Distributed Local Writes for Insert Only Workloads¶
MongoDB Tag Aware Sharding allows administrators to control data distribution in a sharded cluster by defining ranges of the shard key and tagging them to one or more shards.
This tutorial uses 区域 along with a multi-datacenter sharded cluster deployment and application-side logic to support distributed local writes, as well as high write availability in the event of a replica set election or datacenter failure.
重要
The concepts discussed in this tutorial require a specific deployment architecture, as well as application-level logic.
These concepts require familiarity with MongoDB sharded clusters, replica sets, and the general behavior of zones.
This tutorial assumes an insert-only or insert-intensive workload. The concepts and strategies discussed in this tutorial are not well suited for use cases that require fast reads or updates.
Scenario¶
Consider an insert-intensive application, where reads are infrequent and low priority compared to writes. The application writes documents to a sharded collection, and requires near-constant uptime from the database to support its SLAs or SLOs.
The following represents a partial view of the format of documents the application writes to the database:
{
"_id" : ObjectId("56f08c447fe58b2e96f595fa"),
"message_id" : 329620,
"datacenter" : "alfa",
"userid" : 123,
...
}
{
"_id" : ObjectId("56f08c447fe58b2e96f595fb"),
"message_id" : 578494,
"datacenter" : "bravo",
"userid" : 456,
...
}
{
"_id" : ObjectId("56f08c447fe58b2e96f595fc"),
"message_id" : 689979,
"datacenter" : "bravo",
"userid" : 789,
...
}
Shard Key¶
The collection uses the { datacenter : 1, userid : 1 } compound index as the shard key.
The datacenter field in each document allows for creating a tag range on each distinct datacenter value. Without the datacenter field, it would not be possible to associate a document with a specific datacenter.
The userid field provides a high cardinality and low frequency component to the shard key relative to datacenter.
See Choosing a Shard Key for more general instructions on selecting a shard key.
Architecture¶
The deployment consists of two datacenters, alfa and bravo. There are two shards, shard0000 and shard0001. Each shard is a replica set with three members. shard0000 has two members on alfa and one priority 0 member on bravo. shard0001 has two members on bravo and one priority 0 member on alfa.
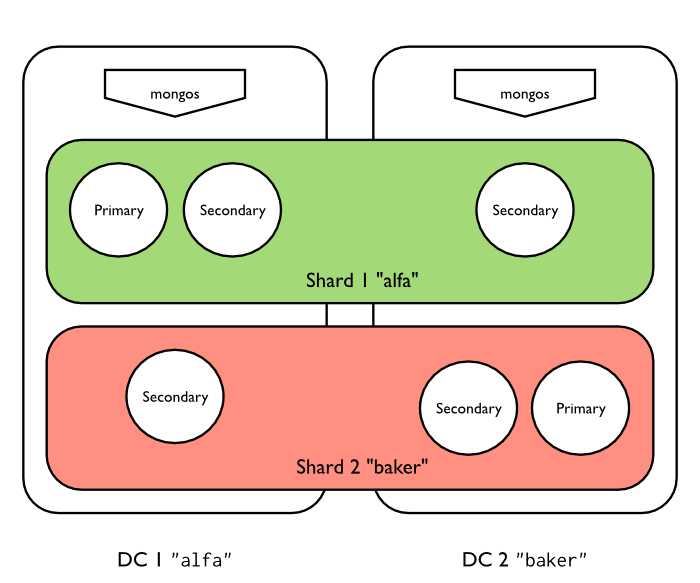
Tags¶
This application requires one tag per datacenter. Each shard has one tag assigned to it based on the datacenter containing the majority of its replica set members. There are two tag ranges, one for each datacenter.
- alfa Datacenter
Tag shards with a majority of members on this datacenter as alfa.
Create a tag range with:
- a lower bound of { "datacenter" : "alfa", "userid" : MinKey },
- an upper bound of { "datacenter" : "alfa", "userid" : MaxKey }, and
- the tag alfa
- bravo Datacenter
Tag shards with a majority of members on this datacenter as bravo.
Create a tag range with:
- a lower bound of { "datacenter" : "bravo", "userid" : MinKey },
- an upper bound of { "datacenter" : "bravo", "userid" : MaxKey }, and
- the tag bravo
注解
The MinKey and MaxKey values are reserved special values for comparisons
Based on the configured tags and tag ranges, mongos routes documents with datacenter : alfa to the alfa datacenter, and documents with datacenter : bravo to the bravo datacenter.
Write Operations¶
If an inserted or updated document matches a configured tag range, it can only be written to a shard with the related tag.
MongoDB can write documents that do not match a configured tag range to any shard in the cluster.
注解
The behavior described above requires the cluster to be in a steady state with no chunks violating a configured tag range. See the following section on the balancer for more information.
Balancer¶
The balancer migrates the tagged chunks to the appropriate shard. Until the migration, shards may contain chunks that violate configured tag ranges and tags. Once balancing completes, shards should only contain chunks whose ranges do not violate its assigned tags and tag ranges.
Adding or removing tags or tag ranges can result in chunk migrations. Depending on the size of your data set and the number of chunks a tag range affects, these migrations may impact cluster performance. Consider running your balancer during specific scheduled windows. See 为均衡窗口设置时间表 for a tutorial on how to set a scheduling window.
Application Behavior¶
By default, the application writes to the nearest datacenter. If the local datacenter is down, or if writes to that datacenter are not acknowledged within a set time period, the application switches to the other available datacenter by changing the value of the datacenter field before attempting to write the document to the database.
The application supports write timeouts. The application uses Write Concern to set a timeout for each write operation.
