 MongoDB中文社区
MongoDB中文社区
MongoDB 实例的内存使用率是一个非常重要的指标,内存使用率过高会导致 MongoDB 实例的内存溢出。本文主要通过查看 MongoDB 实例内存使用率的方法,让 MongoDB 的使用者尽快发现内存方面出现的问题并采取相关的应对措施。
在 MongoDB 启动后,我们都知道不光加载了二进制中的文件到内存中,同时负责内存的分配和释放的工作。
如:各个客户端连接和请求,默认情况下 MongoDB 使用的内存分配的方法是通过 tcmalloc 来进行分配,内存主要被 wiredTiger 数据库引擎以及客户端连接请求使用。
MongoDB 如何使用内存?如何判断数据库内存在正常的状态范围?
MongoDB 默认设置内存的方式是 (实际的内存减 – 1GB)/ 2 ,MongoDB 在自己的数据引擎 wiredTiger 中使用内存的情况下,同时还要使用 Linux 文件系统的内存。
所以在大部分情况下,可以让 MongoDB 自我进行内存的设置选择。
通过 db.serverStatus().mem 可以看到几个值:
- resident:这个值是 MongoDB 本身使用的内存
- virtual:这个值是 MongoDB 使用的虚拟内存的大小,这里包含了 Linux 系统中 MongoDB 程序使用的 SWAP (如果开启了 ),以及使用的 Linux file system 内存(包含分配和并未使用的)

为什么 MongoDB wiredTiger 不和 Oracle 、MySQL InnoDB 将内存设置为整体内存的 60% – 80%?而是 50% 不到?
主要的一个原因是,MongoDB 的数据是压缩应存储到磁盘上的,数据需要缓冲到 Linux 的系统缓冲 Cache 中加速文件的解压和获取。所以将 wiredTiger 的 cacheSize 设置的很大,将其和 Oracle 或 MySQL 的设置的方式类比,那么一定不是一个好的主意,可能会降低系统的性能。
MongoDB 在除了以上内存的使用方法以外,还有另外一些内存的使用方法:
- 在数据库操作 commit 时,数据并不是立即刷到磁盘中,而是有对应的缓冲来在脏页刷新到磁盘前,进行数据的缓冲。
- MongoDB 是一个支持 MVCC 的多版本控制的数据库,所以在操作时,数据行的多个版本是要存储在内存中。
- 客户的连接,以及聚合操作等内存的消耗。
那么在 MongoDB 持续的使用中,如何判断内存是否缺少?
这里通过 db.serverStatus().wiredTiger.cache 命令捕获下面的一些数据,可以来判断内存的使用情况。
wiredTiger.cache.bytes.currently in the cache这里的数据一般设置到 wiredTiger.cacheSize 的值的 80%,wiredTiger 会尽量将使用率达到wiredTiger.cacheSize的80%,bytes dirty in the cache cumulative与wiredTiger.cache.bytes.currently in the cache 都会在这里面包含。

WiredTiger.cache.tracked dirty bytes in the cache这个值是脏数据驻留在 wiredTiger cacheSize 里面的大小,如果这个值对比 wiredTiger cacheSize 的设置内存值超过 5% 的容量,同时通过工具 mongostat 持续观察其中的指标 dirty 在 20%,会得出两个可能:
- 磁盘系统不能满足当前的业务在 MongoDB 中的使用
- 进行添加其内存
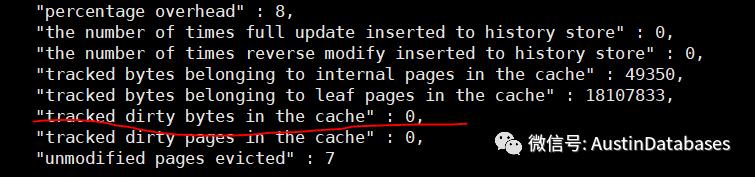
WiredTiger.cache.pages read into cache这个值是一个动态值,需要不断的判断一个时间间隔中这个值的变动,例如每秒,这有助于判断当前数据库页面读取到内存的状态是如何,波动是怎样,从一个数据不断的写入的状态来判断内存是否过小。
这一秒的值减去上一秒的值 ,就是这一秒的数据的读取量。

同时还可以针对读写事务的 available 进行监控,如果此时 available 的数量不足或过少,也可以在针对内存的问题进行确认,内存的缺少也会引擎 available 不足的情况。
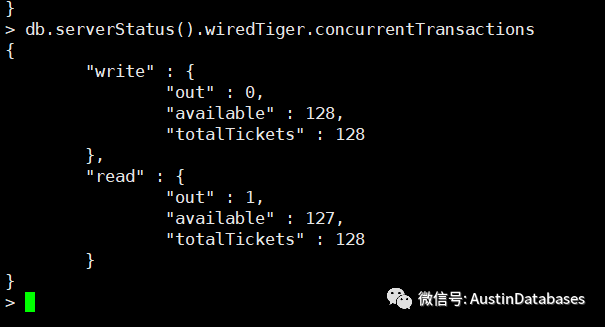
db.serverStatus().wiredTiger.cache['maximum bytes configured']db.serverStatus().wiredTiger.cache['bytes currently in the cache']db.serverStatus().wiredTiger.cache['tracked dirty bytes in the cache']db.serverStatus().wiredTiger.cache['pages written from cache']db.serverStatus().wiredTiger.cache['pages read into cache']
以上的 5 个值可以计算是否缺少内存(需建立在没有设置 cacheSize 的逻辑上进行工作)

