分片¶
On this page
Sharding is a method for distributing data across multiple machines. MongoDB uses sharding to support deployments with very large data sets and high throughput operations.
Database systems with large data sets or high throughput applications can challenge the capacity of a single server. For example, high query rates can exhaust the CPU capacity of the server. Working set sizes larger than the system’s RAM stress the I/O capacity of disk drives.
There are two methods for addressing system growth: vertical and horizontal scaling.
Vertical Scaling involves increasing the capacity of a single server, such as using a more powerful CPU, adding more RAM, or increasing the amount of storage space. Limitations in available technology may restrict a single machine from being sufficiently powerful for a given workload. Additionally, Cloud-based providers have hard ceilings based on available hardware configurations. As a result, there is a practical maximum for vertical scaling.
Horizontal Scaling involves dividing the system dataset and load over multiple servers, adding additional servers to increase capacity as required. While the overall speed or capacity of a single machine may not be high, each machine handles a subset of the overall workload, potentially providing better efficiency than a single high-speed high-capacity server. Expanding the capacity of the deployment only requires adding additional servers as needed, which can be a lower overall cost than high-end hardware for a single machine. The trade off is increased complexity in infrastructure and maintenance for the deployment.
MongoDB supports horizontal scaling through sharding.
Sharded Cluster¶
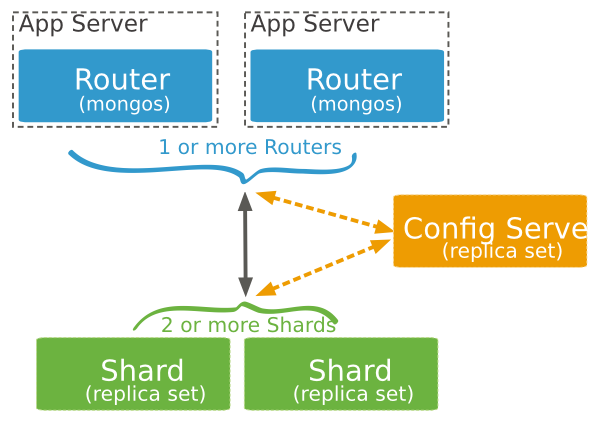
A MongoDB sharded cluster consists of the following components:
- shard: Each shard contains a subset of the sharded data. Each shard can be deployed as a replica set.
- mongos: The mongos acts as a query router, providing an interface between client applications and the sharded cluster.
- config servers: Config servers store metadata and configuration settings for the cluster. As of MongoDB 3.4, config servers must be deployed as a replica set (CSRS).
The following graphic describes the interaction of components within a sharded cluster:
MongoDB shards data at the collection level, distributing the collection data across the shards in the cluster.
Shard Keys¶
To distribute the documents in a collection, MongoDB partitions the collection using the shard key. The shard key consists of an immutable field or fields that exist in every document in the target collection.
You choose the shard key when sharding a collection. The choice of shard key cannot be changed after sharding. A sharded collection can have only one shard key. See Shard Key Specification.
To shard a non-empty collection, the collection must have an index that starts with the shard key. For empty collections, MongoDB creates the index if the collection does not already have an appropriate index for the specified shard key. See Shard Key Indexes.
The choice of shard key affects the performance, efficiency, and scalability of a sharded cluster. A cluster with the best possible hardware and infrastructure can be bottlenecked by the choice of shard key. The choice of shard key and its backing index can also affect the sharding strategy that your cluster can use.
See the shard key documentation for more information.
Chunks¶
MongoDB partitions sharded data into chunks. Each chunk has an inclusive lower and exclusive upper range based on the shard key.
MongoDB migrates chunks across the shards in the sharded cluster using the sharded cluster balancer. The balancer attempts to achieve an even balance of chunks across all shards in the cluster.
See Data Partitioning with Chunks for more information.
Advantages of Sharding¶
Reads / Writes¶
MongoDB distributes the read and write workload across the shards in the sharded cluster, allowing each shard to process a subset of cluster operations. Both read and write workloads can be scaled horizontally across the cluster by adding more shards.
For queries that include the shard key or the prefix of a compound shard key, mongos can target the query at a specific shard or set of shards. These targeted operations are generally more efficient than broadcasting to every shard in the cluster.
