:https://www.mongodb.com/blog/post/appsee-shapes-the-mobile-revolution-with-real-time-analytics-service-powered-by-mongodb
200亿文档,15TB数据存储于云上的MongoDB集群。新增App每月增加10亿+数据点。
在一些国家总共上网时间中90%以上是花费在移动设备上,提供完备的app体验变得非常必要。Appsee是一家新一代的移动行为分析公司,它向业务主体提供关于用户行为的深度洞察,使它们能够获得更高的参与度,转化率和营收。它们的客户包括eBay,AVIS,Virgin,Samsung,Argos,Upwork等等。Appsee在Google的Fabric平台中也十分受欢迎。仰仗MongoDB的能力,Appsee首先大量录入从移动App收集到的时序会话数据,然后设法找出其中的真意。
我与Yoni Douek,Appsee的CTO和联合创始人,进行了一次会谈以了解详细情况。
可以告诉我们一些关于贵公司的情况吗?
Appsee是一个实时移动App分析平台,它向客户提供我们称作“定性分析”的服务。我们的目标是通过一系列工具帮助公司理解用户是如何使用他们的App的,然后公司可以知道如何改进。传统的分析工具只帮助你看到数字——我们还提供了这些数字背后的原因。
Appsee的其中一个关键的定性工具是会话记录和重放,它能帮助我们的客户精确地了解和描绘他们的用户真实的使用体验。同时我们也提供触控热点地图,它向客户高亮显示了用户在每一屏是具体与哪个区域互动的,以及在哪里用户经历了使用性问题。此外我们的平台也提供了实时的分析,用户流,用户体验洞察,崩溃统计,和其他很多可以帮助公司优化他们的App的洞察信息。