通过 maximum bytes configured 来获知当前 wiredTiger 设置的 cacheSize 大小, 根据 MongoDB 的 wiredTiger 分配 cacheSize 的原则。
- 计算总体的内存(内存 – 1)/2 = 3. 3G 目前整体内存在 7.6G
- 3.3G 的内存在 bytes currently in the cache 可以趋近与 3.3G ,一般控制在整体cacheSize 的 80% 及以下。3.3G * 0.8 = 2.6G
- tracked dirty bytes in the cache 的值应该在 cacheSize 的 5% 以内,这个值在165MB 左右
- 同时比较 pages written from cache 和 pages read into cache 两个参数,通过间隔获取这两个数据库,来分析每个时间段流入到 MongoDB 的内存的数据和刷出的数据,可以做一个比值,通过查看工作繁忙期间的比值来判断是否有数据刚刚写入到内存后,就被刷出的可能,来判断是否缺少内存。
除此以外我们一般评判一个数据库中的内存是否正常还有一个可以参考的值就是 buffer hit ratio ,缓冲命中率。
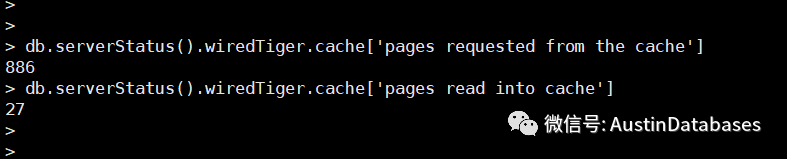
这里通过定时获取下面两个参数的增量,然后进行计算。
db.serverStatus().wiredTiger.cache['pages requested from the cache']db.serverStatus().wiredTiger.cache['pages read into cache']
我们以 2 秒为一个取数点,将 page requested from the cache 的值减去上一个 2 秒的值,作为一个增量,通过针对 page read into cache 也是一样的处理方式。然后将第一个值 / 第二个值 * 100 = buffer cache hit ratio 来查看当前数据在 cache 中的命中率。
除此以外,MongoDB 的内存使用还与我们的额实例的连接数有关,如果连接数很大的情况下,会消耗一部分的内存,主要的原因:
- 每个客户连接 MongoDB 的线程会消耗不超过 1MB 的线程栈,通常情况下在几十到上百KB
- TCP 连接到内耗层面有读写的缓冲区,连接越多使用的连接缓存越大,占用的资源越多
- 在连接的使用中,在连接释放后,释放后的的内存并不会马上释放给 MongoDB 而是交还给 tcmalloc, 而系统并未回收到相关内存我们通过 db.serverStatus().tcmalloc 可以分析当前有多少内存作为 Cache 在 tcmalloc 中存在,其中包括 pageheap_free_bytes + total_free_byte 为当前可以进行在分配的内存。
- 版本较低的 MongoDB 在处理文件打开等情况中会产生文件句柄,产生文件句柄后并未及时回收释放给OS系统,导致元数据问题占用部分内存,无法回收。这里建议将 MongoDB 升级到 4.2 及以上版本。同时基于版本的问题,之前的复制集合之间是通过串行来进行导致从库在创建索引时会消耗更多的内存用于数据的操作和回放, MongoDB 4.2 后改用并行的方式提高了回放的效率。
- 执行计划消耗内存的问题,对比上面的问题这个内存的消耗并不是很大,通过系统命令 db.serverStatus().metrics.query.planCacheTotalSizeEstimateByte 来查看相关的内存使用情况。
实际上 MongoDB 使用中注意连接数和连接的使用情况,如聚合或者全表扫描的场景尽量避免,争取更短小的事务在 MongoDB 中运行,提高数据库的性能和利用的效率。
关于作者:刘华阳
MongoDB 中文社区成员;
数据库爱好者18年,MongoDB 狂热粉丝;
曾经任国产某数据库产品经理,目前某互联网餐饮公司数据库部门负责人;
PostGreSQL ACE、Austindatabases 公众号写手;
熟悉 PostGreSQL、MySQL、MongoDB、SQL Server 等数据库。
感谢大家一直以来对社区的关注与支持!社区在大家共同的努力下不断的发展与壮大,为了给大家营造更便捷的交流环境,QQ 技术交流群将同步在“微信技术交流群”中。扫描下方二维码添加小芒果微信发送“mongo”即可进入技术交流群。



评论前必须登录!
注册