Storage Capacity¶
Sharding distributes data across the shards in the cluster, allowing each shard to contain a subset of the total cluster data. As the data set grows, additional shards increase the storage capacity of the cluster.
High Availability¶
A sharded cluster can continue to perform partial read / write operations even if one or more shards are unavailable. While the subset of data on the unavailable shards cannot be accessed during the downtime, reads or writes directed at the available shards can still succeed.
Starting in MongoDB 3.2, you can deploy config servers as replica sets. A sharded cluster with a Config Server Replica Set (CSRS) can continue to process reads and writes as long as a majority of the replica set is available. In version 3.4, MongoDB removes support for SCCC config servers. To upgrade your config servers from SCCC to CSRS, see Upgrade Config Servers to Replica Set.
In production environments, individual shards should be deployed as replica sets, providing increased redundancy and availability.
Considerations Before Sharding¶
论述了集群的操作,包括集群的自动数据均衡和相关的可靠性和安全性的注意事项.
Careful consideration in choosing the shard key is necessary for ensuring cluster performance and efficiency. You cannot change the shard key after sharding, nor can you unshard a sharded collection. See 通常,一个经过计算的片键会有一定的”随机性”,比如一个包含了其他字段加密哈希(例如 MD5或者SHA1)的片键,会使集群具有较好的写扩展性能.不过,随机的片键通常不会提供 查询隔离 的特性,而查询隔离同样是片键一个很重要的特性..
Sharding has certain operational requirements and restrictions. See Operational Restrictions in Sharded Clusters for more information.
If queries do not include the shard key or the prefix of a compound shard key, mongos performs a broadcast operation, querying all shards in the sharded cluster. These scatter/gather queries can be long running operations.
注解
If you have an active support contract with MongoDB, consider contacting your account representative for assistance with sharded cluster planning and deployment.
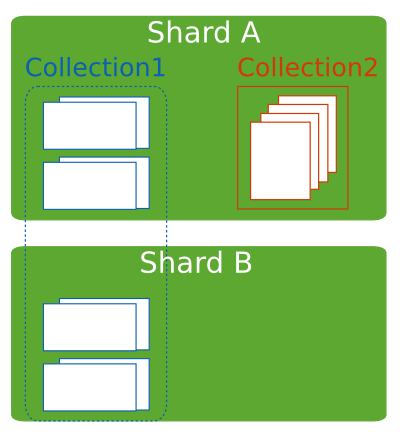
Sharded and Non-Sharded Collections¶
A database can have a mixture of sharded and unsharded collections. Sharded collections are partitioned and distributed across the shards in the cluster. Unsharded collections are stored on a primary shard. Each database has its own primary shard.
Connecting to a Sharded Cluster¶
You must connect to a mongos router to interact with any collection in the sharded cluster. This includes sharded and unsharded collections. Clients should never connect to a single shard in order to perform read or write operations.
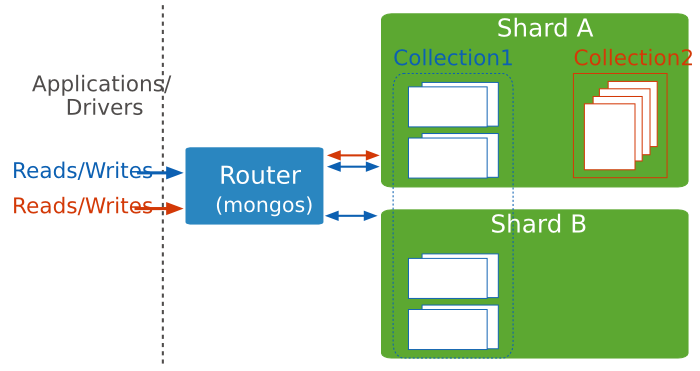
You can connect to a mongos the same way you connect to a mongod, such as via the mongo shell or a MongoDB driver.
Sharding Strategy¶
MongoDB supports two sharding strategies for distributing data across sharded clusters.
Hashed Sharding¶
Hashed Sharding involves computing a hash of the shard key field’s value. Each chunk is then assigned a range based on the hashed shard key values.
Tip
MongoDB automatically computes the hashes when resolving queries using hashed indexes. Applications do not need to compute hashes.