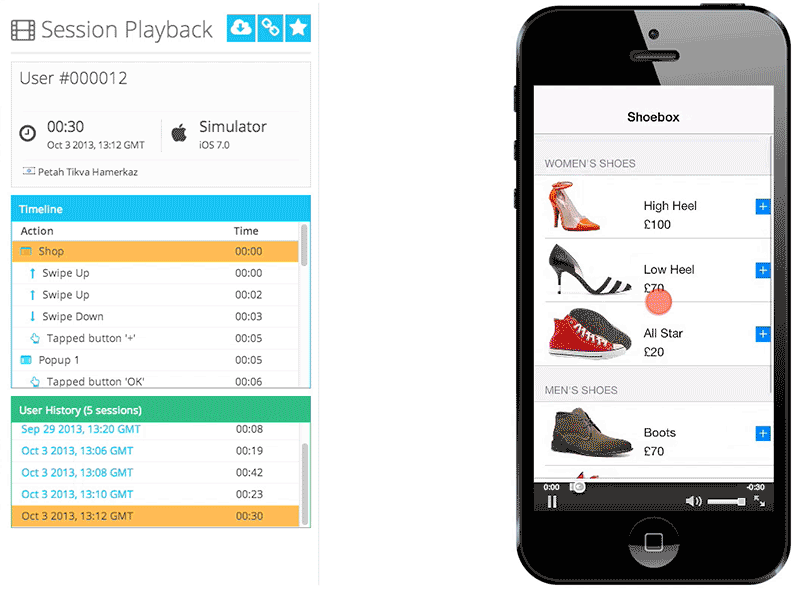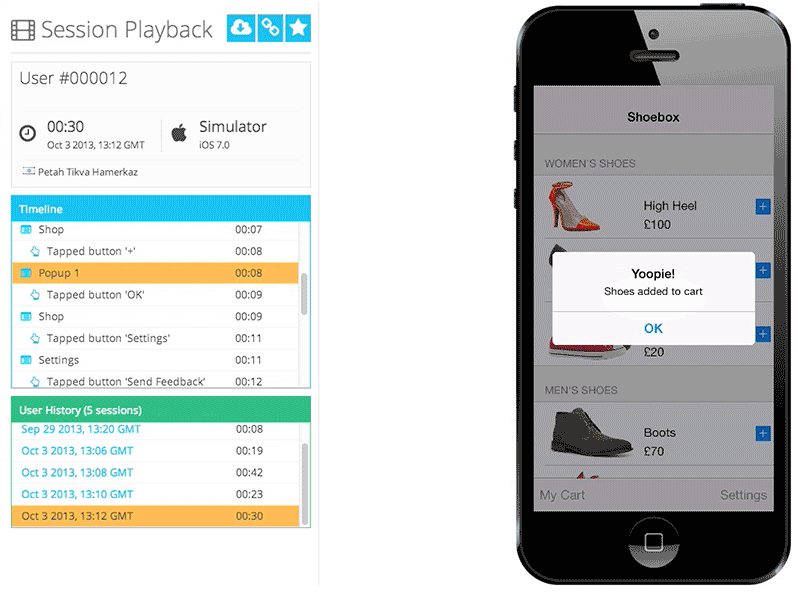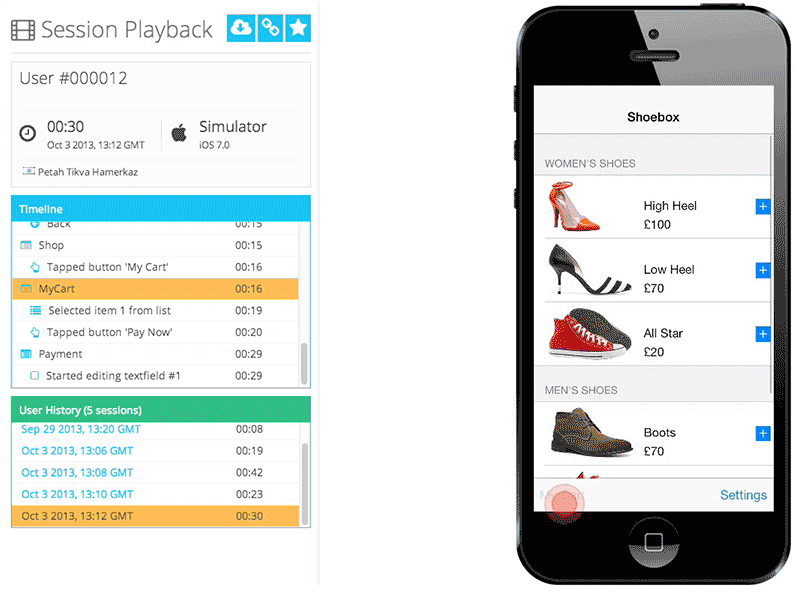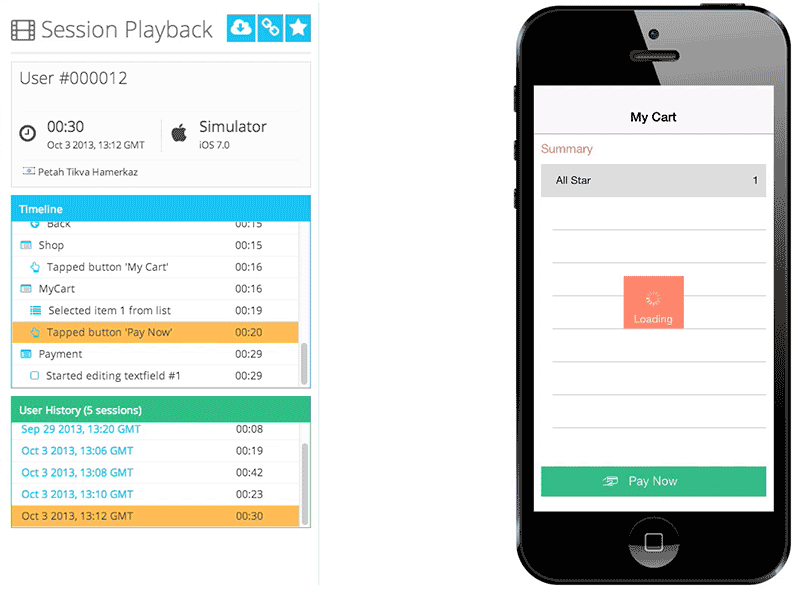 Figure 1: Appsee session replay provides developers with deep customer experience insights Figure 1: Appsee session replay provides developers with deep customer experience insights |
请介绍一下你们是如何使用MongoDB的
我们的服务有两种不同的数据存储需求,它们都是由MongoDB完成的。
会话数据库:存储每个用户与移动应用互动时产生的动作数据。会话数据被作为时序数据流抓取并存入MongoDB,包括用户访问了哪一屏,多长时间,轻击或挥动了什么元素,崩溃情况,等等。这份原始的数据被建模到单个文档中,典型大小是6KB。完整的用户会话可以通过这个MongoDB文档来重建,这样App专家可以以视频形式查看这次会话,进而了解如何优化他们的App体验。
实时移动分析数据库:会话数据被聚合并存储在MongoDB中以提供深层用户行为分析。通过50多个表格和图表,App拥有者可以跟踪一系列的关键指标,包括:总安装数,App版本分布情况,用户留存率,以及更多。
我们大规模使用了MongoDB聚合框架,基于它实现对原始数据的匹配、分组、投影和排序,再配合使用大量的聚合函数和数组操作表达式来转换和分析数据。MongoDB的二级索引允许我们高效地从不同维度和查询模式访问数据。我们的每个集合上通常都有3到4个二级索引。
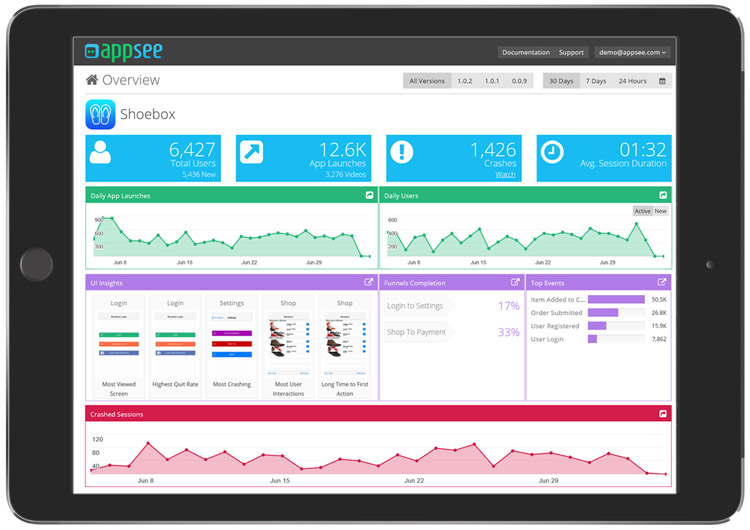 Figure 2: Appsee dashboard provides qualitative analytics to mobile app owners Figure 2: Appsee dashboard provides qualitative analytics to mobile app owners |
为什么选择了MongoDB?