If the application encounters a write or timeout error, it modifies the datacenter field in each document and performs the write. This routes the document to the other datacenter. If both datacenters are down, then writes cannot succeed. See Resolve Write Failure.
The application periodically checks connectivity to any data centers marked as “down”. If connectivity is restored, the application can continue performing normal write operations.
Given the switching logic, as well as any load balancers or similar mechanisms in place to handle client traffic between datacenters, the application cannot predict which of the two datacenters a given document was written to. To ensure that no documents are missed as a part of read operations, the application must perform broadcast queries by not including the datacenter field as a part of any query.
The application performs reads using a read preference of nearest to reduce latency.
It is possible for a write operation to succeed despite a reported timeout error. The application responds to the error by attempting to re-write the document to the other datacenter - this can result in a document being duplicated across both datacenters. The application resolves duplicates as a part of the read logic.
Switching Logic¶
The application has logic to switch datacenters if one or more writes fail, or if writes are not acknowledged within a set time period. The application modifies the datacenter field based on the target datacenter’s tag to direct the document towards that datacenter.
For example, an application attempting to write to the alfa datacenter might follow this general procedure:
- Attempt to write document, specifying datacenter : alfa.
- On write timeout or error, log alfa as momentarily down.
- Attempt to write same document, modifying datacenter : bravo.
- On write timeout or error, log bravo as momentarily down.
- If both alfa and bravo are down, log and report errors.
Procedure¶
Configure Shard Tags¶
You must be connected to a mongos associated with the target sharded cluster in order to proceed. You cannot create tags by connecting directly to a shard replica set member.
Tag each shard.¶
Tag each shard in the alfa data center with the alfa tag.
sh.addShardTag("shard0000", "alfa")
Tag each shard in the bravo data center with the bravo tag.
sh.addShardTag("shard0001", "bravo")
You can review the tags assigned to any given shard by running sh.status().
Define ranges for each tag.¶
Define the range for the alfa database and associate it to the alfa tag using the sh.addTagRange() method. This method requires:
- The full namespace of the target collection.
- The inclusive lower bound of the range.
- The exclusive upper bound of the range.
- The name of the tag.
sh.addTagRange(
"<database>.<collection>",
{ "datacenter" : "alfa", "userid" : MinKey },
{ "datacenter" : "alfa", "userid" : MaxKey },
"alfa"
)
Define the range for the bravo database and associate it to the bravo tag using the sh.addTagRange() method. This method requires:
- The full namespace of the target collection.
- The inclusive lower bound of the range.
- The exclusive upper bound of the range.
- The name of the tag.
sh.addTagRange(
"<database>.<collection>",
{ "datacenter" : "bravo", "userid" : MinKey },
{ "datacenter" : "bravo", "userid" : MaxKey },
"bravo"
)
The MinKey and MaxKey values are reserved special values for comparisons. MinKey always compares as less than every other possible value, while MaxKey always compares as greater than every other possible value. The configured ranges capture every user for each datacenter.
Review the changes.¶
The next time the balancer runs, it splits and migrates chunks across the shards respecting the tag ranges and tags.
Once balancing finishes, the shards tagged as alfa should only contain documents with datacenter : alfa, while shards tagged as bravo should only contain documents with datacenter : bravo.
You can review the chunk distribution by running sh.status().
Resolve Write Failure¶
When the application’s default datacenter is down or inaccessible, the application changes the datacenter field to the other datacenter.
For example, the application attempts to write the following document to the alfa datacenter by default:
{
"_id" : ObjectId("56f08c447fe58b2e96f595fa"),
"message_id" : 329620,
"datacenter" : "alfa",
"userid" : 123,
...
}
If the application receives an error on attempted write, or if the write acknowledgement takes too long, the application logs the datacenter as unavailable and alters the datacenter field to point to the bravo datacenter.
{
"_id" : ObjectId("56f08c457fe58b2e96f595fb"),
"message_id" : 329620,
"datacenter" : "bravo",
"userid" : 123,
...
}
The application periodically checks the alfa datacenter for connectivity. If the datacenter is reachable again, the application can resume normal writes.
注解
It is possible that the original write to datacenter : alfa succeeded, especially if the error was related to a timeout. If so, the document with message_id : 329620 may now be duplicated across both datacenters. Applications must resolve duplicates as a part of read operations.
Resolve Duplicate Documents on Reads¶
The application’s switching logic allows for potential document duplication. When performing reads, the application resolves any duplicate documents on the application layer.
The following query searches for documents where the userid is 123. Note that while userid is part of the shard key, the query does not include the datacenter field, and therefore does not perform a targeted read operation.
db.collection.find( { "userid" : 123 } )
The results show that the document with message_id of 329620 has been inserted into MongoDB twice, probably as a result of a delayed write acknowledgement.
{
"_id" : ObjectId("56f08c447fe58b2e96f595fa"),
"message_id" : 329620
"datacenter" : "alfa",
"userid" : 123,
data : {...}
}
{
"_id" : ObjectId("56f08c457fe58b2e96f595fb"),
"message_id" : 329620
"datacenter" : "bravo",
"userid" : 123,
...
}
The application can either ignore the duplicates, taking one of the two documents, or it can attempt to trim the duplicates until only a single document remains.
One method for trimming duplicates is to use the ObjectId.getTimestamp() method to extract the timestamp from the _id field. The application can then keep either the first document inserted, or the last document inserted. This assumes the _id field uses the MongoDB ObjectId.
For example, using getTimestamp() on the document with ObjectId("56f08c447fe58b2e96f595fa") returns:
ISODate("2016-03-22T00:05:24Z")
Using getTimestamp() on the document with ObjectId("56f08c457fe58b2e96f595fb") returns:
ISODate("2016-03-22T00:05:25Z")