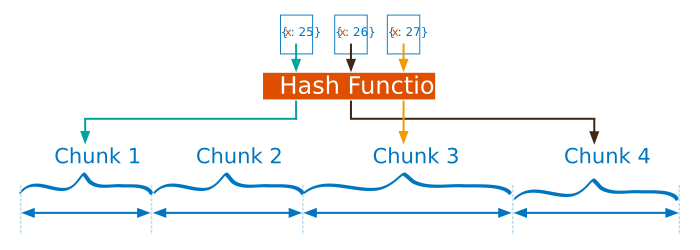
While a range of shard keys may be “close”, their hashed values are unlikely to be on the same chunk. Data distribution based on hashed values facilitates more even data distribution, especially in data sets where the shard key changes monotonically.
However, hashed distribution means that ranged-based queries on the shard key are less likely to target a single shard, resulting in more cluster wide broadcast operations
See Hashed Sharding for more information.
Ranged Sharding¶
Ranged sharding involves dividing data into ranges based on the shard key values. Each chunk is then assigned a range based on the shard key values.
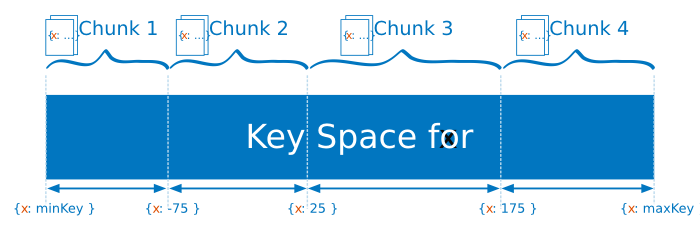
A range of shard keys whose values are “close” are more likely to reside on the same chunk. This allows for targeted operations as a mongos can route the operations to only the shards that contain the required data.
The efficiency of ranged sharding depends on the shard key chosen. Poorly considered shard keys can result in uneven distribution of data, which can negate some benefits of sharding or can cause performance bottlenecks. See shard key selection for ranged sharding.
See Ranged Sharding for more information.
Zones in Sharded Clusters¶
In sharded clusters, you can create zones of sharded data based on the shard key. You can associate each zone with one or more shards in the cluster. A shard can associate with any number of non-conflicting zones. In a balanced cluster, MongoDB migrates chunks covered by a zone only to those shards associated with the zone.
Each zone covers one or more ranges of shard key values. Each range a zone covers is always inclusive of its lower boundary and exclusive of its upper boundary.
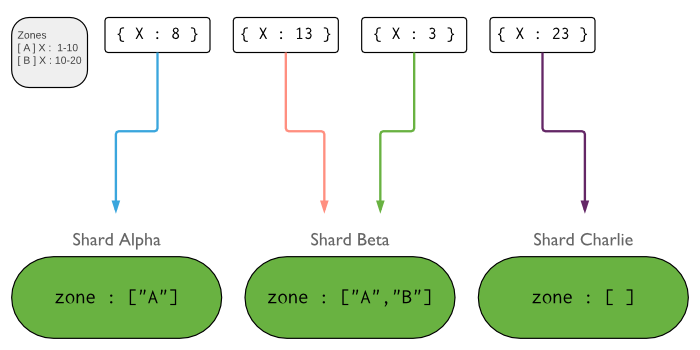
You must use fields contained in the shard key when defining a new range for a zone to cover. If using a compound shard key, the range must include the prefix of the shard key. See shard keys in zones for more information.
When choosing a shard key, carefully consider the possibility of using zone sharding in the future, as you cannot change the shard key after sharding the collection.
Most commonly, zones serve to improve the locality of data for sharded clusters that span multiple data centers.
See zones for more information.
Collations in Sharding¶
Use the shardCollection command with the collation : { locale : "simple" } option to shard a collection which has a default collation. Successful sharding requires that:
- The collection must have an index whose prefix is the shard key
- The index must have the collation { locale: "simple" }
When creating new collections with a collation, ensure these conditions are met prior to sharding the collection.
注解
Queries on the sharded collection continue to use the default collation configured for the collection. To use the shard key index’s simple collation, specify {locale : "simple"} in the query’s collation document.
See shardCollection for more information about sharding and collation.