当我们开始开发Appsee服务的时候,我们对数据库有一个非常长的需求列表:
- 弹性伸缩,要能为用户和数据增长提供几乎无限制的扩展能力。
- 时序数据要求非常高的插入效率,同时又需要非常低的读延迟以便提供分析能力。
- 可靠的数据存储以确保永远不会丢失任何的用户会话。
- 灵活的数据模型以便持久化高度复杂的,迅速改变的,由新一代移动应用所产生的数据。
- 对开发友好,以便最大化团队的开发效率,以及缩短投入市场所需的时间——那时我们只有2个开发人员。
- 拥有丰富的数据库内建分析能力以便我们可以为App拥有者提供实时的洞察信息,而不需要把数据移动到单独的分析结点或数据仓库中。
由于我们都来自于关系数据库背景,我们一开始考虑过MySQL。但受制于关系数据模型的约束,并且不可能将写操作扩展到一个结点之外,导致我们认识到它不能满足我们的需求。
我们比较了很多NoSQL替代品,很快就意识到能满足我们需求的最好的泛目的数据库是MongoDB。它的快速处理高速时序数据流的能力,和原地分析的能力是其中的关键。而且这个数据库由一个充满活力和乐于助人的社区所支持,同时又有详尽的文档能够帮助我们平缓学习曲线。
能描述一下你们的MongoDB集群是什么样子的吗?
我们目前正运行着一个5个分片的MongoDB集群,每个分片由3个结点的复制集来提供服务,提供了自愈能力。我们的集群运行在CPU优化型的AWS Linux实例上。
我们使用MongoDB 3.2,使用Python和C#驱动,正计划今年晚些时候升级到最新的MongoDB 3.4。这会帮助我们用上新版本支持的并行chunk迁移,以便我们在进行弹性扩展时能够更快地进行集群均衡。
能够分享一下MongoDB性能表现怎么样吗?
MongoDB目前存储着200亿文档,大约15TB数据,我们计划在未来12个月内翻倍。集群目前每秒处理约50000次操作,读写比例大约是1:1。通过压力测试,我们知道目前的集群还能承受2倍的数据增长。
能分享一下水平扩展的最佳实践吗?
我的第一条建议是在你实际需要分片前就建好分片——这能保证在面对突然的需求增长时你能够拥有足够的处理能力。别等到目前的配置快达到最大使用率的时候才想到分片。
为了让我们的水平扩展听起来不那么抽象,每个使用了Appsee并且上线的App几乎都能在上线之初的每一个月向我们发送10亿+的数据点。每隔几周我们就跑一次压力测试来模拟处理我们目前2倍的数据。根据那些测试结果,我们调整分片,集合和服务器以便我们始终可以应对2倍的压力。
你们如何监控集群?
我们使用Cloud Manager来监控MongoDB,而我们自己其他的应用监控系统是基于Grafana,Telegraf和Kapacitor构建的。
 Figure 3: Appsee heat maps enable app designed to visualize complex data sets Figure 3: Appsee heat maps enable app designed to visualize complex data sets |
你是如何测量MongoDB对你们业务的影响的?
从市场响应速度,功能多样性,用户体验和平台效率。
使用MongoDB我们可以更快地构建新的特性和功能。当我们聘用新的开发工程师时,MongoDB University培训和文档能让他们在几天内快速进入状态。
MongoDB简化了我们的数据构架。它是一个真正意义上的泛目的平台——支持时序数据的高速消化,同时整合了对这些数据的丰富的分析能力,而且还不需要用到数据库以外的其他技术。
我们的服务能够维持很高的可用时间。使用MongoDB的分布式,自愈性复制集架构,我们在AWS上的不同的可用区和区域部署集群以获得错误容忍和升级0当机能力。
每一代MongoDB都带来更高的效率。例如,升级到WiredTiger存储引擎帮助我们一夜之间节省了30%的存储花销。
MongoDB研发是开放和合作的——给予了我们帮助MongoDB团队摸索产品定位的机会。通过MongoDB的JIRA项目,我们直接与MongoDB工程师团队互动,提出功能请求和缺陷报告,就好像MongoDB工程师是我们团队的一部分一样!
Yoni,感谢你花费宝贵的时间分享公司经验。
关于在AWS上部署和运行MongoDB的更多最佳实践,请下载我们的指南。



评论前必须登录!
注册