- 分片 >
- Ranged Sharding
Ranged Sharding¶
Ranged-based sharding involves dividing data into contiguous ranges determined by the shard key values. In this model, documents with “close” shard key values are likely to be in the same chunk or shard. This allows for efficient queries where reads target documents within a contiguous range. However, both read and write performance may decrease with poor shard key selection. See Shard Key Selection.
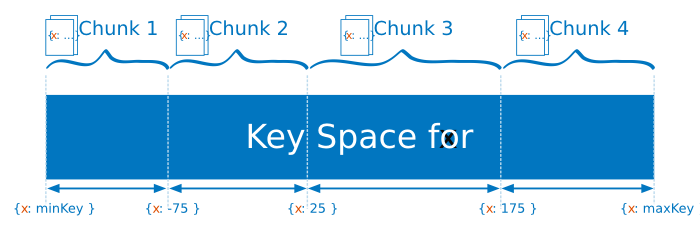
Range-based sharding is the default sharding methodology if no other options such as those required for Hashed Sharding or zones are configured.
Shard Key Selection¶
Ranged sharding is most efficient when the shard key displays the following traits:
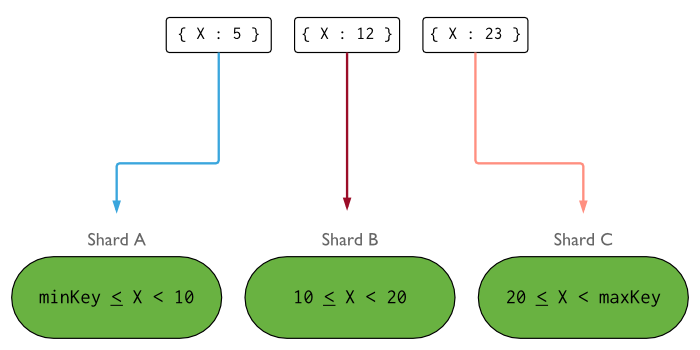
The following image illustrates a sharded cluster using the field X as the shard key. If the values for X show have a large range, low frequency, and change at a non-monotonic rate, the distribution of inserts may look similar to the following:
Shard a Collection¶
Use the sh.shardCollection() method, specifying the full namespace of the collection and the target index or compound index to use as the shard key.
sh.shardCollection( "database.collection", { <shard key> } )