- 聚合 >
- 聚合管道
聚合管道¶
The aggregation pipeline is a framework for data aggregation modeled on the concept of data processing pipelines. Documents enter a multi-stage pipeline that transforms the documents into aggregated results.
The aggregation pipeline provides an alternative to map-reduce and may be the preferred solution for aggregation tasks where the complexity of map-reduce may be unwarranted.
Aggregation pipeline have some limitations on value types and result size. See 聚合管道的限制 for details on limits and restrictions on the aggregation pipeline.
管道¶
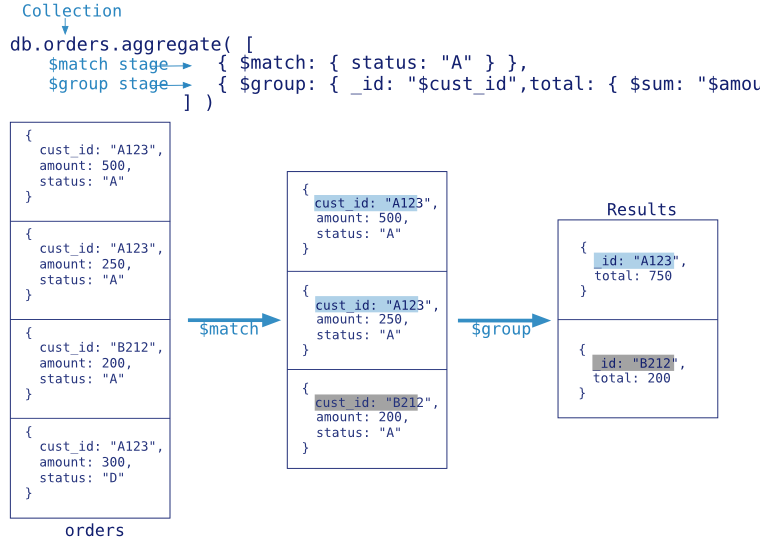
The MongoDB aggregation pipeline consists of stages. Each stage transforms the documents as they pass through the pipeline. Pipeline stages do not need to produce one output document for every input document; e.g., some stages may generate new documents or filter out documents. Pipeline stages can appear multiple times in the pipeline.
MongoDB provides the db.collection.aggregate() method in the mongo shell and the aggregate command for aggregation pipeline. See Stage Operators for the available stages.
For example usage of the aggregation pipeline, consider 对用户爱好数据做聚合 and 邮政编码数据集的聚合.
管道表达式¶
Some pipeline stages takes a pipeline expression as its operand. Pipeline expressions specify the transformation to apply to the input documents. Expressions have a document structure and can contain other expression.
管道表达式只可以操作当前管道中的文档,不能访问其他的文档:表达式操作可以在内存中完成对文档的转换。
Generally, expressions are stateless and are only evaluated when seen by the aggregation process with one exception: accumulator expressions.
The accumulators, used in the $group stage, maintain their state (e.g. totals, maximums, minimums, and related data) as documents progress through the pipeline.
在 3.2 版更改: Some accumulators are available in the $project stage; however, when used in the $project stage, the accumulators do not maintain their state across documents.
For more information on expressions, see Expressions.
聚合管道的特点¶
在MongoDB中, aggregate 命令会把*整个*集合中的文档传入聚合管道。如有需要,可以使用下面的策略来优化这个操作,避免扫描整个集合。
管道操作符和索引¶
The $match and $sort pipeline operators can take advantage of an index when they occur at the beginning of the pipeline.
在 3.2 版更改: Starting in MongoDB 3.2, indexes can cover an aggregation pipeline. In MongoDB 2.6 and 3.0, indexes could not cover an aggregation pipeline since even when the pipeline uses an index, aggregation still requires access to the actual documents.
预先过滤¶
If your aggregation operation requires only a subset of the data in a collection, use the $match, $limit, and $skip stages to restrict the documents that enter at the beginning of the pipeline. When placed at the beginning of a pipeline, $match operations use suitable indexes to scan only the matching documents in a collection.
Placing a $match pipeline stage followed by a $sort stage at the start of the pipeline is logically equivalent to a single query with a sort and can use an index. When possible, place $match operators at the beginning of the pipeline.
使用 $group 操作符的累计操作,需要在管道处理文档的过程中维护自己的状态(例如总数、最大值、最小值和相关数据)。¶
- MongoDB Analytics: Learn Aggregation by Example: Exploratory Analytics and Visualization Using Flight Data
- MongoDB for Time Series Data: Analyzing Time Series Data Using the Aggregation Framework and Hadoop
即使使用了索引,聚合依然需要访问实际存储的文档;比如索引不能满足聚合管道所需要的所有字段的时候。
在以前的版本中,对每一个选择用例,一个索引可以贯穿整个管道。
- Quick Reference Cards